 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Imitation Game for Learning Semantic Parsers from User Interaction
Paper and Code

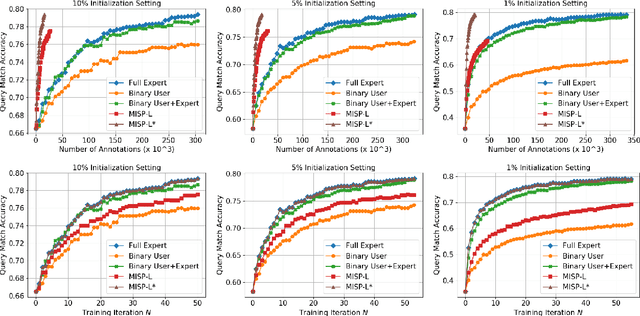


Despite the widely successful applications, bootstrapping and fine-tuning semantic parsers are still a tedious process with challenges such as costly data annotation and privacy risks. In this paper, we suggest an alternative, human-in-the-loop methodology for learning semantic parsers directly from users. A semantic parser should be introspective of its uncertainties and prompt for user demonstration when uncertain. In doing so it also gets to imitate the user behavior and continue improving itself autonomously with the hope that eventually it may become as good as the user in interpreting their questions. To combat the sparsity of demonstration, we propose a novel annotation-efficient imitation learning algorithm, which iteratively collects new datasets by mixing demonstrated states and confident predictions and re-trains the semantic parser in a Dataset Aggregation fashion (Ross et al., 2011). We provide a theoretical analysis of its cost bound and also empirically demonstrate its promising performance on the text-to-SQL problem.