 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in Order! A Sequential Strategy to Learn Invariant Features for Multimodal Sentiment Analysis
Paper and Code
Sep 05, 2024
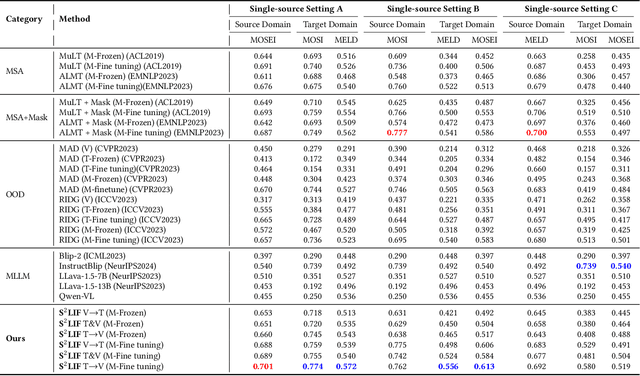


This work proposes a novel and simple sequential learning strategy to train models on videos and texts for multimodal sentiment analysis. To estimate sentiment polarities on unseen out-of-distribution data, we introduce a multimodal model that is trained either in a single source domain or multiple source domains using our learning strategy. This strategy starts with learning domain invariant features from text, followed by learning sparse domain-agnostic features from videos, assisted by the selected features learned in text. Our experimental results demonstrate that our model achieves significantly better performance than the state-of-the-art approaches on average in both single-source and multi-source settings. Our feature selection procedure favors the features that are independent to each other and are strongly correlated with their polarity labels. To facilitate research on this topic, the source code of this work will be publicly available upon acceptance.