 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGBT Tracking via Progressive Fusion Transformer with Dynamically Guided Learning
Paper and Code
Mar 26, 2023

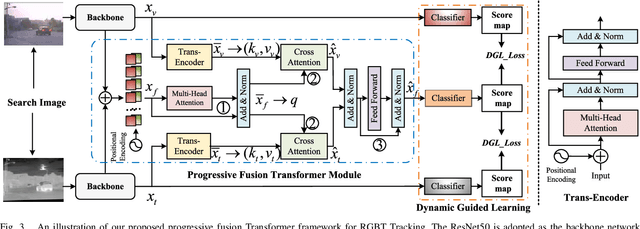

Existing Transformer-based RGBT tracking methods either use cross-attention to fuse the two modalities, or use self-attention and cross-attention to model both modality-specific and modality-sharing information. However, the significant appearance gap between modalities limits the feature representation ability of certain modalities during the fusion process. To address this problem, we propose a novel Progressive Fusion Transformer called ProFormer, which progressively integrates single-modality information into the multimodal representation for robust RGBT tracking. In particular, ProFormer first uses a self-attention module to collaboratively extract the multimodal representation, and then uses two cross-attention modules to interact it with the features of the dual modalities respectively. In this way, the modality-specific information can well be activated in the multimodal representation. Finally, a feed-forward network is used to fuse two interacted multimodal representations for the further enhancement of the final multimodal representation. In addition, existing learning methods of RGBT trackers either fuse multimodal features into one for final classification, or exploit the relationship between unimodal branches and fused branch through a competitive learning strategy. However, they either ignore the learning of single-modality branches or result in one branch failing to be well optimized. To solve these problems, we propose a dynamically guided learning algorithm that adaptively uses well-performing branches to guide the learning of other branches, for enhancing the representation ability of each branch. Extensive experiments demonstrate that our proposed ProFormer sets a new state-of-the-art performance on RGBT210, RGBT234, LasHeR, and VTUAV datasets.