 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Grounded Motion Forecasting via Equation Discovery for Trajectory-Guided Image-to-Video Generation
Jul 09, 2025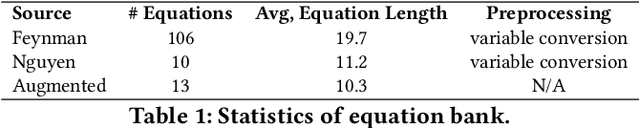
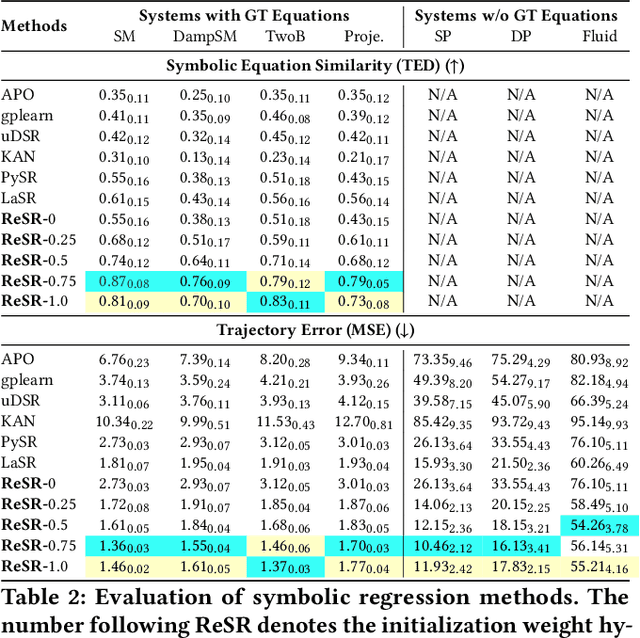
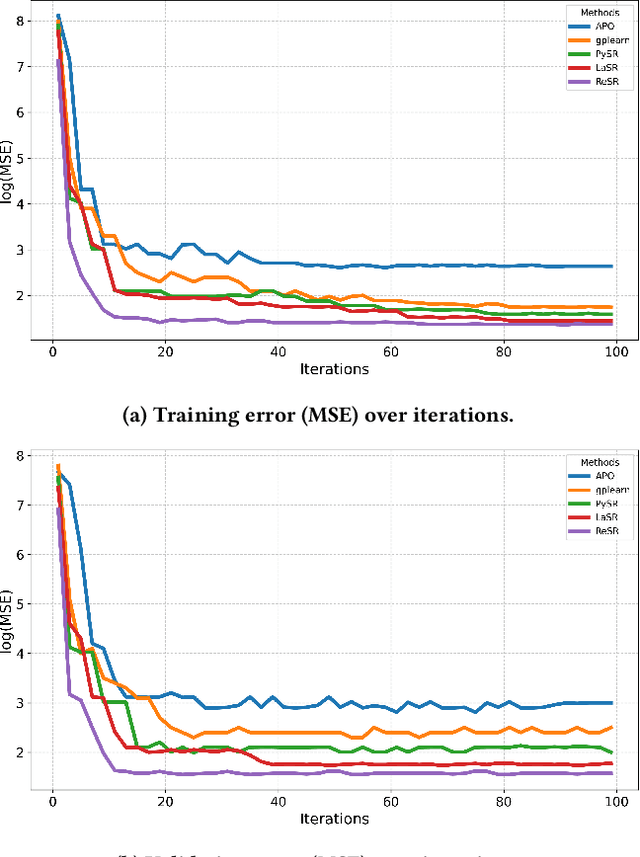
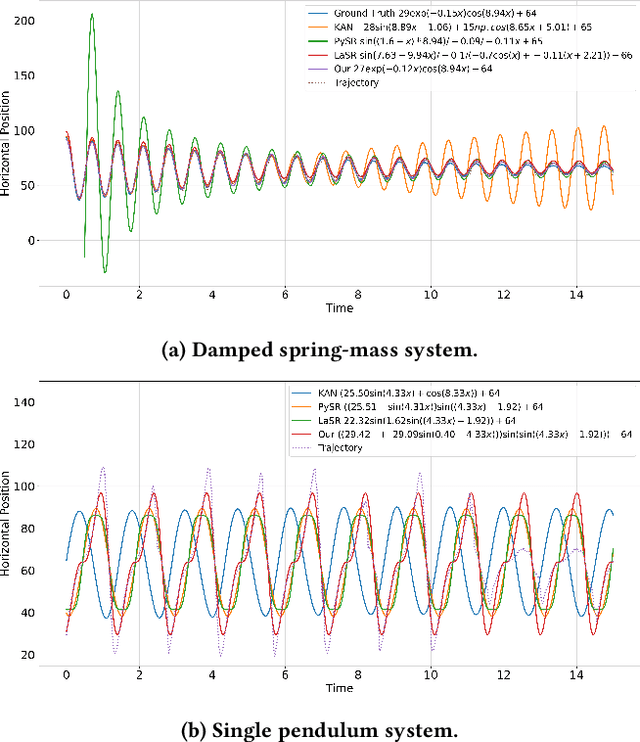
Recent advances in diffusion-based and autoregressive video generation models have achieved remarkable visual realism. However, these models typically lack accurate physical alignment, failing to replicate real-world dynamics in object motion. This limitation arises primarily from their reliance on learned statistical correlations rather than capturing mechanisms adhering to physical laws. To address this issue, we introduce a novel framework that integrates symbolic regression (SR) and trajectory-guided image-to-video (I2V) models for physics-grounded video forecasting. Our approach extracts motion trajectories from input videos, uses a retrieval-based pre-training mechanism to enhance symbolic regression, and discovers equations of motion to forecast physically accurate future trajectories. These trajectories then guide video generation without requiring fine-tuning of existing models. Evaluated on scenarios in Classical Mechanics, including spring-mass, pendulums, and projectile motions, our method successfully recovers ground-truth analytical equations and improves the physical alignment of generated videos over baseline methods.
Learning in Order! A Sequential Strategy to Learn Invariant Features for Multimodal Sentiment Analysis
Sep 05, 2024
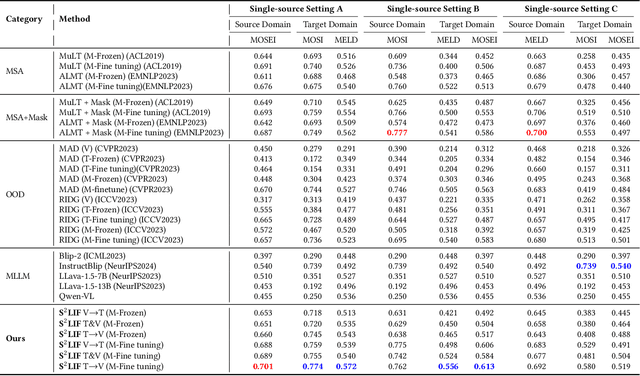


