 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocomotion Beyond Feet
Jan 07, 2026Most locomotion methods for humanoid robots focus on leg-based gaits, yet natural bipeds frequently rely on hands, knees, and elbows to establish additional contacts for stability and support in complex environments. This paper introduces Locomotion Beyond Feet, a comprehensive system for whole-body humanoid locomotion across extremely challenging terrains, including low-clearance spaces under chairs, knee-high walls, knee-high platforms, and steep ascending and descending stairs. Our approach addresses two key challenges: contact-rich motion planning and generalization across diverse terrains. To this end, we combine physics-grounded keyframe animation with reinforcement learning. Keyframes encode human knowledge of motor skills, are embodiment-specific, and can be readily validated in simulation or on hardware, while reinforcement learning transforms these references into robust, physically accurate motions. We further employ a hierarchical framework consisting of terrain-specific motion-tracking policies, failure recovery mechanisms, and a vision-based skill planner. Real-world experiments demonstrate that Locomotion Beyond Feet achieves robust whole-body locomotion and generalizes across obstacle sizes, obstacle instances, and terrain sequences.
Deep Joint Source-Channel Coding for Multi-Task Network
Sep 27, 2021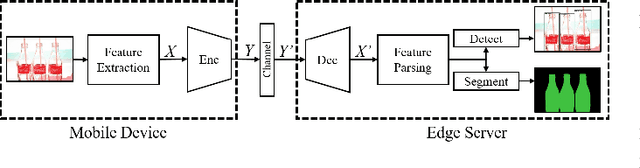
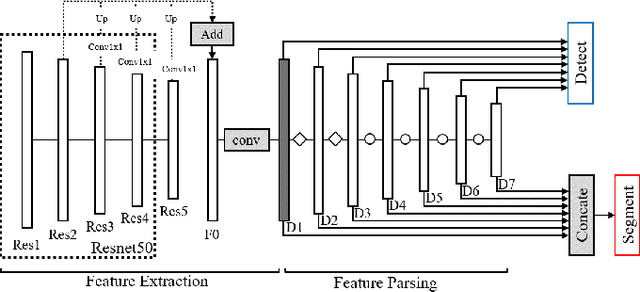
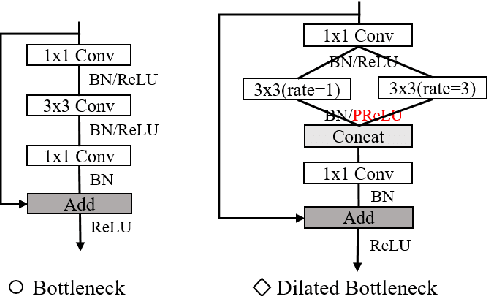

Multi-task learning (MTL) is an efficient way to improve the performance of related tasks by sharing knowledge. However, most existing MTL networks run on a single end and are not suitable for collaborative intelligence (CI) scenarios. In this work, we propose an MTL network with a deep joint source-channel coding (JSCC) framework, which allows operating under CI scenarios. We first propose a feature fusion based MTL network (FFMNet) for joint object detection and semantic segmentation. Compared with other MTL networks, FFMNet gets higher performance with fewer parameters. Then FFMNet is split into two parts, which run on a mobile device and an edge server respectively. The feature generated by the mobile device is transmitted through the wireless channel to the edge server. To reduce the transmission overhead of the intermediate feature, a deep JSCC network is designed. By combining two networks together, the whole model achieves 512x compression for the intermediate feature and a performance loss within 2% on both tasks. At last, by training with noise, the FFMNet with JSCC is robust to various channel conditions and outperforms the separate source and channel coding scheme.