 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecureSplit: Mitigating Backdoor Attacks in Split Learning
Jan 20, 2026Split Learning (SL) offers a framework for collaborative model training that respects data privacy by allowing participants to share the same dataset while maintaining distinct feature sets. However, SL is susceptible to backdoor attacks, in which malicious clients subtly alter their embeddings to insert hidden triggers that compromise the final trained model. To address this vulnerability, we introduce SecureSplit, a defense mechanism tailored to SL. SecureSplit applies a dimensionality transformation strategy to accentuate subtle differences between benign and poisoned embeddings, facilitating their separation. With this enhanced distinction, we develop an adaptive filtering approach that uses a majority-based voting scheme to remove contaminated embeddings while preserving clean ones. Rigorous experiments across four datasets (CIFAR-10, MNIST, CINIC-10, and ImageNette), five backdoor attack scenarios, and seven alternative defenses confirm the effectiveness of SecureSplit under various challenging conditions.
PINN and GNN-based RF Map Construction for Wireless Communication Systems
Jul 30, 2025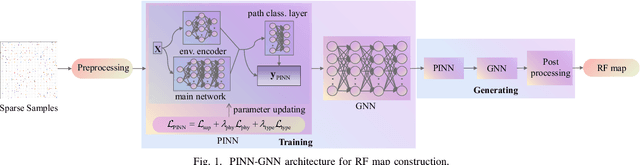
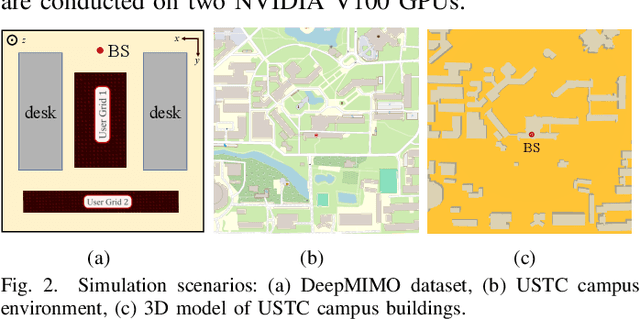
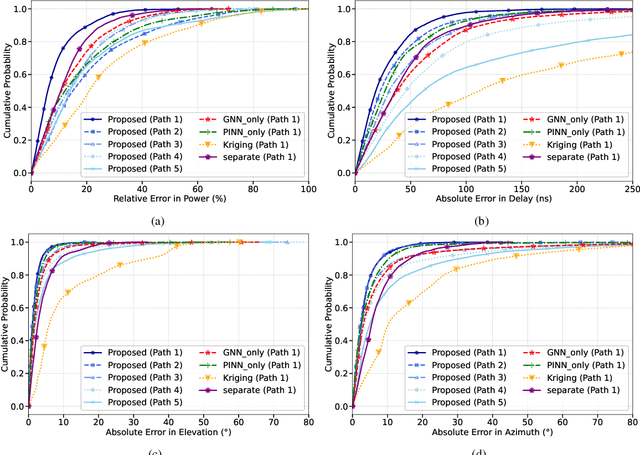
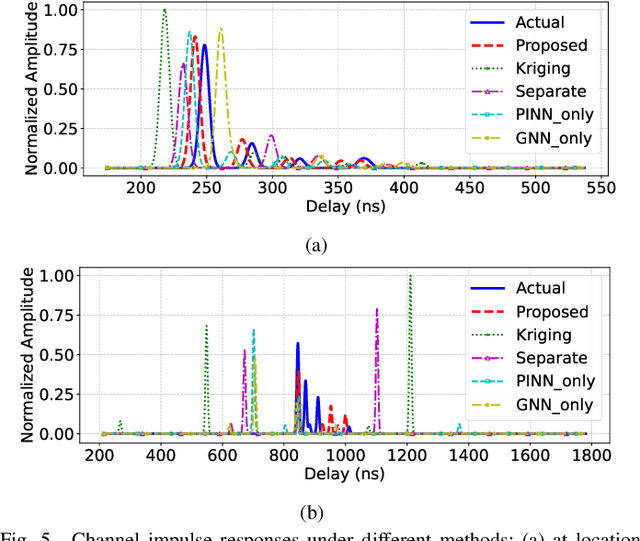
Radio frequency (RF) map is a promising technique for capturing the characteristics of multipath signal propagation, offering critical support for channel modeling, coverage analysis, and beamforming in wireless communication networks. This paper proposes a novel RF map construction method based on a combination of physics-informed neural network (PINN) and graph neural network (GNN). The PINN incorporates physical constraints derived from electromagnetic propagation laws to guide the learning process, while the GNN models spatial correlations among receiver locations. By parameterizing multipath signals into received power, delay, and angle of arrival (AoA), and integrating both physical priors and spatial dependencies, the proposed method achieves accurate prediction of multipath parameters. Experimental results demonstrate that the method enables high-precision RF map construction under sparse sampling conditions and delivers robust performance in both indoor and complex outdoor environments, outperforming baseline methods in terms of generalization and accuracy.
