 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
LiteG2P: A fast, light and high accuracy model for grapheme-to-phoneme conversion
Mar 02, 2023
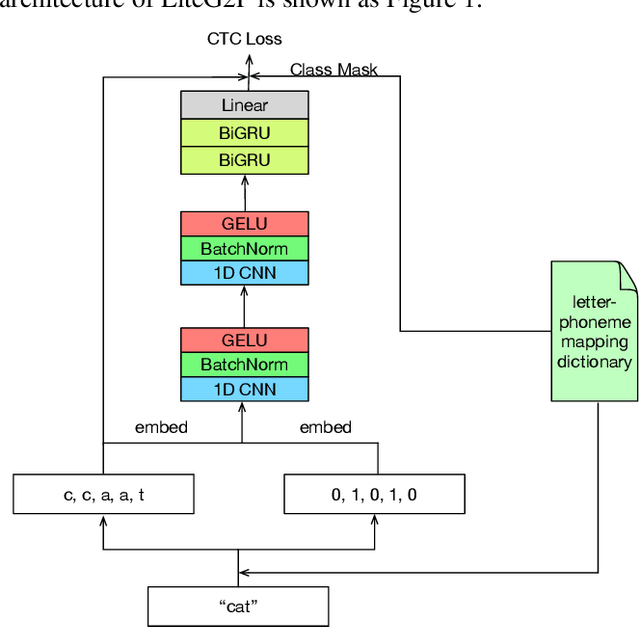
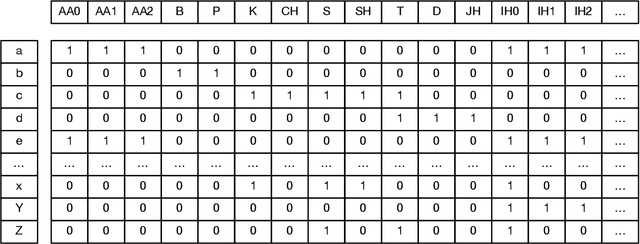
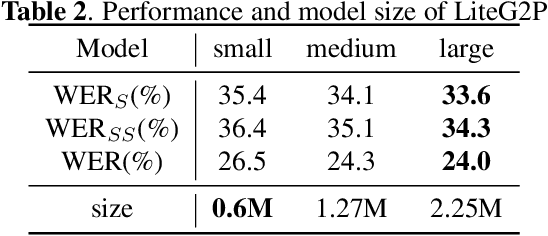
As a key component of automated speech recognition (ASR) and the front-end in text-to-speech (TTS), grapheme-to-phoneme (G2P) plays the role of converting letters to their corresponding pronunciations. Existing methods are either slow or poor in performance, and are limited in application scenarios, particularly in the process of on-device inference. In this paper, we integrate the advantages of both expert knowledge and connectionist temporal classification (CTC) based neural network and propose a novel method named LiteG2P which is fast, light and theoretically parallel. With the carefully leading design, LiteG2P can be applied both on cloud and on device. Experimental results on the CMU dataset show that the performance of the proposed method is superior to the state-of-the-art CTC based method with 10 times fewer parameters, and even comparable to the state-of-the-art Transformer-based sequence-to-sequence model with less parameters and 33 times less computation.