 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Personalized Text-to-image Generation by Leveraging Textual Subspace
Jun 30, 2024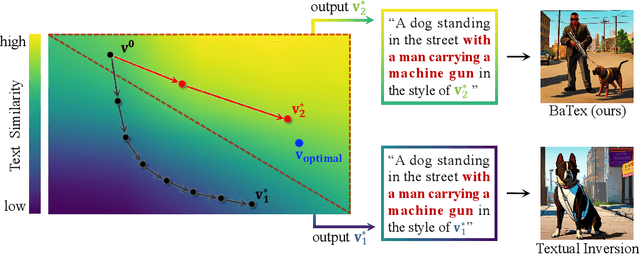

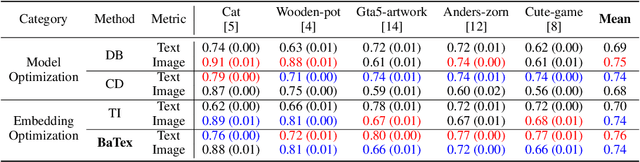
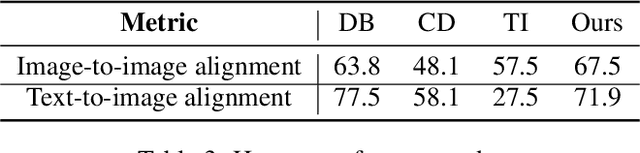
Personalized text-to-image generation has attracted unprecedented attention in the recent few years due to its unique capability of generating highly-personalized images via using the input concept dataset and novel textual prompt. However, previous methods solely focus on the performance of the reconstruction task, degrading its ability to combine with different textual prompt. Besides, optimizing in the high-dimensional embedding space usually leads to unnecessary time-consuming training process and slow convergence. To address these issues, we propose an efficient method to explore the target embedding in a textual subspace, drawing inspiration from the self-expressiveness property. Additionally, we propose an efficient selection strategy for determining the basis vectors of the textual subspace. The experimental evaluations demonstrate that the learned embedding can not only faithfully reconstruct input image, but also significantly improves its alignment with novel input textual prompt. Furthermore, we observe that optimizing in the textual subspace leads to an significant improvement of the robustness to the initial word, relaxing the constraint that requires users to input the most relevant initial word. Our method opens the door to more efficient representation learning for personalized text-to-image generation.
Distilling Representations from GAN Generator via Squeeze and Span
Nov 06, 2022



In recent years, generative adversarial networks (GANs) have been an actively studied topic and shown to successfully produce high-quality realistic images in various domains. The controllable synthesis ability of GAN generators suggests that they maintain informative, disentangled, and explainable image representations, but leveraging and transferring their representations to downstream tasks is largely unexplored. In this paper, we propose to distill knowledge from GAN generators by squeezing and spanning their representations. We squeeze the generator features into representations that are invariant to semantic-preserving transformations through a network before they are distilled into the student network. We span the distilled representation of the synthetic domain to the real domain by also using real training data to remedy the mode collapse of GANs and boost the student network performance in a real domain. Experiments justify the efficacy of our method and reveal its great significance in self-supervised representation learning. Code is available at https://github.com/yangyu12/squeeze-and-span.
Learning to Annotate Part Segmentation with Gradient Matching
Nov 06, 2022



The success of state-of-the-art deep neural networks heavily relies on the presence of large-scale labelled datasets, which are extremely expensive and time-consuming to annotate. This paper focuses on tackling semi-supervised part segmentation tasks by generating high-quality images with a pre-trained GAN and labelling the generated images with an automatic annotator. In particular, we formulate the annotator learning as a learning-to-learn problem. Given a pre-trained GAN, the annotator learns to label object parts in a set of randomly generated images such that a part segmentation model trained on these synthetic images with their predicted labels obtains low segmentation error on a small validation set of manually labelled images. We further reduce this nested-loop optimization problem to a simple gradient matching problem and efficiently solve it with an iterative algorithm. We show that our method can learn annotators from a broad range of labelled images including real images, generated images, and even analytically rendered images. Our method is evaluated with semi-supervised part segmentation tasks and significantly outperforms other semi-supervised competitors when the amount of labelled examples is extremely limited.
Using Computer Vision to Automate Hand Detection and Tracking of Surgeon Movements in Videos of Open Surgery
Dec 13, 2020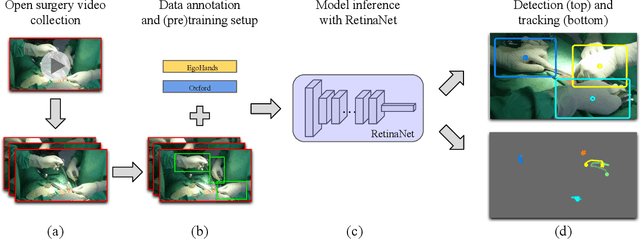

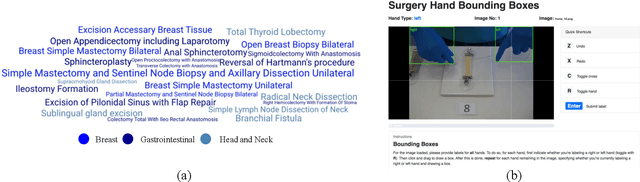

Open, or non-laparoscopic surgery, represents the vast majority of all operating room procedures, but few tools exist to objectively evaluate these techniques at scale. Current efforts involve human expert-based visual assessment. We leverage advances in computer vision to introduce an automated approach to video analysis of surgical execution. A state-of-the-art convolutional neural network architecture for object detection was used to detect operating hands in open surgery videos. Automated assessment was expanded by combining model predictions with a fast object tracker to enable surgeon-specific hand tracking. To train our model, we used publicly available videos of open surgery from YouTube and annotated these with spatial bounding boxes of operating hands. Our model's spatial detections of operating hands significantly outperforms the detections achieved using pre-existing hand-detection datasets, and allow for insights into intra-operative movement patterns and economy of motion.