 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPGroup3D: Superpoint Grouping Network for Indoor 3D Object Detection
Dec 21, 2023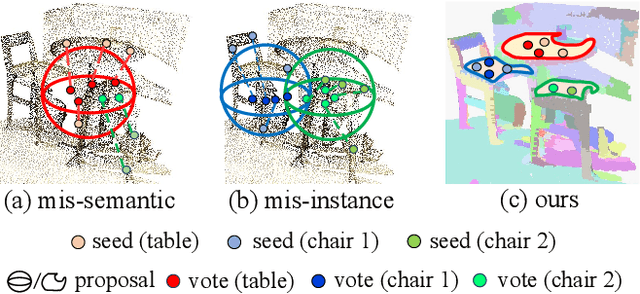
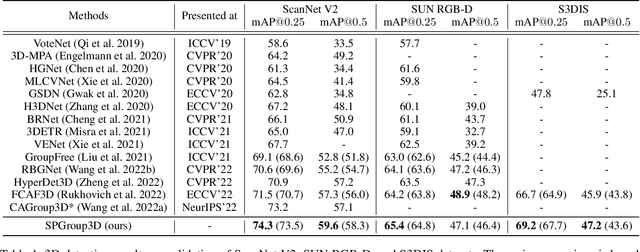
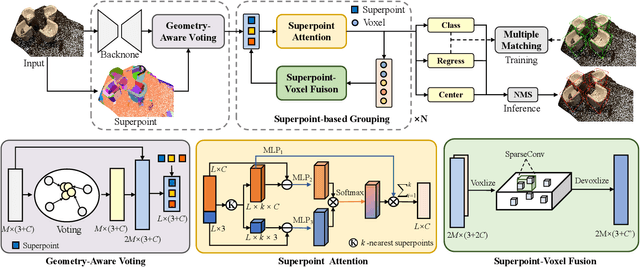
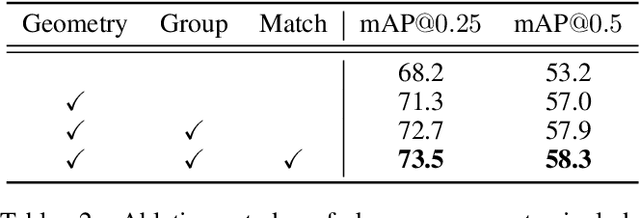
Current 3D object detection methods for indoor scenes mainly follow the voting-and-grouping strategy to generate proposals. However, most methods utilize instance-agnostic groupings, such as ball query, leading to inconsistent semantic information and inaccurate regression of the proposals. To this end, we propose a novel superpoint grouping network for indoor anchor-free one-stage 3D object detection. Specifically, we first adopt an unsupervised manner to partition raw point clouds into superpoints, areas with semantic consistency and spatial similarity. Then, we design a geometry-aware voting module that adapts to the centerness in anchor-free detection by constraining the spatial relationship between superpoints and object centers. Next, we present a superpoint-based grouping module to explore the consistent representation within proposals. This module includes a superpoint attention layer to learn feature interaction between neighboring superpoints, and a superpoint-voxel fusion layer to propagate the superpoint-level information to the voxel level. Finally, we employ effective multiple matching to capitalize on the dynamic receptive fields of proposals based on superpoints during the training. Experimental results demonstrate our method achieves state-of-the-art performance on ScanNet V2, SUN RGB-D, and S3DIS datasets in the indoor one-stage 3D object detection. Source code is available at https://github.com/zyrant/SPGroup3D.
