 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCASRec: A Self-Correcting and Auto-Stopping Model for Generative Route List Recommendation
Feb 03, 2026Route recommendation systems commonly adopt a multi-stage pipeline involving fine-ranking and re-ranking to produce high-quality ordered recommendations. However, this paradigm faces three critical limitations. First, there is a misalignment between offline training objectives and online metrics. Offline gains do not necessarily translate to online improvements. Actual performance must be validated through A/B testing, which may potentially compromise the user experience. Second, redundancy elimination relies on rigid, handcrafted rules that lack adaptability to the high variance in user intent and the unstructured complexity of real-world scenarios. Third, the strict separation between fine-ranking and re-ranking stages leads to sub-optimal performance. Since each module is optimized in isolation, the fine-ranking stage remains oblivious to the list-level objectives (e.g., diversity) targeted by the re-ranker, thereby preventing the system from achieving a jointly optimized global optimum. To overcome these intertwined challenges, we propose \textbf{SCASRec} (\textbf{S}elf-\textbf{C}orrecting and \textbf{A}uto-\textbf{S}topping \textbf{Rec}ommendation), a unified generative framework that integrates ranking and redundancy elimination into a single end-to-end process. SCASRec introduces a stepwise corrective reward (SCR) to guide list-wise refinement by focusing on hard samples, and employs a learnable End-of-Recommendation (EOR) token to terminate generation adaptively when no further improvement is expected. Experiments on two large-scale, open-sourced route recommendation datasets demonstrate that SCASRec establishes an SOTA in offline and online settings. SCASRec has been fully deployed in a real-world navigation app, demonstrating its effectiveness.
DSFNet: Learning Disentangled Scenario Factorization for Multi-Scenario Route Ranking
Mar 30, 2024



Multi-scenario route ranking (MSRR) is crucial in many industrial mapping systems. However, the industrial community mainly adopts interactive interfaces to encourage users to select pre-defined scenarios, which may hinder the downstream ranking performance. In addition, in the academic community, the multi-scenario ranking works only come from other fields, and there are no works specifically focusing on route data due to lacking a publicly available MSRR dataset. Moreover, all the existing multi-scenario works still fail to address the three specific challenges of MSRR simultaneously, i.e. explosion of scenario number, high entanglement, and high-capacity demand. Different from the prior, to address MSRR, our key idea is to factorize the complicated scenario in route ranking into several disentangled factor scenario patterns. Accordingly, we propose a novel method, Disentangled Scenario Factorization Network (DSFNet), which flexibly composes scenario-dependent parameters based on a high-capacity multi-factor-scenario-branch structure. Then, a novel regularization is proposed to induce the disentanglement of factor scenarios. Furthermore, two extra novel techniques, i.e. scenario-aware batch normalization and scenario-aware feature filtering, are developed to improve the network awareness of scenario representation. Additionally, to facilitate MSRR research in the academic community, we propose MSDR, the first large-scale publicly available annotated industrial Multi-Scenario Driving Route dataset. Comprehensive experimental results demonstrate the superiority of our DSFNet, which has been successfully deployed in AMap to serve the major online traffic.
