 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMTalker: Multiresolution 3D Talking Head Synthesis with Multimodal Feature Fusion
Apr 03, 2026Speech-driven three-dimensional (3D) facial animation synthesis aims to build a mapping from one-dimensional (1D) speech signals to time-varying 3D facial motion signals. Current methods still face challenges in maintaining lip-sync accuracy and producing realistic facial expressions, primarily due to the highly ill-posed nature of this cross-modal mapping. In this paper, we introduce a novel 3D audio-driven facial animation synthesis method through multi-resolution representation and multi-modal feature fusion, called MMTalker which can accurately reconstruct the rich details of 3D facial motion. We first achieve the continuous representation of 3D face with details by mesh parameterization and non-uniform differentiable sampling. The mesh parameterization technique establishes the correspondence between UV plane and 3D facial mesh and is used to offer ground truth for the continuous learning. Differentiable non-uniform sampling enables precise facial detail acquisition by setting learnable sampling probability in each triangular face. Next, we employ residual graph convolutional network and dual cross-attention mechanism to extract discriminative facial motion feature from multiple input modalities. This proposed multimodal fusion strategy takes full use of the hierarchical features of speech and the explicit spatiotemporal geometric features of facial mesh. Finally, a lightweight regression network predicts the vertex-wise geometric displacements of the synthesized talking face by jointly processing the sampled points in the canonical UV space and the encoded facial motion features. Comprehensive experiments demonstrate that significant improvements are achieved over state-of-the-art methods, especially in the synchronization accuracy of lip and eye movements.
AI for Mycetoma Diagnosis in Histopathological Images: The MICCAI 2024 Challenge
Dec 25, 2025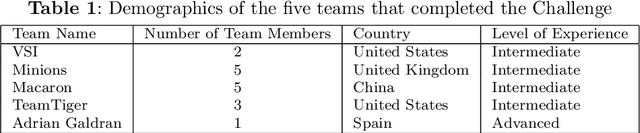
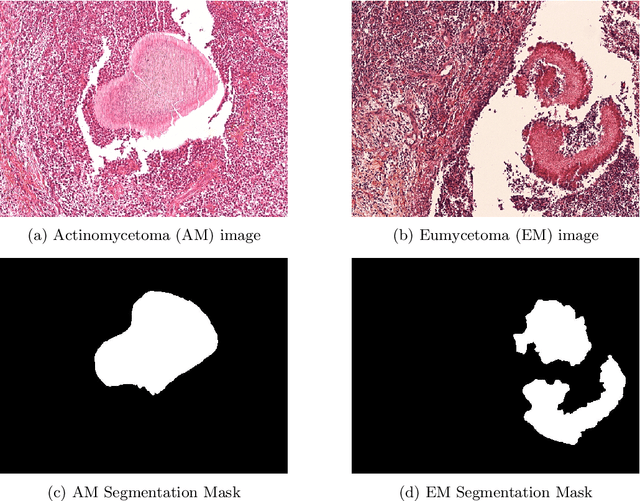
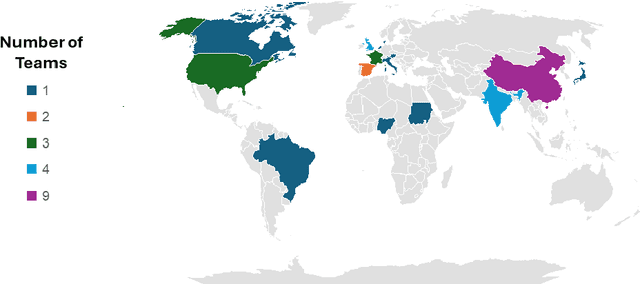

Mycetoma is a neglected tropical disease caused by fungi or bacteria leading to severe tissue damage and disabilities. It affects poor and rural communities and presents medical challenges and socioeconomic burdens on patients and healthcare systems in endemic regions worldwide. Mycetoma diagnosis is a major challenge in mycetoma management, particularly in low-resource settings where expert pathologists are limited. To address this challenge, this paper presents an overview of the Mycetoma MicroImage: Detect and Classify Challenge (mAIcetoma) which was organized to advance mycetoma diagnosis through AI solutions. mAIcetoma focused on developing automated models for segmenting mycetoma grains and classifying mycetoma types from histopathological images. The challenge attracted the attention of several teams worldwide to participate and five finalist teams fulfilled the challenge objectives. The teams proposed various deep learning architectures for the ultimate goal of this challenge. Mycetoma database (MyData) was provided to participants as a standardized dataset to run the proposed models. Those models were evaluated using evaluation metrics. Results showed that all the models achieved high segmentation accuracy, emphasizing the necessitate of grain detection as a critical step in mycetoma diagnosis. In addition, the top-performing models show a significant performance in classifying mycetoma types.
LightHuBERT: Lightweight and Configurable Speech Representation Learning with Once-for-All Hidden-Unit BERT
Mar 29, 2022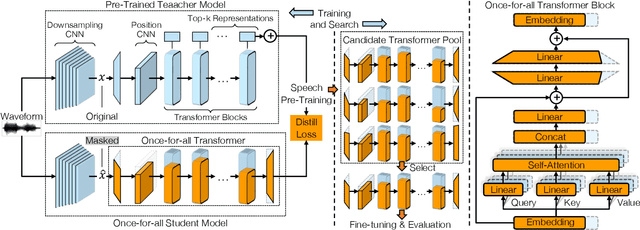


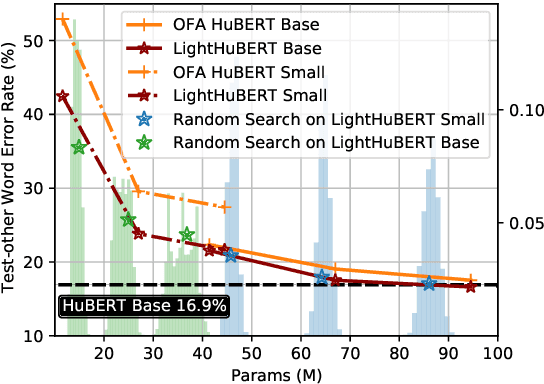
Self-supervised speech representation learning has shown promising results in various speech processing tasks. However, the pre-trained models, e.g., HuBERT, are storage-intensive Transformers, limiting their scope of applications under low-resource settings. To this end, we propose LightHuBERT, a once-for-all Transformer compression framework, to find the desired architectures automatically by pruning structured parameters. More precisely, we create a Transformer-based supernet that is nested with thousands of weight-sharing subnets and design a two-stage distillation strategy to leverage the contextualized latent representations from HuBERT. Experiments on automatic speech recognition (ASR) and the SUPERB benchmark show the proposed LightHuBERT enables over $10^9$ architectures concerning the embedding dimension, attention dimension, head number, feed-forward network ratio, and network depth. LightHuBERT outperforms the original HuBERT on ASR and five SUPERB tasks with the HuBERT size, achieves comparable performance to the teacher model in most tasks with a reduction of 29% parameters, and obtains a $3.5\times$ compression ratio in three SUPERB tasks, e.g., automatic speaker verification, keyword spotting, and intent classification, with a slight accuracy loss. The code and pre-trained models are available at https://github.com/mechanicalsea/lighthubert.