 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
VLA-AN: An Efficient and Onboard Vision-Language-Action Framework for Aerial Navigation in Complex Environments
Dec 19, 2025



This paper proposes VLA-AN, an efficient and onboard Vision-Language-Action (VLA) framework dedicated to autonomous drone navigation in complex environments. VLA-AN addresses four major limitations of existing large aerial navigation models: the data domain gap, insufficient temporal navigation with reasoning, safety issues with generative action policies, and onboard deployment constraints. First, we construct a high-fidelity dataset utilizing 3D Gaussian Splatting (3D-GS) to effectively bridge the domain gap. Second, we introduce a progressive three-stage training framework that sequentially reinforces scene comprehension, core flight skills, and complex navigation capabilities. Third, we design a lightweight, real-time action module coupled with geometric safety correction. This module ensures fast, collision-free, and stable command generation, mitigating the safety risks inherent in stochastic generative policies. Finally, through deep optimization of the onboard deployment pipeline, VLA-AN achieves a robust real-time 8.3x improvement in inference throughput on resource-constrained UAVs. Extensive experiments demonstrate that VLA-AN significantly improves spatial grounding, scene reasoning, and long-horizon navigation, achieving a maximum single-task success rate of 98.1%, and providing an efficient, practical solution for realizing full-chain closed-loop autonomy in lightweight aerial robots.
S3MOT: Monocular 3D Object Tracking with Selective State Space Model
Apr 25, 2025Accurate and reliable multi-object tracking (MOT) in 3D space is essential for advancing robotics and computer vision applications. However, it remains a significant challenge in monocular setups due to the difficulty of mining 3D spatiotemporal associations from 2D video streams. In this work, we present three innovative techniques to enhance the fusion and exploitation of heterogeneous cues for monocular 3D MOT: (1) we introduce the Hungarian State Space Model (HSSM), a novel data association mechanism that compresses contextual tracking cues across multiple paths, enabling efficient and comprehensive assignment decisions with linear complexity. HSSM features a global receptive field and dynamic weights, in contrast to traditional linear assignment algorithms that rely on hand-crafted association costs. (2) We propose Fully Convolutional One-stage Embedding (FCOE), which eliminates ROI pooling by directly using dense feature maps for contrastive learning, thus improving object re-identification accuracy under challenging conditions such as varying viewpoints and lighting. (3) We enhance 6-DoF pose estimation through VeloSSM, an encoder-decoder architecture that models temporal dependencies in velocity to capture motion dynamics, overcoming the limitations of frame-based 3D inference. Experiments on the KITTI public test benchmark demonstrate the effectiveness of our method, achieving a new state-of-the-art performance of 76.86~HOTA at 31~FPS. Our approach outperforms the previous best by significant margins of +2.63~HOTA and +3.62~AssA, showcasing its robustness and efficiency for monocular 3D MOT tasks. The code and models are available at https://github.com/bytepioneerX/s3mot.
eKalibr-Stereo: Continuous-Time Spatiotemporal Calibration for Event-Based Stereo Visual Systems
Apr 06, 2025



The bioinspired event camera, distinguished by its exceptional temporal resolution, high dynamic range, and low power consumption, has been extensively studied in recent years for motion estimation, robotic perception, and object detection. In ego-motion estimation, the stereo event camera setup is commonly adopted due to its direct scale perception and depth recovery. For optimal stereo visual fusion, accurate spatiotemporal (extrinsic and temporal) calibration is required. Considering that few stereo visual calibrators orienting to event cameras exist, based on our previous work eKalibr (an event camera intrinsic calibrator), we propose eKalibr-Stereo for accurate spatiotemporal calibration of event-based stereo visual systems. To improve the continuity of grid pattern tracking, building upon the grid pattern recognition method in eKalibr, an additional motion prior-based tracking module is designed in eKalibr-Stereo to track incomplete grid patterns. Based on tracked grid patterns, a two-step initialization procedure is performed to recover initial guesses of piece-wise B-splines and spatiotemporal parameters, followed by a continuous-time batch bundle adjustment to refine the initialized states to optimal ones. The results of extensive real-world experiments show that eKalibr-Stereo can achieve accurate event-based stereo spatiotemporal calibration. The implementation of eKalibr-Stereo is open-sourced at (https://github.com/Unsigned-Long/eKalibr) to benefit the research community.
eKalibr: Dynamic Intrinsic Calibration for Event Cameras From First Principles of Events
Jan 10, 2025