Spiking Semantic Communication for Feature Transmission with HARQ
Oct 13, 2023



In Collaborative Intelligence (CI), the Artificial Intelligence (AI) model is divided between the edge and the cloud, with intermediate features being sent from the edge to the cloud for inference. Several deep learning-based Semantic Communication (SC) models have been proposed to reduce feature transmission overhead and mitigate channel noise interference. Previous research has demonstrated that Spiking Neural Network (SNN)-based SC models exhibit greater robustness on digital channels compared to Deep Neural Network (DNN)-based SC models. However, the existing SNN-based SC models require fixed time steps, resulting in fixed transmission bandwidths that cannot be adaptively adjusted based on channel conditions. To address this issue, this paper introduces a novel SC model called SNN-SC-HARQ, which combines the SNN-based SC model with the Hybrid Automatic Repeat Request (HARQ) mechanism. SNN-SC-HARQ comprises an SNN-based SC model that supports the transmission of features at varying bandwidths, along with a policy model that determines the appropriate bandwidth. Experimental results show that SNN-SC-HARQ can dynamically adjust the bandwidth according to the channel conditions without performance loss.
S-JSCC: A Digital Joint Source-Channel Coding Framework based on Spiking Neural Network
Oct 13, 2022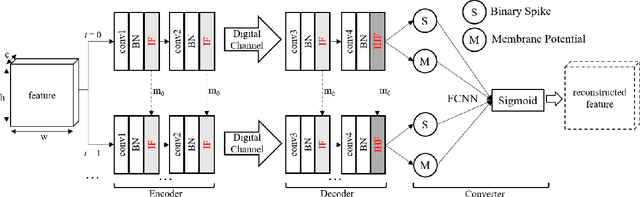
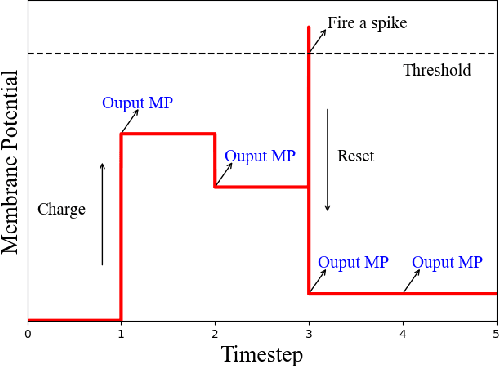
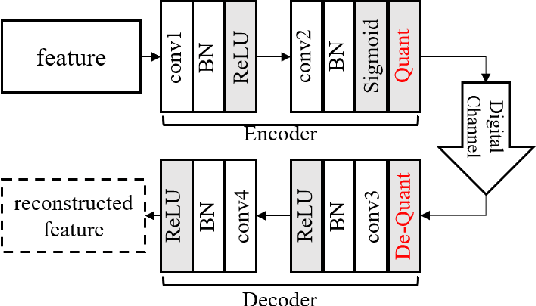
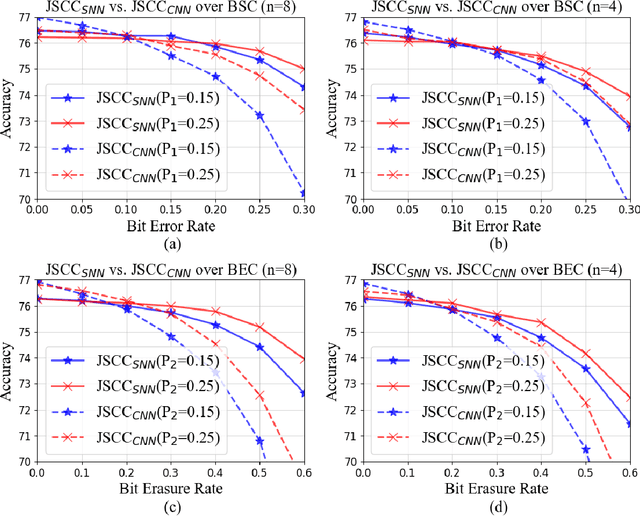
Nowadays, deep learning-based joint source-channel coding (JSCC) is getting attention, and it shows excellent performance compared with separate source and channel coding (SSCC). However, most JSCC works are only designed, trained, and tested on additive white Gaussian noise (AWGN) channels to transmit analog signals. In current communication systems, digital signals are considered more. Hence, it is necessary to design an end-to-end JSCC framework for digital signal transmission. In this paper, we propose a digital JSCC framework (S-JSCC) based on spiking neural network (SNN) to tackle this problem. The SNN is used to compress the feature of the deep model, and the compressed results are transmitted over digital channels such as binary symmetric channel (BSC) and binary erasure channel (BEC). Since the outputs of SNN are binary spikes, the framework can be applied directly to digital channels without extra quantization. Moreover, we propose a new spiking neuron and regularization method to improve the performance and robustness of the system. The experimental results show that under digital channels, the proposed S-JSCC framework performs better than the state-of-the-art convolution neural network (CNN)-based JSCC framework, which needs extra quantization.
