 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse-Dense Mixture of Experts Adapter for Multi-Modal Tracking
Mar 14, 2026Parameter-efficient fine-tuning (PEFT) techniques, such as prompts and adapters, are widely used in multi-modal tracking because they alleviate issues of full-model fine-tuning, including time inefficiency, high resource consumption, parameter storage burden, and catastrophic forgetting. However, due to cross-modal heterogeneity, most existing PEFT-based methods struggle to effectively represent multi-modal features within a unified framework with shared parameters. To address this problem, we propose a novel Sparse-Dense Mixture of Experts Adapter (SDMoEA) framework for PEFT-based multi-modal tracking under a unified model structure. Specifically, we design an SDMoE module as the multi-modal adapter to model modality-specific and shared information efficiently. SDMoE consists of a sparse MoE and a dense-shared MoE: the former captures modality-specific information, while the latter models shared cross-modal information. Furthermore, to overcome limitations of existing tracking methods in modeling high-order correlations during multi-level multi-modal fusion, we introduce a Gram-based Semantic Alignment Hypergraph Fusion (GSAHF) module. It first employs Gram matrices for cross-modal semantic alignment, ensuring that the constructed hypergraph accurately reflects semantic similarity and high-order dependencies between modalities. The aligned features are then integrated into the hypergraph structure to exploit its ability to model high-order relationships, enabling deep fusion of multi-level multi-modal information. Extensive experiments demonstrate that the proposed method achieves superior performance compared with other PEFT approaches on several multi-modal tracking benchmarks, including LasHeR, RGBT234, VTUAV, VisEvent, COESOT, DepthTrack, and VOT-RGBD2022.
Visible-Thermal Multiple Object Tracking: Large-scale Video Dataset and Progressive Fusion Approach
Aug 02, 2024The complementary benefits from visible and thermal infrared data are widely utilized in various computer vision task, such as visual tracking, semantic segmentation and object detection, but rarely explored in Multiple Object Tracking (MOT). In this work, we contribute a large-scale Visible-Thermal video benchmark for MOT, called VT-MOT. VT-MOT has the following main advantages. 1) The data is large scale and high diversity. VT-MOT includes 582 video sequence pairs, 401k frame pairs from surveillance, drone, and handheld platforms. 2) The cross-modal alignment is highly accurate. We invite several professionals to perform both spatial and temporal alignment frame by frame. 3) The annotation is dense and high-quality. VT-MOT has 3.99 million annotation boxes annotated and double-checked by professionals, including heavy occlusion and object re-acquisition (object disappear and reappear) challenges. To provide a strong baseline, we design a simple yet effective tracking framework, which effectively fuses temporal information and complementary information of two modalities in a progressive manner, for robust visible-thermal MOT. A comprehensive experiment are conducted on VT-MOT and the results prove the superiority and effectiveness of the proposed method compared with state-of-the-art methods. From the evaluation results and analysis, we specify several potential future directions for visible-thermal MOT. The project is released in https://github.com/wqw123wqw/PFTrack.
Uncertainty-aware Bridge based Mobile-Former Network for Event-based Pattern Recognition
Jan 20, 2024The mainstream human activity recognition (HAR) algorithms are developed based on RGB cameras, which are easily influenced by low-quality images (e.g., low illumination, motion blur). Meanwhile, the privacy protection issue caused by ultra-high definition (HD) RGB cameras aroused more and more people's attention. Inspired by the success of event cameras which perform better on high dynamic range, no motion blur, and low energy consumption, we propose to recognize human actions based on the event stream. We propose a lightweight uncertainty-aware information propagation based Mobile-Former network for efficient pattern recognition, which aggregates the MobileNet and Transformer network effectively. Specifically, we first embed the event images using a stem network into feature representations, then, feed them into uncertainty-aware Mobile-Former blocks for local and global feature learning and fusion. Finally, the features from MobileNet and Transformer branches are concatenated for pattern recognition. Extensive experiments on multiple event-based recognition datasets fully validated the effectiveness of our model. The source code of this work will be released at https://github.com/Event-AHU/Uncertainty_aware_MobileFormer.
