 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-Value-Action Model: Implicit Planning for Vision-Language-Action Systems
Apr 16, 2026Vision-Language-Action (VLA) models have emerged as a promising paradigm for building embodied agents that ground perception and language into action. However, most existing approaches rely on direct action prediction, lacking the ability to reason over long-horizon trajectories and evaluate their consequences, which limits performance in complex decision-making tasks. In this work, we introduce World-Value-Action (WAV) model, a unified framework that enables implicit planning in VLA systems. Rather than performing explicit trajectory optimization, WAV model learn a structured latent representation of future trajectories conditioned on visual observations and language instructions. A learned world model predicts future states, while a trajectory value function evaluates their long-horizon utility. Action generation is then formulated as inference in this latent space, where the model progressively concentrates probability mass on high-value and dynamically feasible trajectories. We provide a theoretical perspective showing that planning directly in action space suffers from an exponential decay in the probability of feasible trajectories as the horizon increases. In contrast, latent-space inference reshapes the search distribution toward feasible regions, enabling efficient long-horizon decision making. Extensive simulations and real-world experiments demonstrate that the WAV model consistently outperforms state-of-the-art methods, achieving significant improvements in task success rate, generalization ability, and robustness, especially in long-horizon and compositional scenarios.
NFPO: Stabilized Policy Optimization of Normalizing Flow for Robotic Policy Learning
Mar 12, 2026Deep Reinforcement Learning (DRL) has experienced significant advancements in recent years and has been widely used in many fields. In DRL-based robotic policy learning, however, current de facto policy parameterization is still multivariate Gaussian (with diagonal covariance matrix), which lacks the ability to model multi-modal distribution. In this work, we explore the adoption of a modern network architecture, i.e. Normalizing Flow (NF) as the policy parameterization for its ability of multi-modal modeling, closed form of log probability and low computation and memory overhead. However, naively training NF in online Reinforcement Learning (RL) usually leads to training instability. We provide a detailed analysis for this phenomenon and successfully address it via simple but effective technique. With extensive experiments in multiple simulation environments, we show our method, NFPO could obtain robust and strong performance in widely used robotic learning tasks and successfully transfer into real-world robots.
An Imitation Game for Learning Semantic Parsers from User Interaction
May 02, 2020
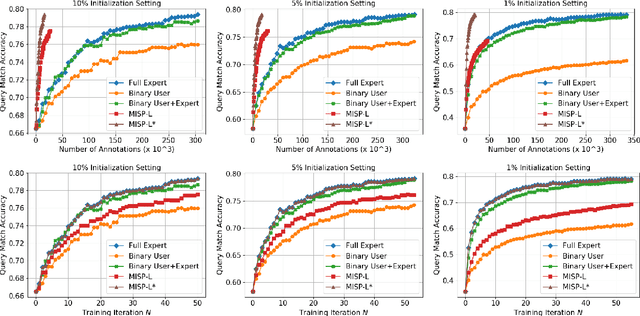


Despite the widely successful applications, bootstrapping and fine-tuning semantic parsers are still a tedious process with challenges such as costly data annotation and privacy risks. In this paper, we suggest an alternative, human-in-the-loop methodology for learning semantic parsers directly from users. A semantic parser should be introspective of its uncertainties and prompt for user demonstration when uncertain. In doing so it also gets to imitate the user behavior and continue improving itself autonomously with the hope that eventually it may become as good as the user in interpreting their questions. To combat the sparsity of demonstration, we propose a novel annotation-efficient imitation learning algorithm, which iteratively collects new datasets by mixing demonstrated states and confident predictions and re-trains the semantic parser in a Dataset Aggregation fashion (Ross et al., 2011). We provide a theoretical analysis of its cost bound and also empirically demonstrate its promising performance on the text-to-SQL problem.