Self-Supervised 3D Scene Flow Estimation Guided by Superpoints
May 04, 2023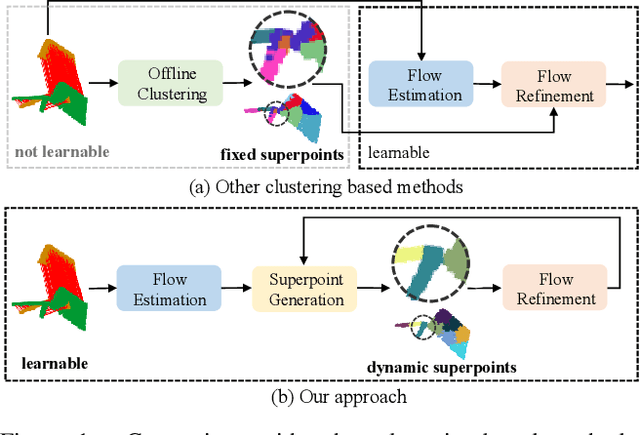

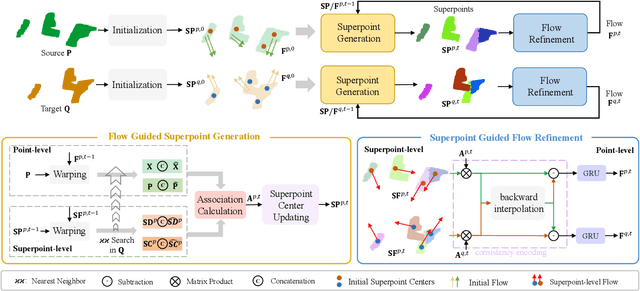

3D scene flow estimation aims to estimate point-wise motions between two consecutive frames of point clouds. Superpoints, i.e., points with similar geometric features, are usually employed to capture similar motions of local regions in 3D scenes for scene flow estimation. However, in existing methods, superpoints are generated with the offline clustering methods, which cannot characterize local regions with similar motions for complex 3D scenes well, leading to inaccurate scene flow estimation. To this end, we propose an iterative end-to-end superpoint based scene flow estimation framework, where the superpoints can be dynamically updated to guide the point-level flow prediction. Specifically, our framework consists of a flow guided superpoint generation module and a superpoint guided flow refinement module. In our superpoint generation module, we utilize the bidirectional flow information at the previous iteration to obtain the matching points of points and superpoint centers for soft point-to-superpoint association construction, in which the superpoints are generated for pairwise point clouds. With the generated superpoints, we first reconstruct the flow for each point by adaptively aggregating the superpoint-level flow, and then encode the consistency between the reconstructed flow of pairwise point clouds. Finally, we feed the consistency encoding along with the reconstructed flow into GRU to refine point-level flow. Extensive experiments on several different datasets show that our method can achieve promising performance.
Large-scale Point Cloud Registration Based on Graph Matching Optimization
Feb 16, 2023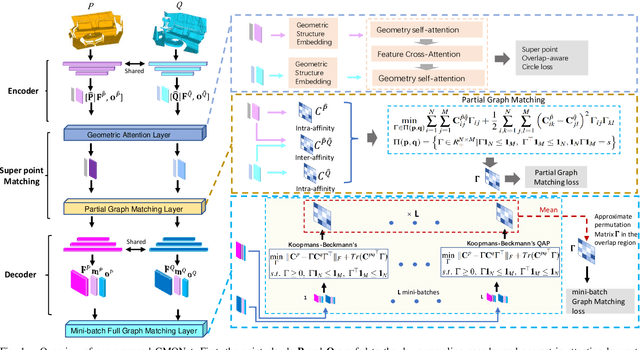



Point Clouds Registration is a fundamental and challenging problem in 3D computer vision. It has been shown that the isometric transformation is an essential property in rigid point cloud registration, but the existing methods only utilize it in the outlier rejection stage. In this paper, we emphasize that the isometric transformation is also important in the feature learning stage for improving registration quality. We propose a \underline{G}raph \underline{M}atching \underline{O}ptimization based \underline{Net}work (denoted as GMONet for short), which utilizes the graph matching method to explicitly exert the isometry preserving constraints in the point feature learning stage to improve %refine the point representation. Specifically, we %use exploit the partial graph matching constraint to enhance the overlap region detection abilities of super points ($i.e.,$ down-sampled key points) and full graph matching to refine the registration accuracy at the fine-level overlap region. Meanwhile, we leverage the mini-batch sampling to improve the efficiency of the full graph matching optimization. Given high discriminative point features in the evaluation stage, we utilize the RANSAC approach to estimate the transformation between the scanned pairs. The proposed method has been evaluated on the 3DMatch/3DLoMatch benchmarks and the KITTI benchmark. The experimental results show that our method achieves competitive performance compared with the existing state-of-the-art baselines.