CRSOT: Cross-Resolution Object Tracking using Unaligned Frame and Event Cameras
Jan 05, 2024Existing datasets for RGB-DVS tracking are collected with DVS346 camera and their resolution ($346 \times 260$) is low for practical applications. Actually, only visible cameras are deployed in many practical systems, and the newly designed neuromorphic cameras may have different resolutions. The latest neuromorphic sensors can output high-definition event streams, but it is very difficult to achieve strict alignment between events and frames on both spatial and temporal views. Therefore, how to achieve accurate tracking with unaligned neuromorphic and visible sensors is a valuable but unresearched problem. In this work, we formally propose the task of object tracking using unaligned neuromorphic and visible cameras. We build the first unaligned frame-event dataset CRSOT collected with a specially built data acquisition system, which contains 1,030 high-definition RGB-Event video pairs, 304,974 video frames. In addition, we propose a novel unaligned object tracking framework that can realize robust tracking even using the loosely aligned RGB-Event data. Specifically, we extract the template and search regions of RGB and Event data and feed them into a unified ViT backbone for feature embedding. Then, we propose uncertainty perception modules to encode the RGB and Event features, respectively, then, we propose a modality uncertainty fusion module to aggregate the two modalities. These three branches are jointly optimized in the training phase. Extensive experiments demonstrate that our tracker can collaborate the dual modalities for high-performance tracking even without strictly temporal and spatial alignment. The source code, dataset, and pre-trained models will be released at https://github.com/Event-AHU/Cross_Resolution_SOT.
RGBT Tracking via Progressive Fusion Transformer with Dynamically Guided Learning
Mar 26, 2023

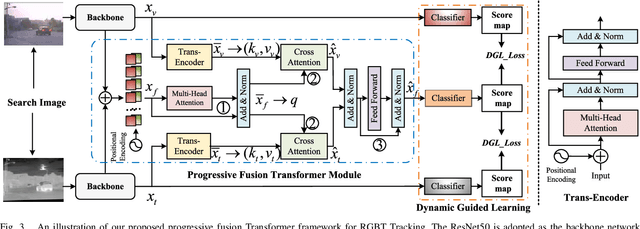

Existing Transformer-based RGBT tracking methods either use cross-attention to fuse the two modalities, or use self-attention and cross-attention to model both modality-specific and modality-sharing information. However, the significant appearance gap between modalities limits the feature representation ability of certain modalities during the fusion process. To address this problem, we propose a novel Progressive Fusion Transformer called ProFormer, which progressively integrates single-modality information into the multimodal representation for robust RGBT tracking. In particular, ProFormer first uses a self-attention module to collaboratively extract the multimodal representation, and then uses two cross-attention modules to interact it with the features of the dual modalities respectively. In this way, the modality-specific information can well be activated in the multimodal representation. Finally, a feed-forward network is used to fuse two interacted multimodal representations for the further enhancement of the final multimodal representation. In addition, existing learning methods of RGBT trackers either fuse multimodal features into one for final classification, or exploit the relationship between unimodal branches and fused branch through a competitive learning strategy. However, they either ignore the learning of single-modality branches or result in one branch failing to be well optimized. To solve these problems, we propose a dynamically guided learning algorithm that adaptively uses well-performing branches to guide the learning of other branches, for enhancing the representation ability of each branch. Extensive experiments demonstrate that our proposed ProFormer sets a new state-of-the-art performance on RGBT210, RGBT234, LasHeR, and VTUAV datasets.
Tiny Object Tracking: A Large-scale Dataset and A Baseline
Feb 11, 2022

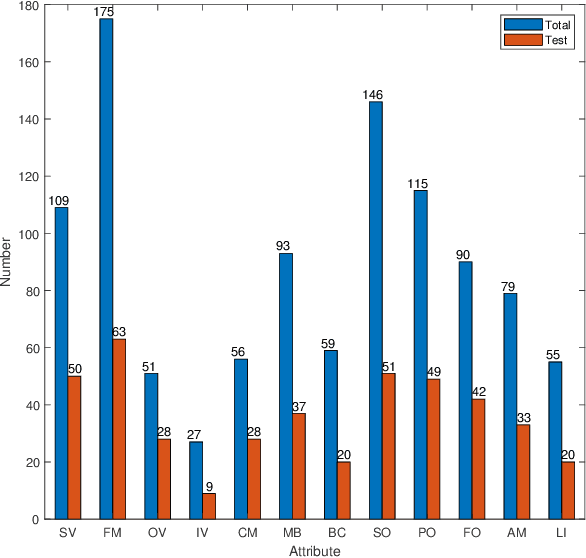
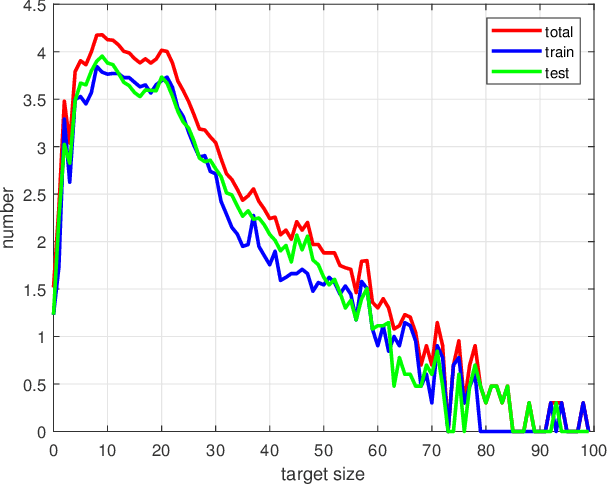
Tiny objects, frequently appearing in practical applications, have weak appearance and features, and receive increasing interests in meany vision tasks, such as object detection and segmentation. To promote the research and development of tiny object tracking, we create a large-scale video dataset, which contains 434 sequences with a total of more than 217K frames. Each frame is carefully annotated with a high-quality bounding box. In data creation, we take 12 challenge attributes into account to cover a broad range of viewpoints and scene complexities, and annotate these attributes for facilitating the attribute-based performance analysis. To provide a strong baseline in tiny object tracking, we propose a novel Multilevel Knowledge Distillation Network (MKDNet), which pursues three-level knowledge distillations in a unified framework to effectively enhance the feature representation, discrimination and localization abilities in tracking tiny objects. Extensive experiments are performed on the proposed dataset, and the results prove the superiority and effectiveness of MKDNet compared with state-of-the-art methods. The dataset, the algorithm code, and the evaluation code are available at https://github.com/mmic-lcl/Datasets-and-benchmark-code.
