 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPGroup3D: Superpoint Grouping Network for Indoor 3D Object Detection
Paper and Code
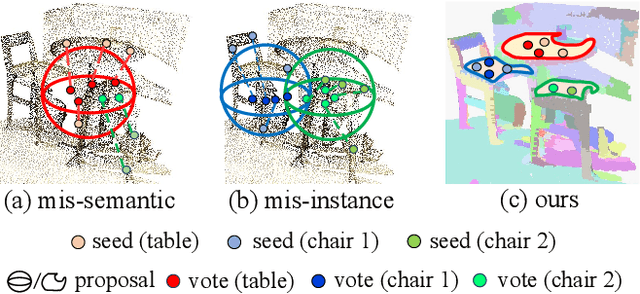
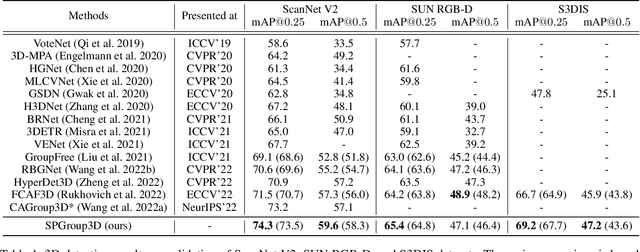
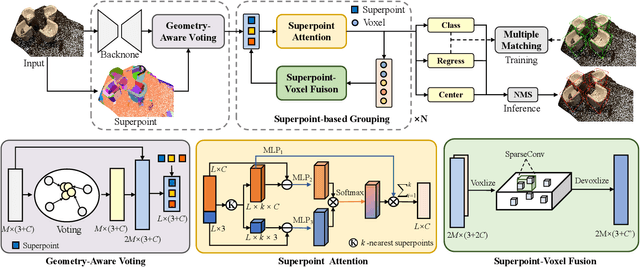
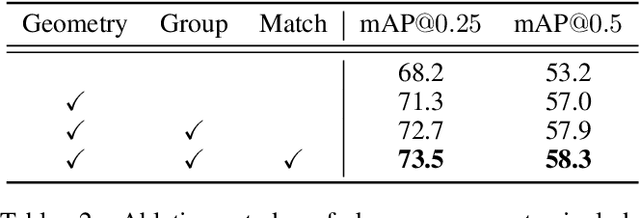
Current 3D object detection methods for indoor scenes mainly follow the voting-and-grouping strategy to generate proposals. However, most methods utilize instance-agnostic groupings, such as ball query, leading to inconsistent semantic information and inaccurate regression of the proposals. To this end, we propose a novel superpoint grouping network for indoor anchor-free one-stage 3D object detection. Specifically, we first adopt an unsupervised manner to partition raw point clouds into superpoints, areas with semantic consistency and spatial similarity. Then, we design a geometry-aware voting module that adapts to the centerness in anchor-free detection by constraining the spatial relationship between superpoints and object centers. Next, we present a superpoint-based grouping module to explore the consistent representation within proposals. This module includes a superpoint attention layer to learn feature interaction between neighboring superpoints, and a superpoint-voxel fusion layer to propagate the superpoint-level information to the voxel level. Finally, we employ effective multiple matching to capitalize on the dynamic receptive fields of proposals based on superpoints during the training. Experimental results demonstrate our method achieves state-of-the-art performance on ScanNet V2, SUN RGB-D, and S3DIS datasets in the indoor one-stage 3D object detection. Source code is available at https://github.com/zyrant/SPGroup3D.