Reliable Inlier Evaluation for Unsupervised Point Cloud Registration
Feb 23, 2022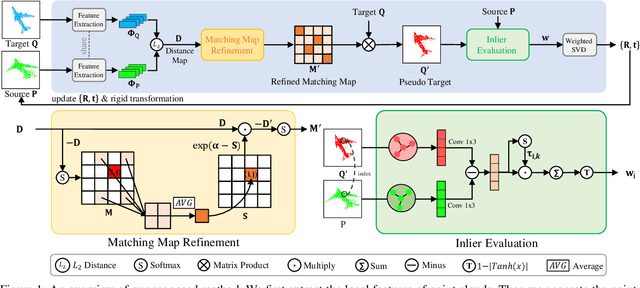
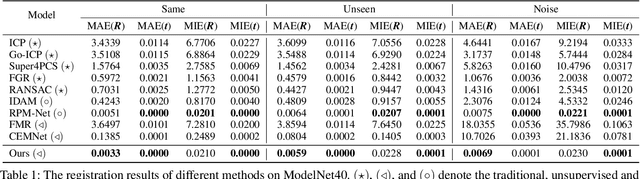
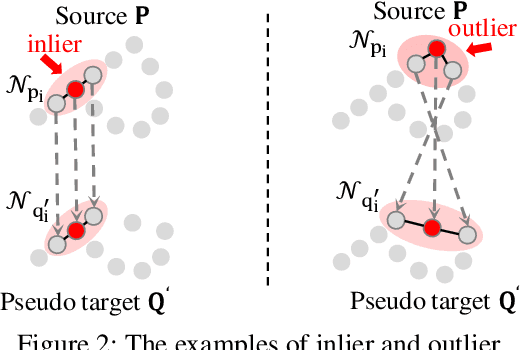
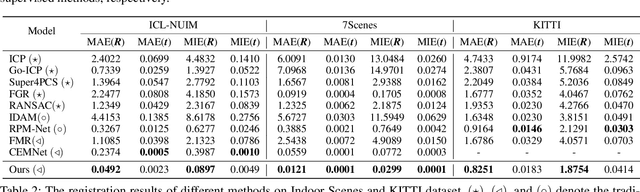
Unsupervised point cloud registration algorithm usually suffers from the unsatisfied registration precision in the partially overlapping problem due to the lack of effective inlier evaluation. In this paper, we propose a neighborhood consensus based reliable inlier evaluation method for robust unsupervised point cloud registration. It is expected to capture the discriminative geometric difference between the source neighborhood and the corresponding pseudo target neighborhood for effective inlier distinction. Specifically, our model consists of a matching map refinement module and an inlier evaluation module. In our matching map refinement module, we improve the point-wise matching map estimation by integrating the matching scores of neighbors into it. The aggregated neighborhood information potentially facilitates the discriminative map construction so that high-quality correspondences can be provided for generating the pseudo target point cloud. Based on the observation that the outlier has the significant structure-wise difference between its source neighborhood and corresponding pseudo target neighborhood while this difference for inlier is small, the inlier evaluation module exploits this difference to score the inlier confidence for each estimated correspondence. In particular, we construct an effective graph representation for capturing this geometric difference between the neighborhoods. Finally, with the learned correspondences and the corresponding inlier confidence, we use the weighted SVD algorithm for transformation estimation. Under the unsupervised setting, we exploit the Huber function based global alignment loss, the local neighborhood consensus loss, and spatial consistency loss for model optimization. The experimental results on extensive datasets demonstrate that our unsupervised point cloud registration method can yield comparable performance.
