 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-LLM Collaborative Feature Engineering for Tabular Data
Jan 28, 2026Large language models (LLMs) are increasingly used to automate feature engineering in tabular learning. Given task-specific information, LLMs can propose diverse feature transformation operations to enhance downstream model performance. However, current approaches typically assign the LLM as a black-box optimizer, responsible for both proposing and selecting operations based solely on its internal heuristics, which often lack calibrated estimations of operation utility and consequently lead to repeated exploration of low-yield operations without a principled strategy for prioritizing promising directions. In this paper, we propose a human-LLM collaborative feature engineering framework for tabular learning. We begin by decoupling the transformation operation proposal and selection processes, where LLMs are used solely to generate operation candidates, while the selection is guided by explicitly modeling the utility and uncertainty of each proposed operation. Since accurate utility estimation can be difficult especially in the early rounds of feature engineering, we design a mechanism within the framework that selectively elicits and incorporates human expert preference feedback, comparing which operations are more promising, into the selection process to help identify more effective operations. Our evaluations on both the synthetic study and the real user study demonstrate that the proposed framework improves feature engineering performance across a variety of tabular datasets and reduces users' cognitive load during the feature engineering process.
Navigating the Reality Gap: Privacy-Preserving Adaptation of ASR for Challenging Low-Resource Domains
Dec 22, 2025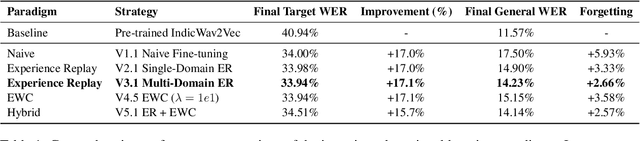
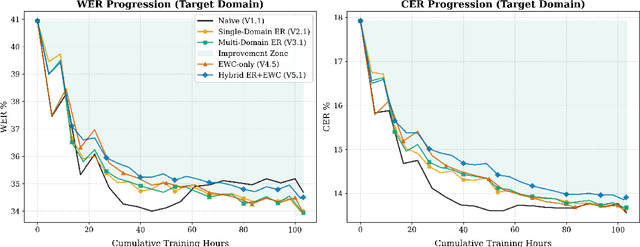
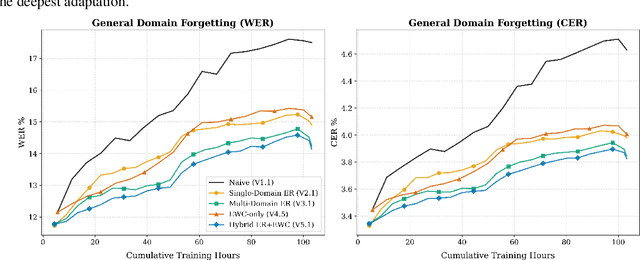

Automatic Speech Recognition (ASR) holds immense potential to assist in clinical documentation and patient report generation, particularly in resource-constrained regions. However, deployment is currently hindered by a technical deadlock: a severe "Reality Gap" between laboratory performance and noisy, real-world clinical audio, coupled with strict privacy and resource constraints. We quantify this gap, showing that a robust multilingual model (IndicWav2Vec) degrades to a 40.94% WER on rural clinical data from India, rendering it unusable. To address this, we explore a zero-data-exfiltration framework enabling localized, continual adaptation via Low-Rank Adaptation (LoRA). We conduct a rigorous investigative study of continual learning strategies, characterizing the trade-offs between data-driven and parameter-driven stability. Our results demonstrate that multi-domain Experience Replay (ER) yields the primary performance gains, achieving a 17.1% relative improvement in target WER and reducing catastrophic forgetting by 55% compared to naive adaptation. Furthermore, we observed that standard Elastic Weight Consolidation (EWC) faced numerical stability challenges when applied to LoRA in noisy environments. Our experiments show that a stabilized, linearized formulation effectively controls gradient magnitudes and enables stable convergence. Finally, we verify via a domain-specific spot check that acoustic adaptation is a fundamental prerequisite for usability which cannot be bypassed by language models alone.
Compressing VAE-Based Out-of-Distribution Detectors for Embedded Deployment
Sep 02, 2024
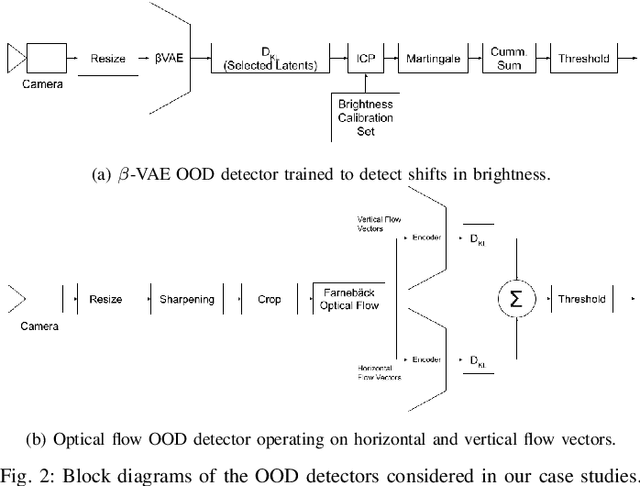

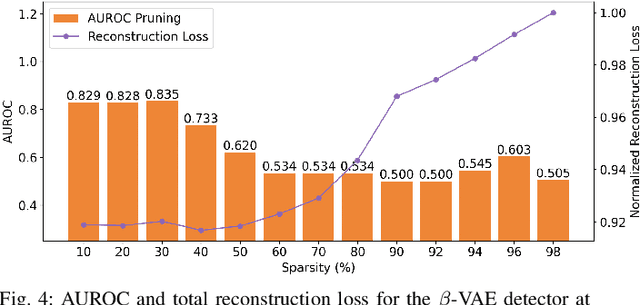
Out-of-distribution (OOD) detectors can act as safety monitors in embedded cyber-physical systems by identifying samples outside a machine learning model's training distribution to prevent potentially unsafe actions. However, OOD detectors are often implemented using deep neural networks, which makes it difficult to meet real-time deadlines on embedded systems with memory and power constraints. We consider the class of variational autoencoder (VAE) based OOD detectors where OOD detection is performed in latent space, and apply quantization, pruning, and knowledge distillation. These techniques have been explored for other deep models, but no work has considered their combined effect on latent space OOD detection. While these techniques increase the VAE's test loss, this does not correspond to a proportional decrease in OOD detection performance and we leverage this to develop lean OOD detectors capable of real-time inference on embedded CPUs and GPUs. We propose a design methodology that combines all three compression techniques and yields a significant decrease in memory and execution time while maintaining AUROC for a given OOD detector. We demonstrate this methodology with two existing OOD detectors on a Jetson Nano and reduce GPU and CPU inference time by 20% and 28% respectively while keeping AUROC within 5% of the baseline.