 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Personalized Text-to-image Generation by Leveraging Textual Subspace
Paper and Code
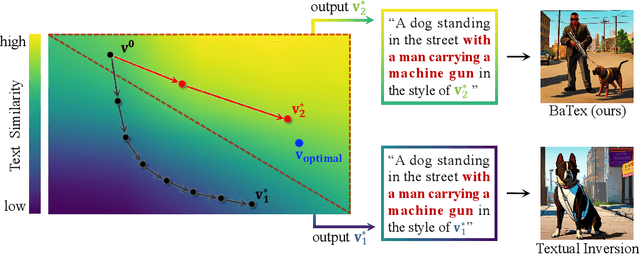

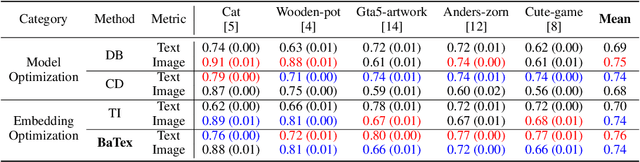
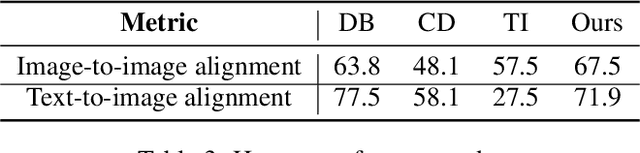
Personalized text-to-image generation has attracted unprecedented attention in the recent few years due to its unique capability of generating highly-personalized images via using the input concept dataset and novel textual prompt. However, previous methods solely focus on the performance of the reconstruction task, degrading its ability to combine with different textual prompt. Besides, optimizing in the high-dimensional embedding space usually leads to unnecessary time-consuming training process and slow convergence. To address these issues, we propose an efficient method to explore the target embedding in a textual subspace, drawing inspiration from the self-expressiveness property. Additionally, we propose an efficient selection strategy for determining the basis vectors of the textual subspace. The experimental evaluations demonstrate that the learned embedding can not only faithfully reconstruct input image, but also significantly improves its alignment with novel input textual prompt. Furthermore, we observe that optimizing in the textual subspace leads to an significant improvement of the robustness to the initial word, relaxing the constraint that requires users to input the most relevant initial word. Our method opens the door to more efficient representation learning for personalized text-to-image generation.