 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Gibson: A Benchmark for Interactive Navigation in Cluttered Environments
Oct 30, 2019
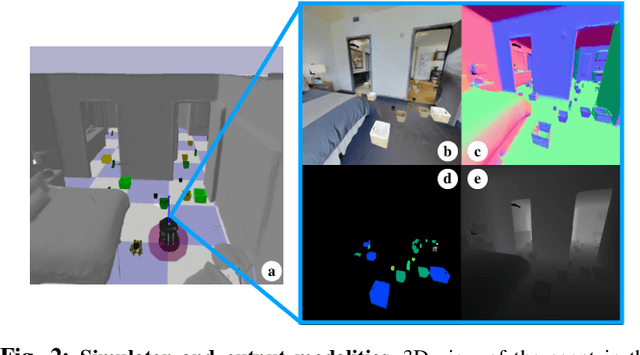
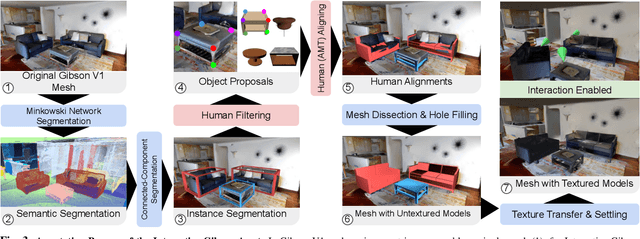

We present Interactive Gibson, the first comprehensive benchmark for training and evaluating Interactive Navigation: robot navigation strategies where physical interaction with objects is allowed and even encouraged to accomplish a task. For example, the robot can move objects if needed in order to clear a path leading to the goal location. Our benchmark comprises two novel elements: 1) a new experimental setup, the Interactive Gibson Environment, which simulates high fidelity visuals of indoor scenes, and high fidelity physical dynamics of the robot and common objects found in these scenes; 2) a set of Interactive Navigation metrics which allows one to study the interplay between navigation and physical interaction. We present and evaluate multiple learning-based baselines in Interactive Gibson, and provide insights into regimes of navigation with different trade-offs between navigation path efficiency and disturbance of surrounding objects. We make our benchmark publicly available(https://sites.google.com/view/interactivegibsonenv) and encourage researchers from all disciplines in robotics (e.g. planning, learning, control) to propose, evaluate, and compare their Interactive Navigation solutions in Interactive Gibson.
Situational Fusion of Visual Representation for Visual Navigation
Aug 24, 2019

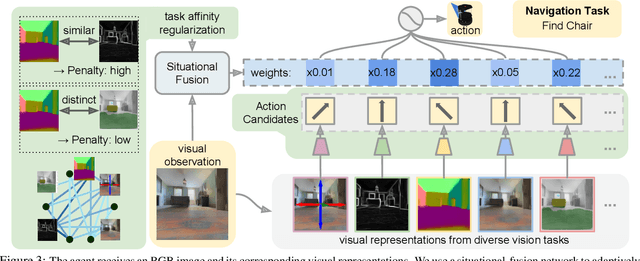
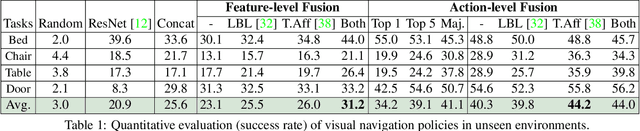
A complex visual navigation task puts an agent in different situations which call for a diverse range of visual perception abilities. For example, to "go to the nearest chair'', the agent might need to identify a chair in a living room using semantics, follow along a hallway using vanishing point cues, and avoid obstacles using depth. Therefore, utilizing the appropriate visual perception abilities based on a situational understanding of the visual environment can empower these navigation models in unseen visual environments. We propose to train an agent to fuse a large set of visual representations that correspond to diverse visual perception abilities. To fully utilize each representation, we develop an action-level representation fusion scheme, which predicts an action candidate from each representation and adaptively consolidate these action candidates into the final action. Furthermore, we employ a data-driven inter-task affinity regularization to reduce redundancies and improve generalization. Our approach leads to a significantly improved performance in novel environments over ImageNet-pretrained baseline and other fusion methods.
Visual Forecasting by Imitating Dynamics in Natural Sequences
Aug 19, 2017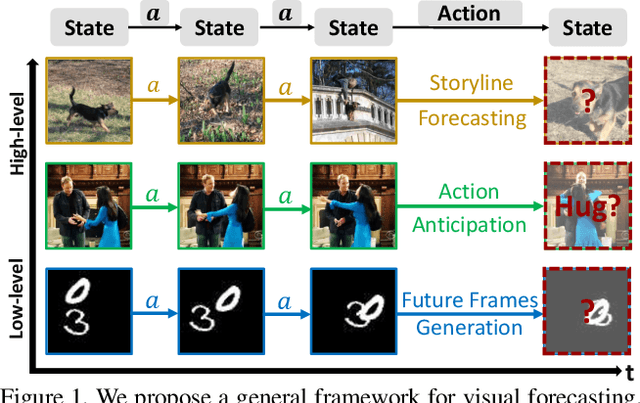

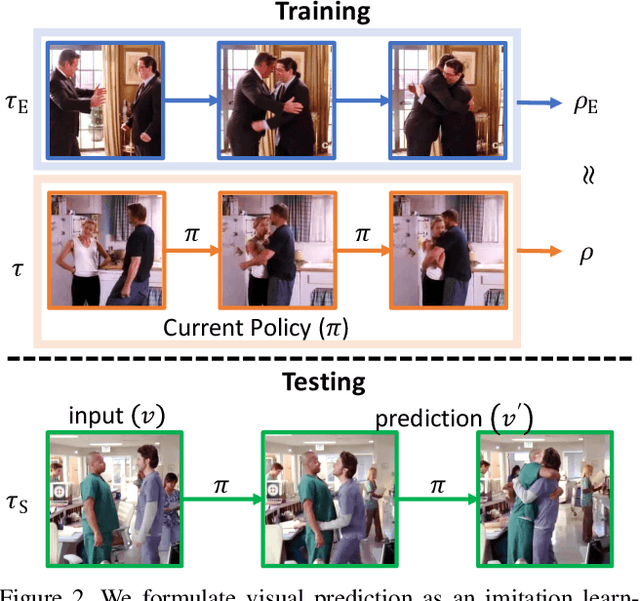

We introduce a general framework for visual forecasting, which directly imitates visual sequences without additional supervision. As a result, our model can be applied at several semantic levels and does not require any domain knowledge or handcrafted features. We achieve this by formulating visual forecasting as an inverse reinforcement learning (IRL) problem, and directly imitate the dynamics in natural sequences from their raw pixel values. The key challenge is the high-dimensional and continuous state-action space that prohibits the application of previous IRL algorithms. We address this computational bottleneck by extending recent progress in model-free imitation with trainable deep feature representations, which (1) bypasses the exhaustive state-action pair visits in dynamic programming by using a dual formulation and (2) avoids explicit state sampling at gradient computation using a deep feature reparametrization. This allows us to apply IRL at scale and directly imitate the dynamics in high-dimensional continuous visual sequences from the raw pixel values. We evaluate our approach at three different level-of-abstraction, from low level pixels to higher level semantics: future frame generation, action anticipation, visual story forecasting. At all levels, our approach outperforms existing methods.