Learning Target-oriented Dual Attention for Robust RGB-T Tracking
Aug 12, 2019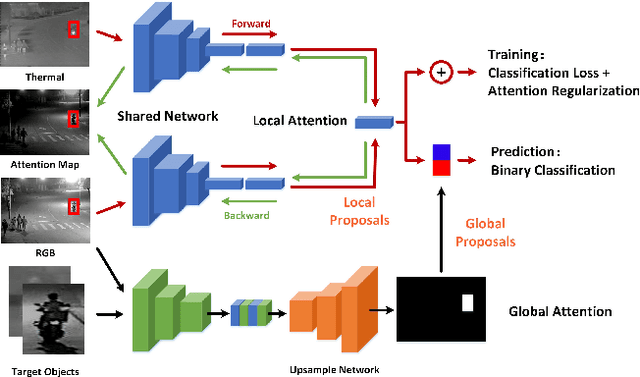

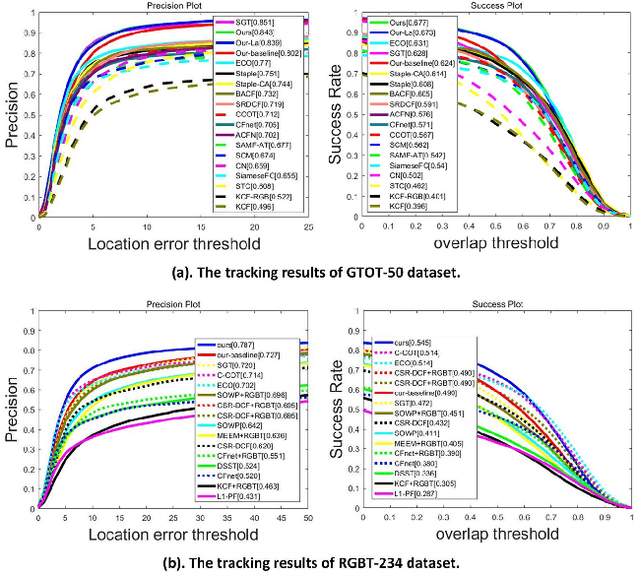

RGB-Thermal object tracking attempt to locate target object using complementary visual and thermal infrared data. Existing RGB-T trackers fuse different modalities by robust feature representation learning or adaptive modal weighting. However, how to integrate dual attention mechanism for visual tracking is still a subject that has not been studied yet. In this paper, we propose two visual attention mechanisms for robust RGB-T object tracking. Specifically, the local attention is implemented by exploiting the common visual attention of RGB and thermal data to train deep classifiers. We also introduce the global attention, which is a multi-modal target-driven attention estimation network. It can provide global proposals for the classifier together with local proposals extracted from previous tracking result. Extensive experiments on two RGB-T benchmark datasets validated the effectiveness of our proposed algorithm.
Dense Feature Aggregation and Pruning for RGBT Tracking
Jul 24, 2019


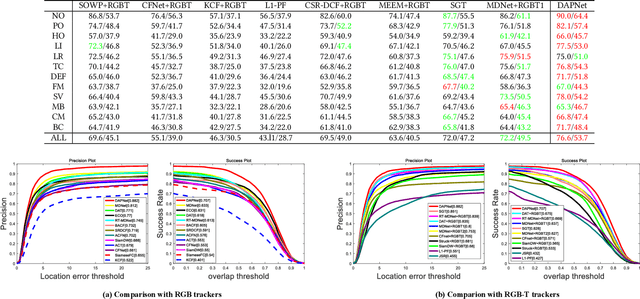
How to perform effective information fusion of different modalities is a core factor in boosting the performance of RGBT tracking. This paper presents a novel deep fusion algorithm based on the representations from an end-to-end trained convolutional neural network. To deploy the complementarity of features of all layers, we propose a recursive strategy to densely aggregate these features that yield robust representations of target objects in each modality. In different modalities, we propose to prune the densely aggregated features of all modalities in a collaborative way. In a specific, we employ the operations of global average pooling and weighted random selection to perform channel scoring and selection, which could remove redundant and noisy features to achieve more robust feature representation. Experimental results on two RGBT tracking benchmark datasets suggest that our tracker achieves clear state-of-the-art against other RGB and RGBT tracking methods.