Constellation Design for Deep Joint Source-Channel Coding
Jun 08, 2022
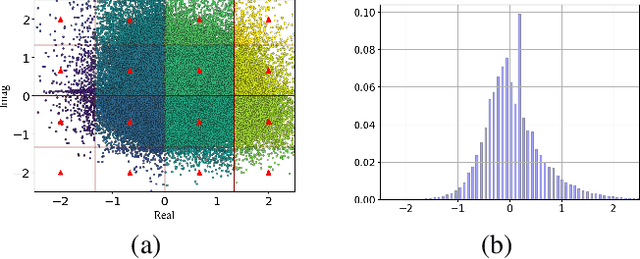

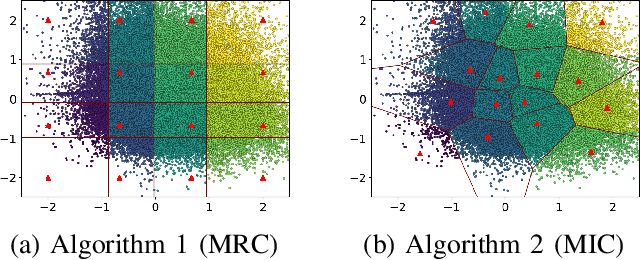
Deep learning-based joint source-channel coding (JSCC) has shown excellent performance in image and feature transmission. However, the output values of the JSCC encoder are continuous, which makes the constellation of modulation complex and dense. It is hard and expensive to design radio frequency chains for transmitting such full-resolution constellation points. In this paper, two methods of mapping the full-resolution constellation to finite constellation are proposed for real system implementation. The constellation mapping results of the proposed methods correspond to regular constellation and irregular constellation, respectively. We apply the methods to existing deep JSCC models and evaluate them on AWGN channels with different signal-to-noise ratios (SNRs). Experimental results show that the proposed methods outperform the traditional uniform quadrature amplitude modulation (QAM) constellation mapping method by only adding a few additional parameters.
Deep Joint Source-Channel Coding for Multi-Task Network
Sep 27, 2021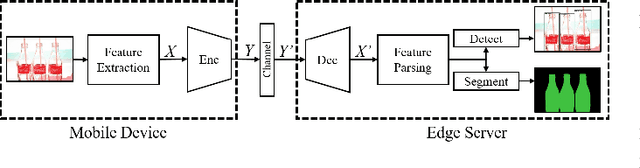
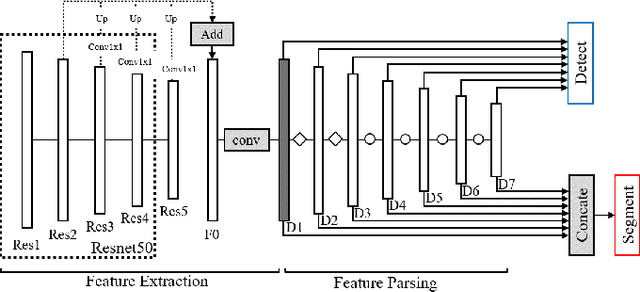
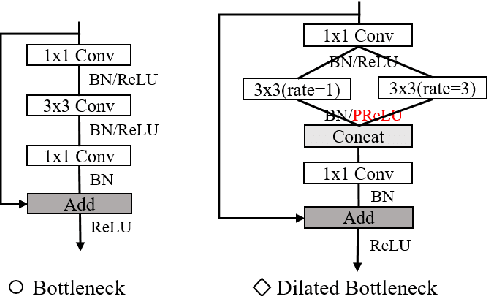

Multi-task learning (MTL) is an efficient way to improve the performance of related tasks by sharing knowledge. However, most existing MTL networks run on a single end and are not suitable for collaborative intelligence (CI) scenarios. In this work, we propose an MTL network with a deep joint source-channel coding (JSCC) framework, which allows operating under CI scenarios. We first propose a feature fusion based MTL network (FFMNet) for joint object detection and semantic segmentation. Compared with other MTL networks, FFMNet gets higher performance with fewer parameters. Then FFMNet is split into two parts, which run on a mobile device and an edge server respectively. The feature generated by the mobile device is transmitted through the wireless channel to the edge server. To reduce the transmission overhead of the intermediate feature, a deep JSCC network is designed. By combining two networks together, the whole model achieves 512x compression for the intermediate feature and a performance loss within 2% on both tasks. At last, by training with noise, the FFMNet with JSCC is robust to various channel conditions and outperforms the separate source and channel coding scheme.