The bio-inspired event camera has garnered extensive research attention in recent years, owing to its significant potential derived from its high dynamic range and low latency characteristics. Similar to the standard camera, the event camera requires precise intrinsic calibration to facilitate further high-level visual applications, such as pose estimation and mapping. While several calibration methods for event cameras have been proposed, most of them are either (i) engineering-driven, heavily relying on conventional image-based calibration pipelines, or (ii) inconvenient, requiring complex instrumentation. To this end, we propose an accurate and convenient intrinsic calibration method for event cameras, named eKalibr, which builds upon a carefully designed event-based circle grid pattern recognition algorithm. To extract target patterns from events, we perform event-based normal flow estimation to identify potential events generated by circle edges, and cluster them spatially. Subsequently, event clusters associated with the same grid circles are matched and grouped using normal flows, for subsequent time-varying ellipse estimation. Fitted ellipse centers are time-synchronized, for final grid pattern recognition. We conducted extensive experiments to evaluate the performance of eKalibr in terms of pattern extraction and intrinsic calibration. The implementation of eKalibr is open-sourced at (https://github.com/Unsigned-Long/eKalibr) to benefit the research community.
SF-Loc: A Visual Mapping and Geo-Localization System based on Sparse Visual Structure Frames
Dec 02, 2024



For high-level geo-spatial applications and intelligent robotics, accurate global pose information is of crucial importance. Map-aided localization is an important and universal approach to overcome the limitations of global navigation satellite system (GNSS) in challenging environments. However, current solutions face challenges in terms of mapping flexibility, storage burden and re-localization performance. In this work, we present SF-Loc, a lightweight visual mapping and map-aided localization system, whose core idea is the map representation based on sparse frames with dense (though downsampled) depth, termed as visual structure frames. In the mapping phase, multi-sensor dense bundle adjustment (MS-DBA) is applied to construct geo-referenced visual structure frames. The local co-visbility is checked to keep the map sparsity and achieve incremental mapping. In the localization phase, coarse-to-fine vision-based localization is performed, in which multi-frame information and the map distribution are fully integrated. To be specific, the concept of spatially smoothed similarity (SSS) is proposed to overcome the place ambiguity, and pairwise frame matching is applied for efficient and robust pose estimation. Experimental results on both public and self-made datasets verify the effectiveness of the system. In complex urban road scenarios, the map size is down to 3 MB per kilometer and stable decimeter-level re-localization can be achieved. The code will be made open-source soon (https://github.com/GREAT-WHU/SF-Loc).
Seed-Music: A Unified Framework for High Quality and Controlled Music Generation
Sep 13, 2024



We introduce Seed-Music, a suite of music generation systems capable of producing high-quality music with fine-grained style control. Our unified framework leverages both auto-regressive language modeling and diffusion approaches to support two key music creation workflows: \textit{controlled music generation} and \textit{post-production editing}. For controlled music generation, our system enables vocal music generation with performance controls from multi-modal inputs, including style descriptions, audio references, musical scores, and voice prompts. For post-production editing, it offers interactive tools for editing lyrics and vocal melodies directly in the generated audio. We encourage readers to listen to demo audio examples at https://team.doubao.com/seed-music .
Equivariant Filter for Tightly Coupled LiDAR-Inertial Odometry
Sep 11, 2024Pose estimation is a crucial problem in simultaneous localization and mapping (SLAM). However, developing a robust and consistent state estimator remains a significant challenge, as the traditional extended Kalman filter (EKF) struggles to handle the model nonlinearity, especially for inertial measurement unit (IMU) and light detection and ranging (LiDAR). To provide a consistent and efficient solution of pose estimation, we propose Eq-LIO, a robust state estimator for tightly coupled LIO systems based on an equivariant filter (EqF). Compared with the invariant Kalman filter based on the $\SE_2(3)$ group structure, the EqF uses the symmetry of the semi-direct product group to couple the system state including IMU bias, navigation state and LiDAR extrinsic calibration state, thereby suppressing linearization error and improving the behavior of the estimator in the event of unexpected state changes. The proposed Eq-LIO owns natural consistency and higher robustness, which is theoretically proven with mathematical derivation and experimentally verified through a series of tests on both public and private datasets.
iKalibr-RGBD: Partially-Specialized Target-Free Visual-Inertial Spatiotemporal Calibration For RGBDs via Continuous-Time Velocity Estimation
Sep 11, 2024