On the Convergence of Adaptive Gradient Methods for Nonconvex Optimization
Aug 16, 2018Adaptive gradient methods are workhorses in deep learning. However, the convergence guarantees of adaptive gradient methods for nonconvex optimization have not been sufficiently studied. In this paper, we provide a sharp analysis of a recently proposed adaptive gradient method namely partially adaptive momentum estimation method (Padam) (Chen and Gu, 2018), which admits many existing adaptive gradient methods such as AdaGrad, RMSProp and AMSGrad as special cases. Our analysis shows that, for smooth nonconvex functions, Padam converges to a first-order stationary point at the rate of $O\big((\sum_{i=1}^d\|\mathbf{g}_{1:T,i}\|_2)^{1/2}/T^{3/4} + d/T\big)$, where $T$ is the number of iterations, $d$ is the dimension, $\mathbf{g}_1,\ldots,\mathbf{g}_T$ are the stochastic gradients, and $\mathbf{g}_{1:T,i} = [g_{1,i},g_{2,i},\ldots,g_{T,i}]^\top$. Our theoretical result also suggests that in order to achieve faster convergence rate, it is necessary to use Padam instead of AMSGrad. This is well-aligned with the empirical results of deep learning reported in Chen and Gu (2018).
Label Propagation on K-partite Graphs with Heterophily
Jan 21, 2017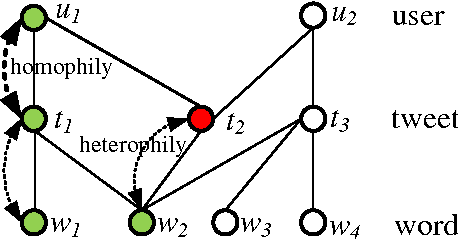
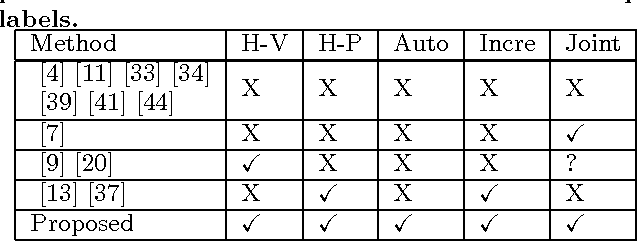
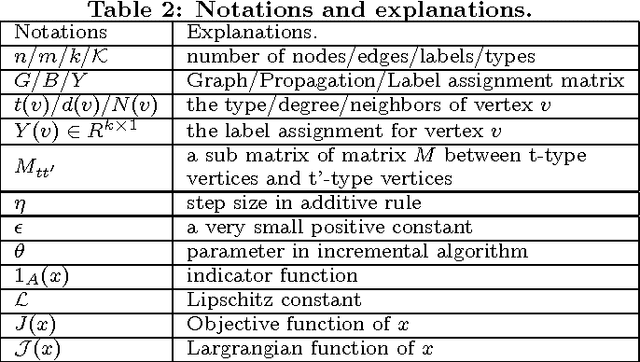
In this paper, for the first time, we study label propagation in heterogeneous graphs under heterophily assumption. Homophily label propagation (i.e., two connected nodes share similar labels) in homogeneous graph (with same types of vertices and relations) has been extensively studied before. Unfortunately, real-life networks are heterogeneous, they contain different types of vertices (e.g., users, images, texts) and relations (e.g., friendships, co-tagging) and allow for each node to propagate both the same and opposite copy of labels to its neighbors. We propose a $\mathcal{K}$-partite label propagation model to handle the mystifying combination of heterogeneous nodes/relations and heterophily propagation. With this model, we develop a novel label inference algorithm framework with update rules in near-linear time complexity. Since real networks change over time, we devise an incremental approach, which supports fast updates for both new data and evidence (e.g., ground truth labels) with guaranteed efficiency. We further provide a utility function to automatically determine whether an incremental or a re-modeling approach is favored. Extensive experiments on real datasets have verified the effectiveness and efficiency of our approach, and its superiority over the state-of-the-art label propagation methods.