KoGuN: Accelerating Deep Reinforcement Learning via Integrating Human Suboptimal Knowledge
Feb 18, 2020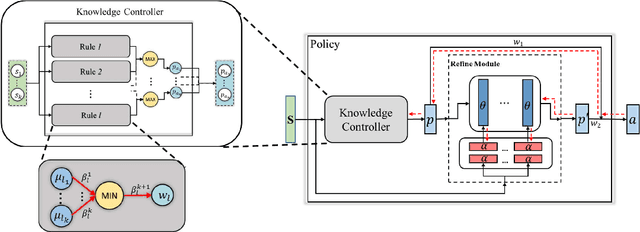
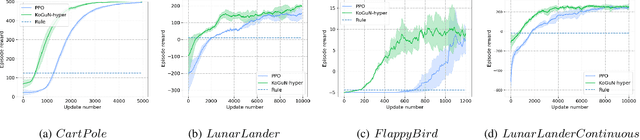
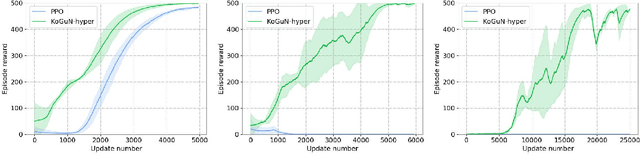
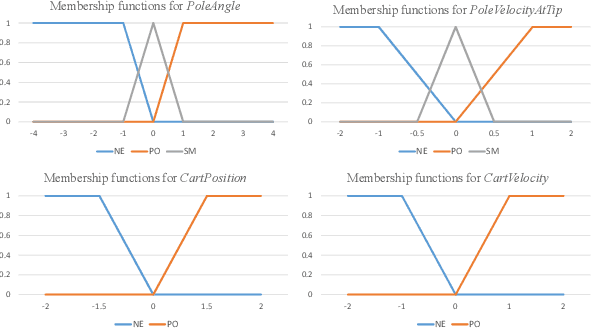
Reinforcement learning agents usually learn from scratch, which requires a large number of interactions with the environment. This is quite different from the learning process of human. When faced with a new task, human naturally have the common sense and use the prior knowledge to derive an initial policy and guide the learning process afterwards. Although the prior knowledge may be not fully applicable to the new task, the learning process is significantly sped up since the initial policy ensures a quick-start of learning and intermediate guidance allows to avoid unnecessary exploration. Taking this inspiration, we propose knowledge guided policy network (KoGuN), a novel framework that combines human prior suboptimal knowledge with reinforcement learning. Our framework consists of a fuzzy rule controller to represent human knowledge and a refine module to fine-tune suboptimal prior knowledge. The proposed framework is end-to-end and can be combined with existing policy-based reinforcement learning algorithm. We conduct experiments on both discrete and continuous control tasks. The empirical results show that our approach, which combines human suboptimal knowledge and RL, achieves significant improvement on learning efficiency of flat RL algorithms, even with very low-performance human prior knowledge.
Falsification of Cyber-Physical Systems Using Deep Reinforcement Learning
May 01, 2018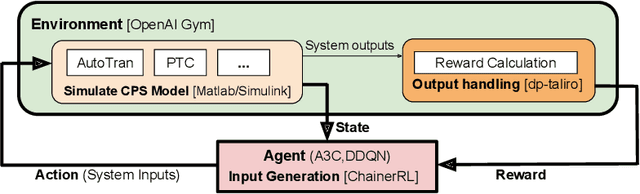
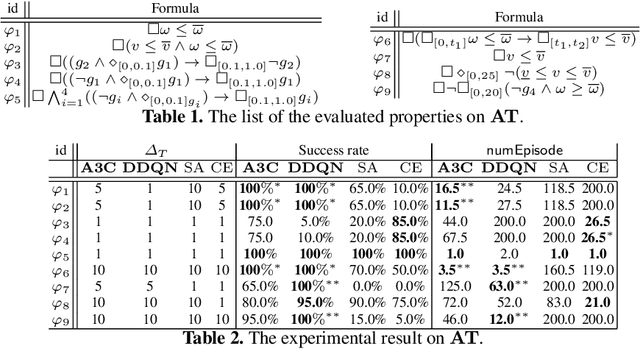
With the rapid development of software and distributed computing, Cyber-Physical Systems (CPS) are widely adopted in many application areas, e.g., smart grid, autonomous automobile. It is difficult to detect defects in CPS models due to the complexities involved in the software and physical systems. To find defects in CPS models efficiently, robustness guided falsification of CPS is introduced. Existing methods use several optimization techniques to generate counterexamples, which falsify the given properties of a CPS. However those methods may require a large number of simulation runs to find the counterexample and is far from practical. In this work, we explore state-of-the-art Deep Reinforcement Learning (DRL) techniques to reduce the number of simulation runs required to find such counterexamples. We report our method and the preliminary evaluation results.
* 9 pages, 1 figure, to be presented at FM2018