 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHGMP:Heterogeneous Graph Multi-Task Prompt Learning
Jul 10, 2025


The pre-training and fine-tuning methods have gained widespread attention in the field of heterogeneous graph neural networks due to their ability to leverage large amounts of unlabeled data during the pre-training phase, allowing the model to learn rich structural features. However, these methods face the issue of a mismatch between the pre-trained model and downstream tasks, leading to suboptimal performance in certain application scenarios. Prompt learning methods have emerged as a new direction in heterogeneous graph tasks, as they allow flexible adaptation of task representations to address target inconsistency. Building on this idea, this paper proposes a novel multi-task prompt framework for the heterogeneous graph domain, named HGMP. First, to bridge the gap between the pre-trained model and downstream tasks, we reformulate all downstream tasks into a unified graph-level task format. Next, we address the limitations of existing graph prompt learning methods, which struggle to integrate contrastive pre-training strategies in the heterogeneous graph domain. We design a graph-level contrastive pre-training strategy to better leverage heterogeneous information and enhance performance in multi-task scenarios. Finally, we introduce heterogeneous feature prompts, which enhance model performance by refining the representation of input graph features. Experimental results on public datasets show that our proposed method adapts well to various tasks and significantly outperforms baseline methods.
Table-Filling via Mean Teacher for Cross-domain Aspect Sentiment Triplet Extraction
Jul 23, 2024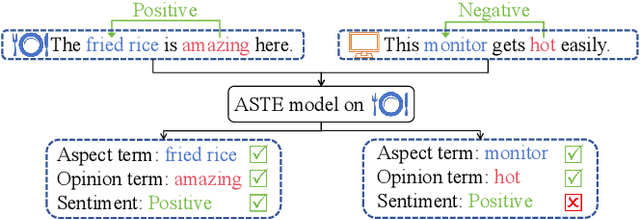
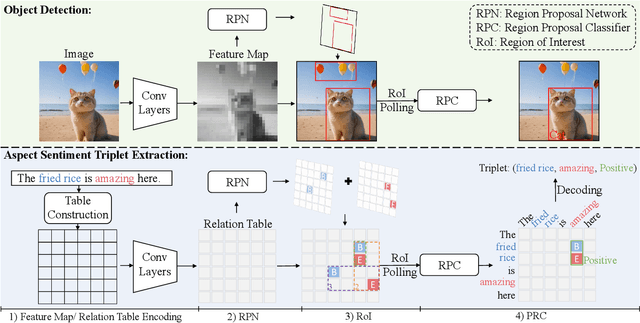
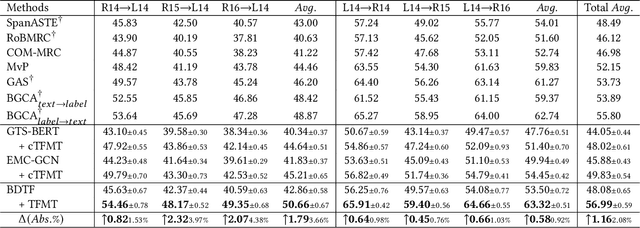
Cross-domain Aspect Sentiment Triplet Extraction (ASTE) aims to extract fine-grained sentiment elements from target domain sentences by leveraging the knowledge acquired from the source domain. Due to the absence of labeled data in the target domain, recent studies tend to rely on pre-trained language models to generate large amounts of synthetic data for training purposes. However, these approaches entail additional computational costs associated with the generation process. Different from them, we discover a striking resemblance between table-filling methods in ASTE and two-stage Object Detection (OD) in computer vision, which inspires us to revisit the cross-domain ASTE task and approach it from an OD standpoint. This allows the model to benefit from the OD extraction paradigm and region-level alignment. Building upon this premise, we propose a novel method named \textbf{T}able-\textbf{F}illing via \textbf{M}ean \textbf{T}eacher (TFMT). Specifically, the table-filling methods encode the sentence into a 2D table to detect word relations, while TFMT treats the table as a feature map and utilizes a region consistency to enhance the quality of those generated pseudo labels. Additionally, considering the existence of the domain gap, a cross-domain consistency based on Maximum Mean Discrepancy is designed to alleviate domain shift problems. Our method achieves state-of-the-art performance with minimal parameters and computational costs, making it a strong baseline for cross-domain ASTE.