FANet: Quality-Aware Feature Aggregation Network for RGB-T Tracking
Nov 24, 2018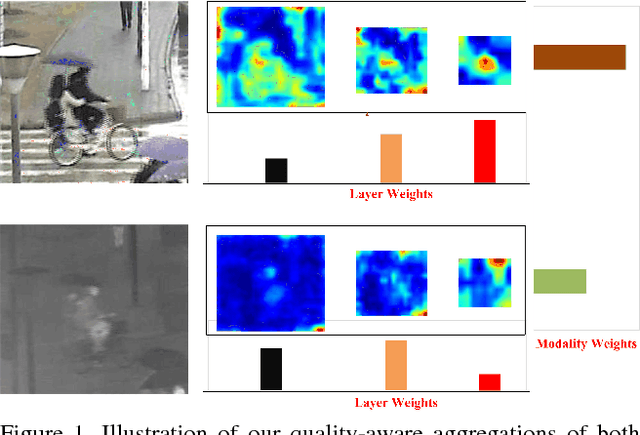
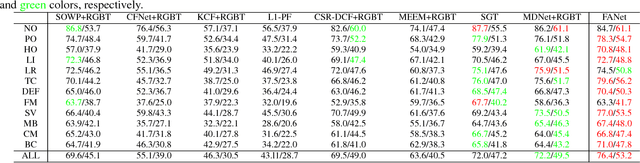
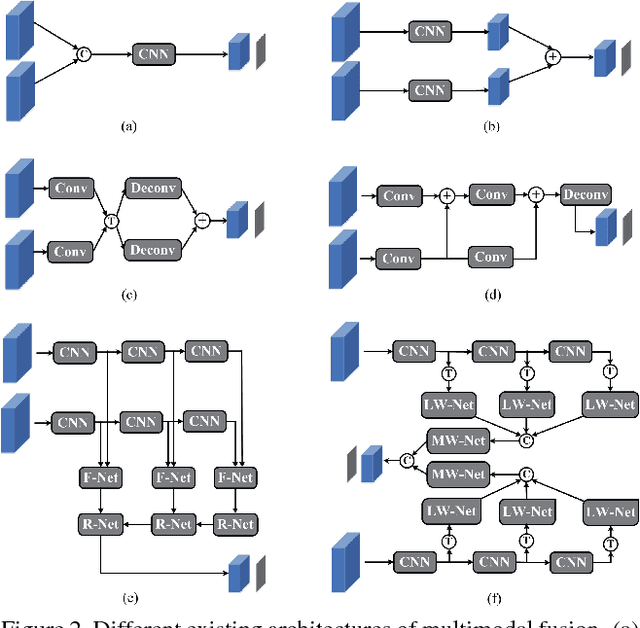
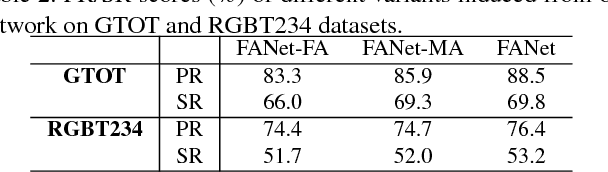
This paper investigates how to perform robust visual tracking in adverse and challenging conditions using complementary visual and thermal infrared data (RGB-T tracking). We propose a novel deep network architecture "quality-aware Feature Aggregation Network (FANet)" to achieve quality-aware aggregations of both hierarchical features and multimodal information for robust online RGB-T tracking. Unlike existing works that directly concatenate hierarchical deep features, our FANet learns the layer weights to adaptively aggregate them to handle the challenge of significant appearance changes caused by deformation, abrupt motion, background clutter and occlusion within each modality. Moreover, we employ the operations of max pooling, interpolation upsampling and convolution to transform these hierarchical and multi-resolution features into a uniform space at the same resolution for more effective feature aggregation. In different modalities, we elaborately design a multimodal aggregation sub-network to integrate all modalities collaboratively based on the predicted reliability degrees. Extensive experiments on large-scale benchmark datasets demonstrate that our FANet significantly outperforms other state-of-the-art RGB-T tracking methods.