 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Vehicle Routing Problems with Soft Time Windows: A Multi-Agent Reinforcement Learning Approach
Feb 13, 2020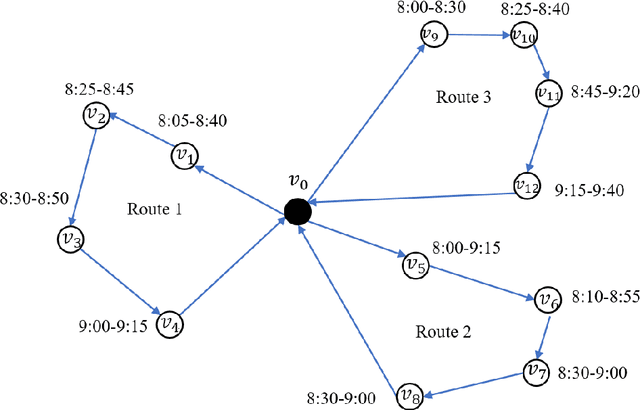
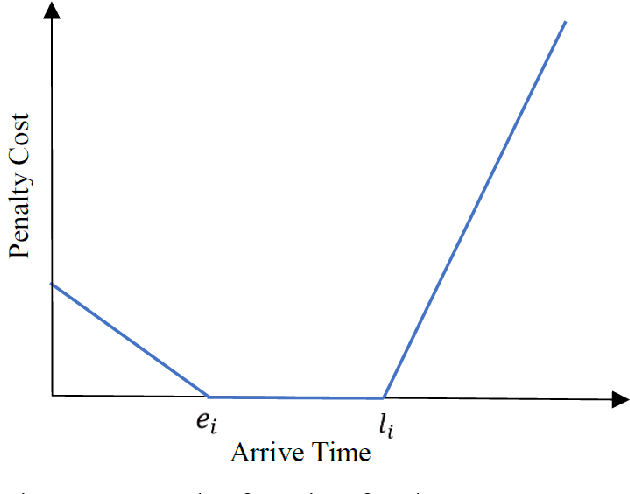
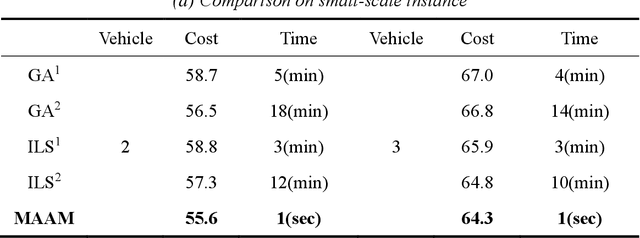
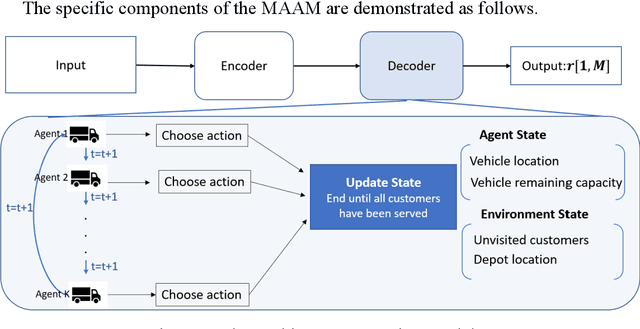
Multi-vehicle routing problem with soft time windows (MVRPSTW) is an indispensable constituent in urban logistics distribution system. In the last decade, numerous methods for MVRPSTW have sprung up, but most of them are based on heuristic rules which require huge computation time. With the rapid increasing of logistics demand, traditional methods incur the dilemma of computation efficiency. To efficiently solve the problem, we propose a novel reinforcement learning algorithm named Multi-Agent Attention Model in this paper. Specifically, the vehicle routing problem is regarded as a vehicle tour generation process, and an encoder-decoder framework with attention layers is proposed to generate tours of multiple vehicles iteratively. Furthermore, a multi-agent reinforcement learning method with an unsupervised auxiliary network is developed for model training. By evaluated on three synthetic networks with different scale, the results demonstrate that the proposed method consistently outperforms traditional methods with little computation time. In addition, we validate the extensibility of the well-trained model by varying the number of customers and capacity of vehicles. Finally, the impact of parameters settings on the algorithmic performance are investigated.
