 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
CoServe: Efficient Collaboration-of-Experts (CoE) Model Inference with Limited Memory
Mar 04, 2025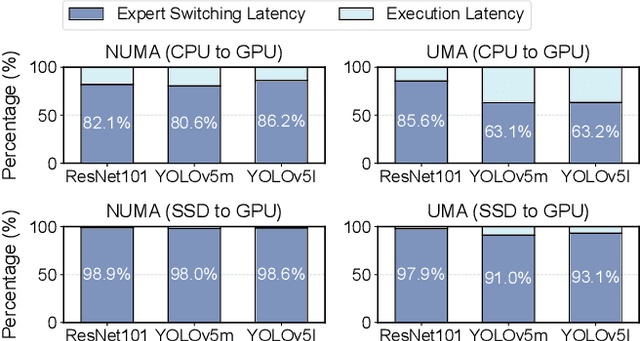

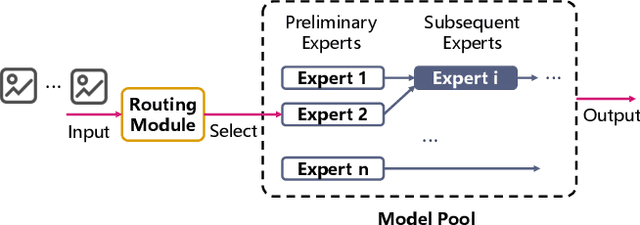
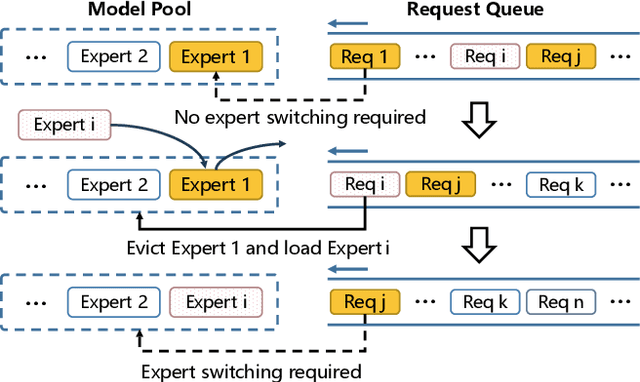
Large language models like GPT-4 are resource-intensive, but recent advancements suggest that smaller, specialized experts can outperform the monolithic models on specific tasks. The Collaboration-of-Experts (CoE) approach integrates multiple expert models, improving the accuracy of generated results and offering great potential for precision-critical applications, such as automatic circuit board quality inspection. However, deploying CoE serving systems presents challenges to memory capacity due to the large number of experts required, which can lead to significant performance overhead from frequent expert switching across different memory and storage tiers. We propose CoServe, an efficient CoE model serving system on heterogeneous CPU and GPU with limited memory. CoServe reduces unnecessary expert switching by leveraging expert dependency, a key property of CoE inference. CoServe introduces a dependency-aware request scheduler and dependency-aware expert management for efficient inference. It also introduces an offline profiler to automatically find optimal resource allocation on various processors and devices. In real-world intelligent manufacturing workloads, CoServe achieves 4.5$\times$ to 12$\times$ higher throughput compared to state-of-the-art systems.
* Accepted to ASPLOS '25
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
Integrating features from lymph node stations for metastatic lymph node detection
Jan 09, 2023Metastasis on lymph nodes (LNs), the most common way of spread for primary tumor cells, is a sign of increased mortality. However, metastatic LNs are time-consuming and challenging to detect even for professional radiologists due to their small sizes, high sparsity, and ambiguity in appearance. It is desired to leverage recent development in deep learning to automatically detect metastatic LNs. Besides a two-stage detection network, we here introduce an additional branch to leverage information about LN stations, an important reference for radiologists during metastatic LN diagnosis, as supplementary information for metastatic LN detection. The branch targets to solve a closely related task on the LN station level, i.e., classifying whether an LN station contains metastatic LN or not, so as to learn representations for LN stations. Considering that a metastatic LN station is expected to significantly affect the nearby ones, a GCN-based structure is adopted by the branch to model the relationship among different LN stations. At the classification stage of metastatic LN detection, the above learned LN station features, as well as the features reflecting the distance between the LN candidate and the LN stations, are integrated with the LN features. We validate our method on a dataset containing 114 intravenous contrast-enhanced Computed Tomography (CT) images of oral squamous cell carcinoma (OSCC) patients and show that it outperforms several state-of-the-art methods on the mFROC, maxF1, and AUC scores,respectively.