Visual-inertial systems have been widely studied and applied in the last two decades, mainly due to their low cost and power consumption, small footprint, and high availability. Such a trend simultaneously leads to a large amount of visual-inertial calibration methods being presented, as accurate spatiotemporal parameters between sensors are a prerequisite for visual-inertial fusion. In our previous work, i.e., iKalibr, a continuous-time-based visual-inertial calibration method was proposed as a part of one-shot multi-sensor resilient spatiotemporal calibration. While requiring no artificial target brings considerable convenience, computationally expensive pose estimation is demanded in initialization and batch optimization, limiting its availability. Fortunately, this could be vastly improved for the RGBDs with additional depth information, by employing mapping-free ego-velocity estimation instead of mapping-based pose estimation. In this paper, we present the continuous-time ego-velocity estimation-based RGBD-inertial spatiotemporal calibration, termed as iKalibr-RGBD, which is also targetless but computationally efficient. The general pipeline of iKalibr-RGBD is inherited from iKalibr, composed of a rigorous initialization procedure and several continuous-time batch optimizations. The implementation of iKalibr-RGBD is open-sourced at (https://github.com/Unsigned-Long/iKalibr) to benefit the research community.
RIs-Calib: An Open-Source Spatiotemporal Calibrator for Multiple 3D Radars and IMUs Based on Continuous-Time Estimation
Aug 05, 2024

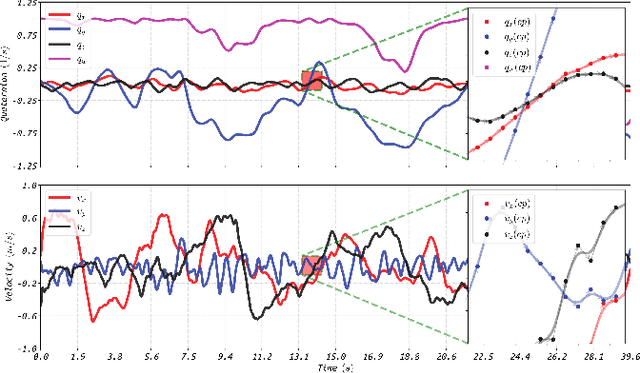

Aided inertial navigation system (INS), typically consisting of an inertial measurement unit (IMU) and an exteroceptive sensor, has been widely accepted as a feasible solution for navigation. Compared with vision-aided and LiDAR-aided INS, radar-aided INS could achieve better performance in adverse weather conditions since the radar utilizes low-frequency measuring signals with less attenuation effect in atmospheric gases and rain. For such a radar-aided INS, accurate spatiotemporal transformation is a fundamental prerequisite to achieving optimal information fusion. In this work, we present RIs-Calib: a spatiotemporal calibrator for multiple 3D radars and IMUs based on continuous-time estimation, which enables accurate spatiotemporal calibration and does not require any additional artificial infrastructure or prior knowledge. Our approach starts with a rigorous and robust procedure for state initialization, followed by batch optimizations, where all parameters can be refined to global optimal states steadily. We validate and evaluate RIs-Calib on both simulated and real-world experiments, and the results demonstrate that RIs-Calib is capable of accurate and consistent calibration. We open-source our implementations at (https://github.com/Unsigned-Long/RIs-Calib) to benefit the research community.