SNR-adaptive deep joint source-channel coding for wireless image transmission
Feb 02, 2021
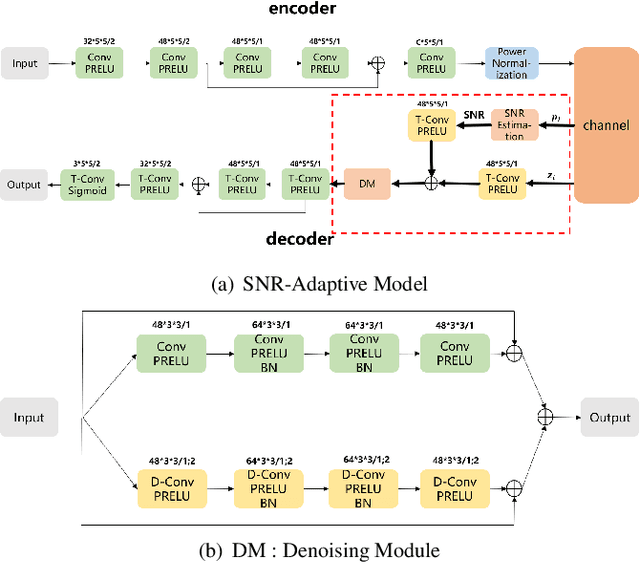
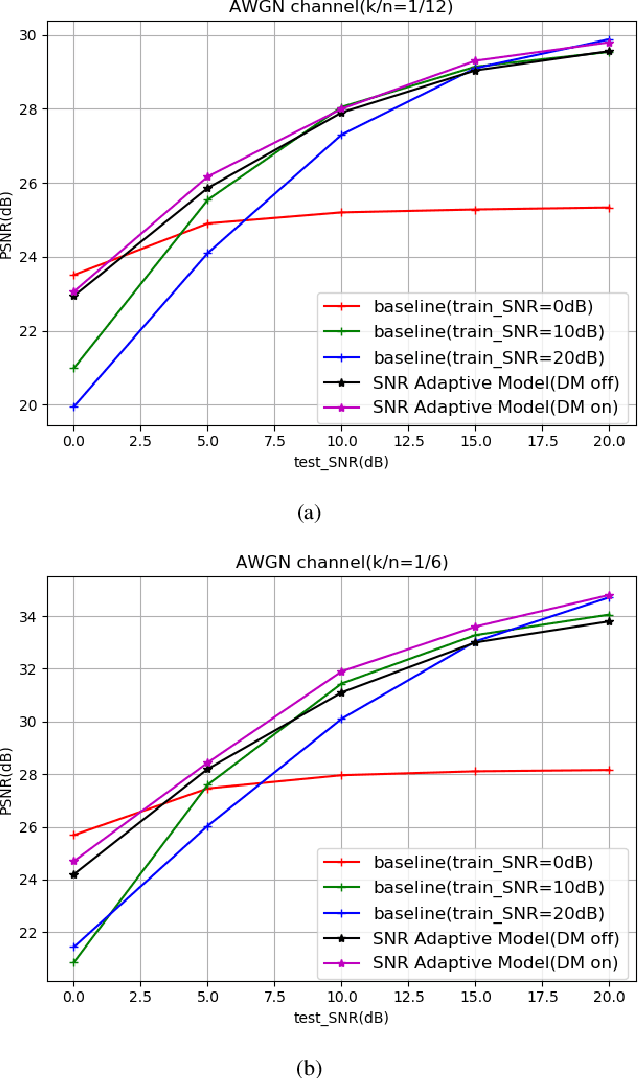

Considering the problem of joint source-channel coding (JSCC) for multi-user transmission of images over noisy channels, an autoencoder-based novel deep joint source-channel coding scheme is proposed in this paper. In the proposed JSCC scheme, the decoder can estimate the signal-to-noise ratio (SNR) and use it to adaptively decode the transmitted image. Experiments demonstrate that the proposed scheme achieves impressive results in adaptability for different SNRs and is robust to the decoder's estimation error of the SNR. To the best of our knowledge, this is the first deep JSCC scheme that focuses on the adaptability for different SNRs and can be applied to multi-user scenarios.