 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024



We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.
LiteG2P: A fast, light and high accuracy model for grapheme-to-phoneme conversion
Mar 02, 2023
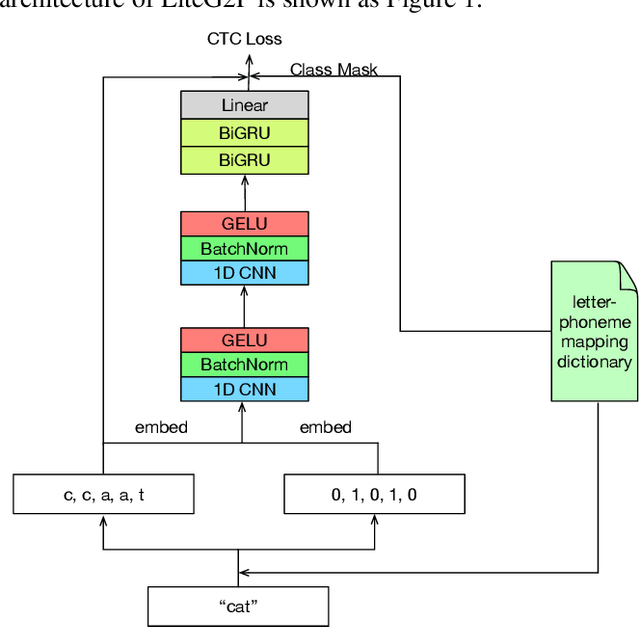
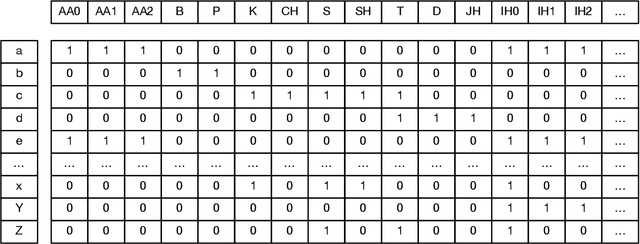
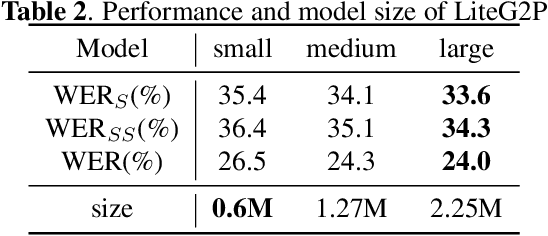
As a key component of automated speech recognition (ASR) and the front-end in text-to-speech (TTS), grapheme-to-phoneme (G2P) plays the role of converting letters to their corresponding pronunciations. Existing methods are either slow or poor in performance, and are limited in application scenarios, particularly in the process of on-device inference. In this paper, we integrate the advantages of both expert knowledge and connectionist temporal classification (CTC) based neural network and propose a novel method named LiteG2P which is fast, light and theoretically parallel. With the carefully leading design, LiteG2P can be applied both on cloud and on device. Experimental results on the CMU dataset show that the performance of the proposed method is superior to the state-of-the-art CTC based method with 10 times fewer parameters, and even comparable to the state-of-the-art Transformer-based sequence-to-sequence model with less parameters and 33 times less computation.