Learning Agent Communication under Limited Bandwidth by Message Pruning
Dec 03, 2019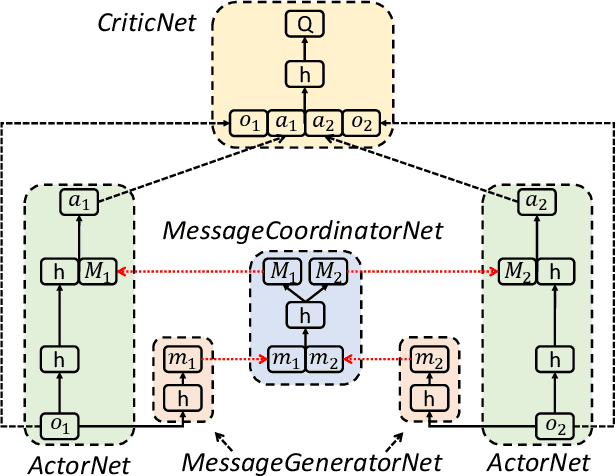
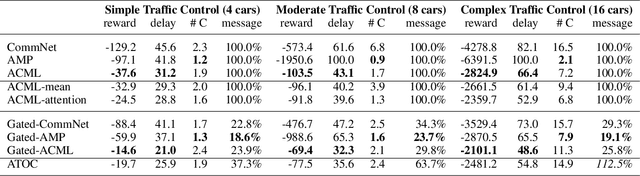
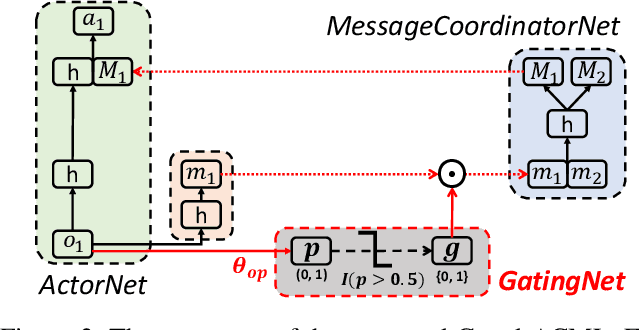
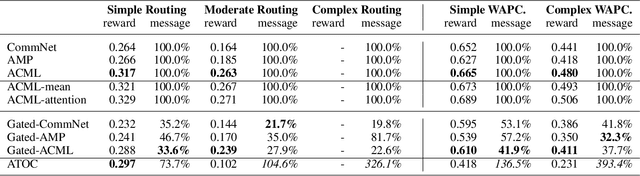
Communication is a crucial factor for the big multi-agent world to stay organized and productive. Recently, Deep Reinforcement Learning (DRL) has been applied to learn the communication strategy and the control policy for multiple agents. However, the practical \emph{\textbf{limited bandwidth}} in multi-agent communication has been largely ignored by the existing DRL methods. Specifically, many methods keep sending messages incessantly, which consumes too much bandwidth. As a result, they are inapplicable to multi-agent systems with limited bandwidth. To handle this problem, we propose a gating mechanism to adaptively prune less beneficial messages. We evaluate the gating mechanism on several tasks. Experiments demonstrate that it can prune a lot of messages with little impact on performance. In fact, the performance may be greatly improved by pruning redundant messages. Moreover, the proposed gating mechanism is applicable to several previous methods, equipping them the ability to address bandwidth restricted settings.