Sampling Network Guided Cross-Entropy Method for Unsupervised Point Cloud Registration
Sep 15, 2021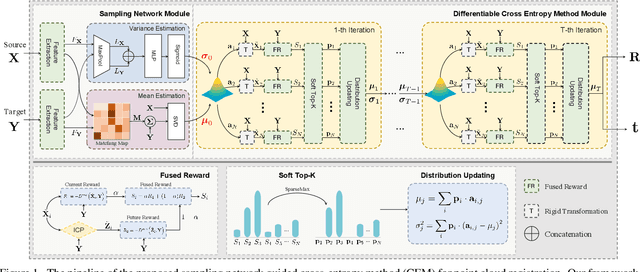
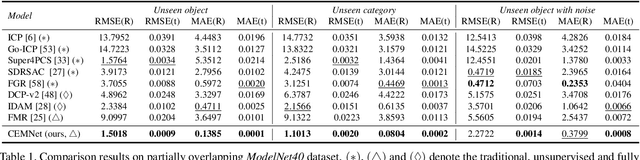
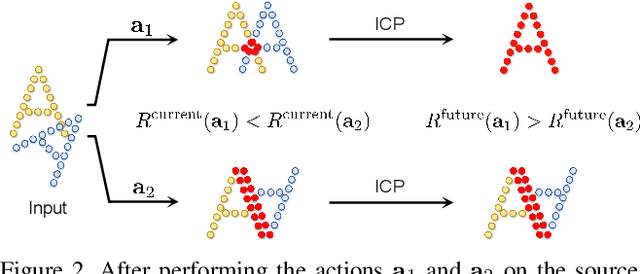
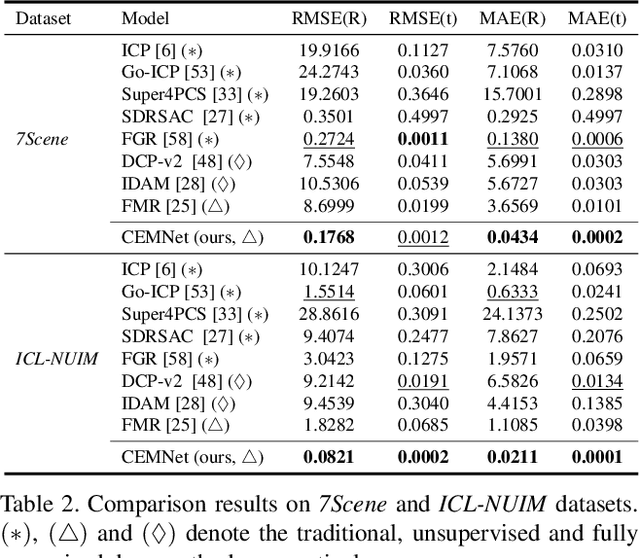
In this paper, by modeling the point cloud registration task as a Markov decision process, we propose an end-to-end deep model embedded with the cross-entropy method (CEM) for unsupervised 3D registration. Our model consists of a sampling network module and a differentiable CEM module. In our sampling network module, given a pair of point clouds, the sampling network learns a prior sampling distribution over the transformation space. The learned sampling distribution can be used as a "good" initialization of the differentiable CEM module. In our differentiable CEM module, we first propose a maximum consensus criterion based alignment metric as the reward function for the point cloud registration task. Based on the reward function, for each state, we then construct a fused score function to evaluate the sampled transformations, where we weight the current and future rewards of the transformations. Particularly, the future rewards of the sampled transforms are obtained by performing the iterative closest point (ICP) algorithm on the transformed state. By selecting the top-k transformations with the highest scores, we iteratively update the sampling distribution. Furthermore, in order to make the CEM differentiable, we use the sparsemax function to replace the hard top-$k$ selection. Finally, we formulate a Geman-McClure estimator based loss to train our end-to-end registration model. Extensive experimental results demonstrate the good registration performance of our method on benchmark datasets.