This work proposes a novel and simple sequential learning strategy to train models on videos and texts for multimodal sentiment analysis. To estimate sentiment polarities on unseen out-of-distribution data, we introduce a multimodal model that is trained either in a single source domain or multiple source domains using our learning strategy. This strategy starts with learning domain invariant features from text, followed by learning sparse domain-agnostic features from videos, assisted by the selected features learned in text. Our experimental results demonstrate that our model achieves significantly better performance than the state-of-the-art approaches on average in both single-source and multi-source settings. Our feature selection procedure favors the features that are independent to each other and are strongly correlated with their polarity labels. To facilitate research on this topic, the source code of this work will be publicly available upon acceptance.
Toward Robust Multimodal Learning using Multimodal Foundational Models
Jan 20, 2024Existing multimodal sentiment analysis tasks are highly rely on the assumption that the training and test sets are complete multimodal data, while this assumption can be difficult to hold: the multimodal data are often incomplete in real-world scenarios. Therefore, a robust multimodal model in scenarios with randomly missing modalities is highly preferred. Recently, CLIP-based multimodal foundational models have demonstrated impressive performance on numerous multimodal tasks by learning the aligned cross-modal semantics of image and text pairs, but the multimodal foundational models are also unable to directly address scenarios involving modality absence. To alleviate this issue, we propose a simple and effective framework, namely TRML, Toward Robust Multimodal Learning using Multimodal Foundational Models. TRML employs generated virtual modalities to replace missing modalities, and aligns the semantic spaces between the generated and missing modalities. Concretely, we design a missing modality inference module to generate virtual modaliites and replace missing modalities. We also design a semantic matching learning module to align semantic spaces generated and missing modalities. Under the prompt of complete modality, our model captures the semantics of missing modalities by leveraging the aligned cross-modal semantic space. Experiments demonstrate the superiority of our approach on three multimodal sentiment analysis benchmark datasets, CMU-MOSI, CMU-MOSEI, and MELD.
SHAPE: A Sample-adaptive Hierarchical Prediction Network for Medication Recommendation
Sep 09, 2023



Effectively medication recommendation with complex multimorbidity conditions is a critical task in healthcare. Most existing works predicted medications based on longitudinal records, which assumed the information transmitted patterns of learning longitudinal sequence data are stable and intra-visit medical events are serialized. However, the following conditions may have been ignored: 1) A more compact encoder for intra-relationship in the intra-visit medical event is urgent; 2) Strategies for learning accurate representations of the variable longitudinal sequences of patients are different. In this paper, we proposed a novel Sample-adaptive Hierarchical medicAtion Prediction nEtwork, termed SHAPE, to tackle the above challenges in the medication recommendation task. Specifically, we design a compact intra-visit set encoder to encode the relationship in the medical event for obtaining visit-level representation and then develop an inter-visit longitudinal encoder to learn the patient-level longitudinal representation efficiently. To endow the model with the capability of modeling the variable visit length, we introduce a soft curriculum learning method to assign the difficulty of each sample automatically by the visit length. Extensive experiments on a benchmark dataset verify the superiority of our model compared with several state-of-the-art baselines.
Medication Recommendation via Domain Knowledge Informed Deep Learning
May 31, 2023



Medication recommendation is a fundamental yet crucial branch of healthcare, which provides opportunities to support clinical physicians with more accurate medication prescriptions for patients with complex health conditions. Learning from electronic health records (EHR) to recommend medications is the most common way in previous studies. However, most of them neglect incorporating domain knowledge according to the clinical manifestations in the EHR of the patient. To address these issues, we propose a novel \textbf{D}omain \textbf{K}nowledge \textbf{I}nformed \textbf{Net}work (DKINet) to integrate domain knowledge with observable clinical manifestations of the patient, which is the first dynamic domain knowledge informed framework toward medication recommendation. In particular, we first design a knowledge-driven encoder to capture the domain information and then develop a data-driven encoder to integrate domain knowledge into the observable EHR. To endow the model with the capability of temporal decision, we design an explicit medication encoder for learning the longitudinal dependence of the patient. Extensive experiments on three publicly available datasets verify the superiority of our method. The code will be public upon acceptance.