Neighborhood Cognition Consistent Multi-Agent Reinforcement Learning
Dec 03, 2019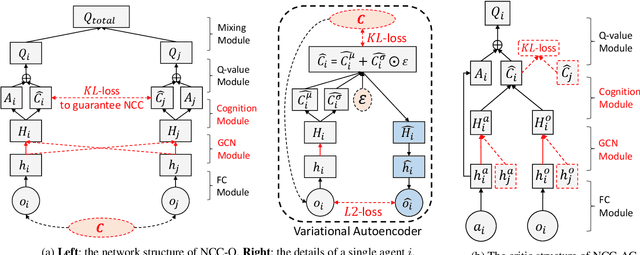
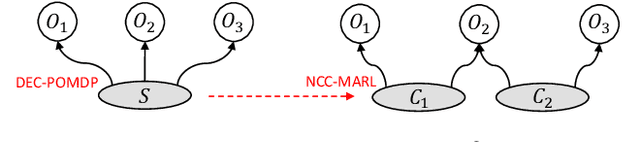
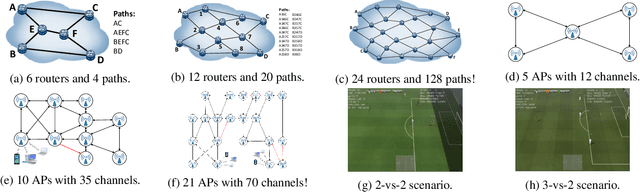
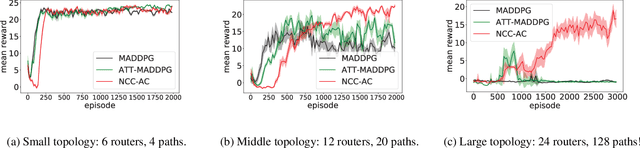
Social psychology and real experiences show that cognitive consistency plays an important role to keep human society in order: if people have a more consistent cognition about their environments, they are more likely to achieve better cooperation. Meanwhile, only cognitive consistency within a neighborhood matters because humans only interact directly with their neighbors. Inspired by these observations, we take the first step to introduce \emph{neighborhood cognitive consistency} (NCC) into multi-agent reinforcement learning (MARL). Our NCC design is quite general and can be easily combined with existing MARL methods. As examples, we propose neighborhood cognition consistent deep Q-learning and Actor-Critic to facilitate large-scale multi-agent cooperations. Extensive experiments on several challenging tasks (i.e., packet routing, wifi configuration, and Google football player control) justify the superior performance of our methods compared with state-of-the-art MARL approaches.
Learning Multi-agent Communication under Limited-bandwidth Restriction for Internet Packet Routing
Feb 26, 2019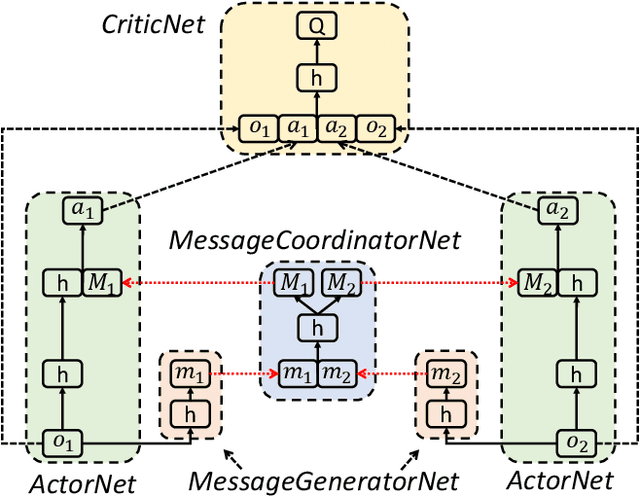
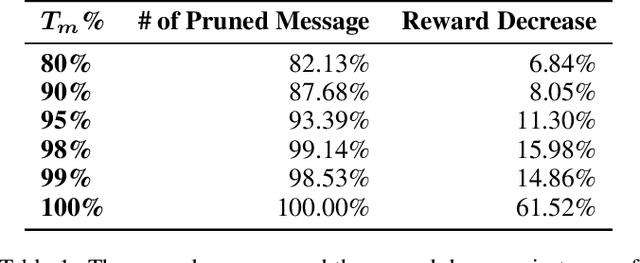
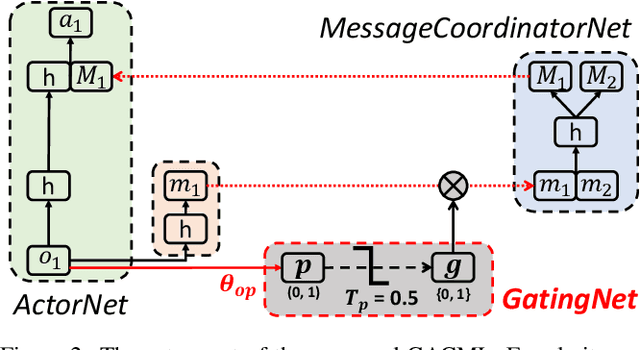
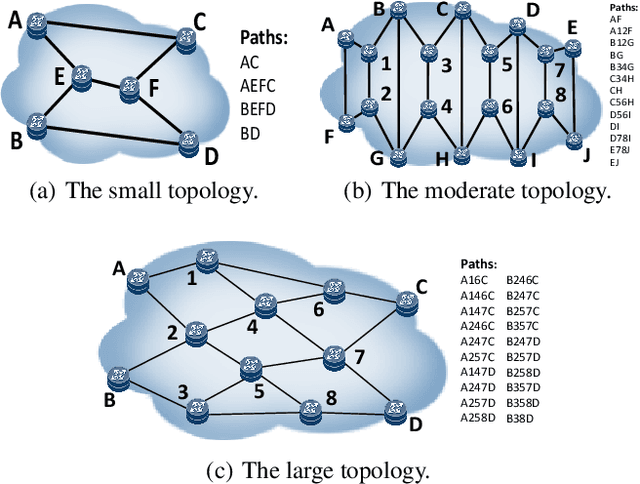
Communication is an important factor for the big multi-agent world to stay organized and productive. Recently, the AI community has applied the Deep Reinforcement Learning (DRL) to learn the communication strategy and the control policy for multiple agents. However, when implementing the communication for real-world multi-agent applications, there is a more practical limited-bandwidth restriction, which has been largely ignored by the existing DRL-based methods. Specifically, agents trained by most previous methods keep sending messages incessantly in every control cycle; due to emitting too many messages, these methods are unsuitable to be applied to the real-world systems that have a limited bandwidth to transmit the messages. To handle this problem, we propose a gating mechanism to adaptively prune unprofitable messages. Results show that the gating mechanism can prune more than 80% messages with little damage to the performance. Moreover, our method outperforms several state-of-the-art DRL-based and rule-based methods by a large margin in both the real-world packet routing tasks and four benchmark tasks.
Modelling the Dynamic Joint Policy of Teammates with Attention Multi-agent DDPG
Nov 13, 2018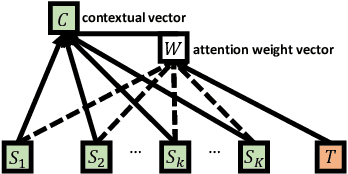
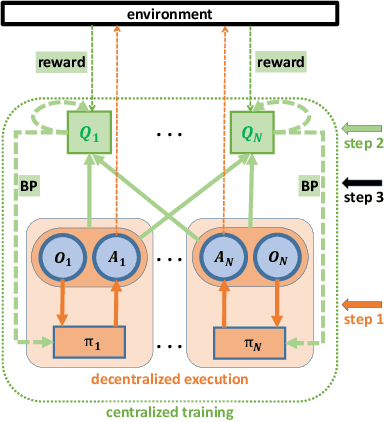
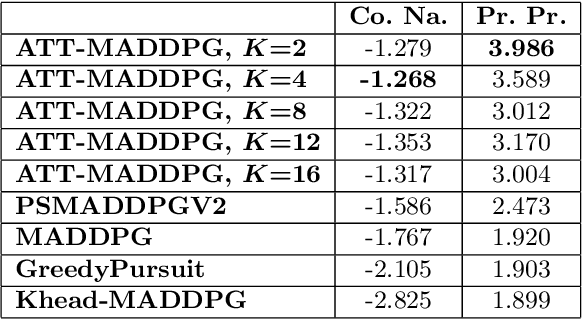
Modelling and exploiting teammates' policies in cooperative multi-agent systems have long been an interest and also a big challenge for the reinforcement learning (RL) community. The interest lies in the fact that if the agent knows the teammates' policies, it can adjust its own policy accordingly to arrive at proper cooperations; while the challenge is that the agents' policies are changing continuously due to they are learning concurrently, which imposes difficulty to model the dynamic policies of teammates accurately. In this paper, we present \emph{ATTention Multi-Agent Deep Deterministic Policy Gradient} (ATT-MADDPG) to address this challenge. ATT-MADDPG extends DDPG, a single-agent actor-critic RL method, with two special designs. First, in order to model the teammates' policies, the agent should get access to the observations and actions of teammates. ATT-MADDPG adopts a centralized critic to collect such information. Second, to model the teammates' policies using the collected information in an effective way, ATT-MADDPG enhances the centralized critic with an attention mechanism. This attention mechanism introduces a special structure to explicitly model the dynamic joint policy of teammates, making sure that the collected information can be processed efficiently. We evaluate ATT-MADDPG on both benchmark tasks and the real-world packet routing tasks. Experimental results show that it not only outperforms the state-of-the-art RL-based methods and rule-based methods by a large margin, but also achieves better performance in terms of scalability and robustness.
Multistep Speed Prediction on Traffic Networks: A Graph Convolutional Sequence-to-Sequence Learning Approach with Attention Mechanism
Oct 24, 2018

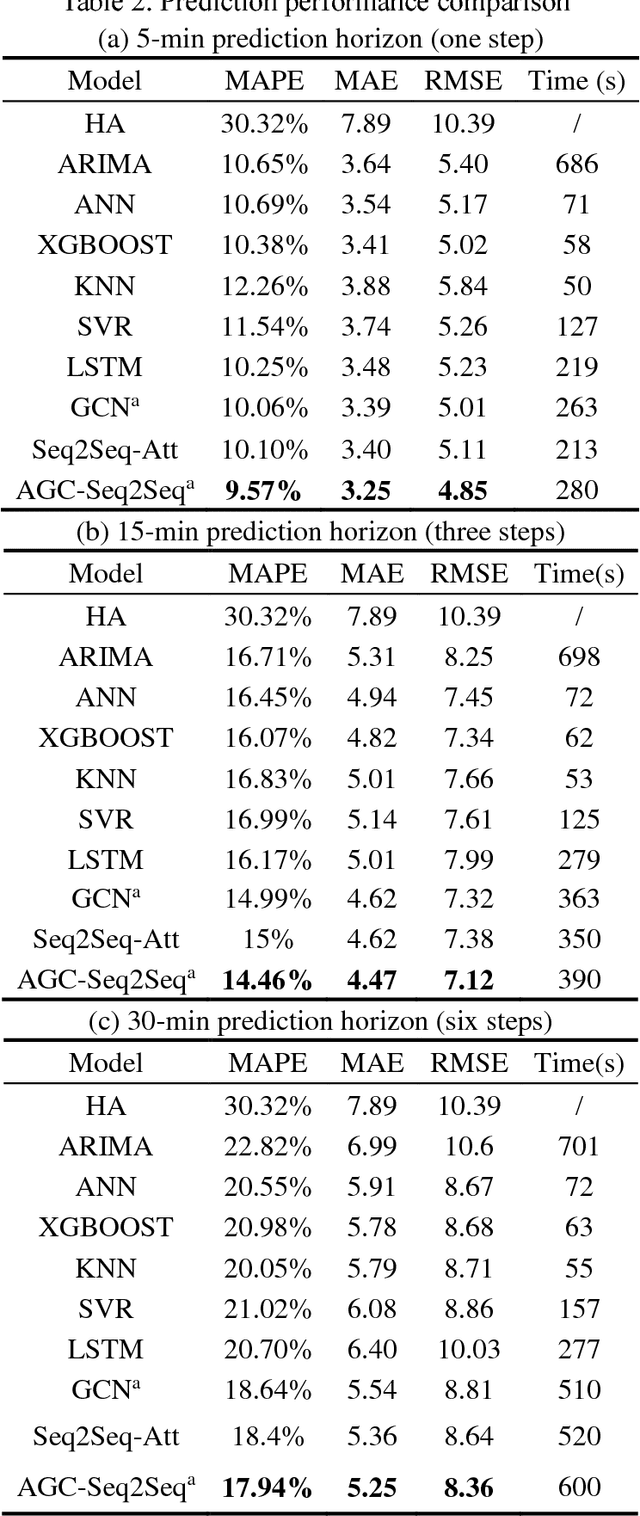
Multistep traffic forecasting on road networks is a crucial task in successful intelligent transportation system applications. To capture the complex non-stationary temporal dynamics and spatial dependency in multistep traffic-condition prediction, we propose a novel deep learning framework named attention graph convolutional sequence-to-sequence model (AGC-Seq2Seq). In the proposed deep learning framework, spatial and temporal dependencies are modeled through the Seq2Seq model and graph convolution network separately, and the attention mechanism along with a newly designed training method based on the Seq2Seq architecture is proposed to overcome the difficulty in multistep prediction and further capture the temporal heterogeneity of traffic pattern. We conduct numerical tests to compare AGC-Seq2Seq with other benchmark models using a real-world dataset. The results indicate that our model yields the best prediction performance in terms of various prediction error measures. Furthermore, the variation of spatiotemporal correlation of traffic conditions under different perdition steps and road segments is revealed through sensitivity analyses.