 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximately Equivariant Neural Processes
Jun 19, 2024
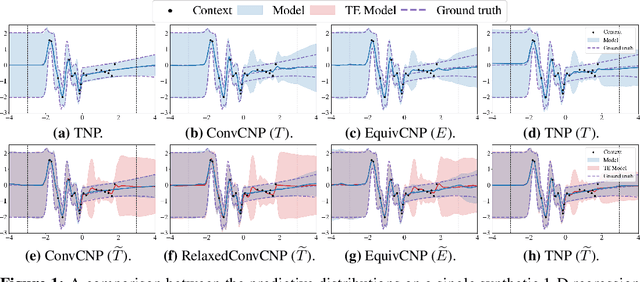


Equivariant deep learning architectures exploit symmetries in learning problems to improve the sample efficiency of neural-network-based models and their ability to generalise. However, when modelling real-world data, learning problems are often not exactly equivariant, but only approximately. For example, when estimating the global temperature field from weather station observations, local topographical features like mountains break translation equivariance. In these scenarios, it is desirable to construct architectures that can flexibly depart from exact equivariance in a data-driven way. In this paper, we develop a general approach to achieving this using existing equivariant architectures. Our approach is agnostic to both the choice of symmetry group and model architecture, making it widely applicable. We consider the use of approximately equivariant architectures in neural processes (NPs), a popular family of meta-learning models. We demonstrate the effectiveness of our approach on a number of synthetic and real-world regression experiments, demonstrating that approximately equivariant NP models can outperform both their non-equivariant and strictly equivariant counterparts.
Challenges and Pitfalls of Bayesian Unlearning
Jul 07, 2022
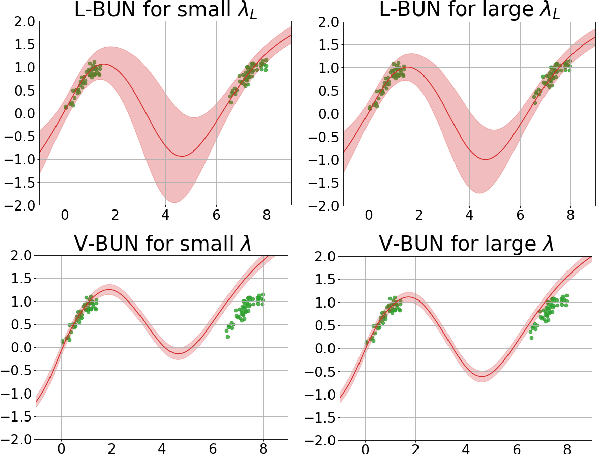
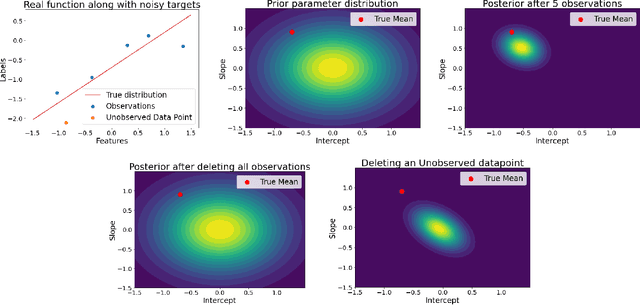
Machine unlearning refers to the task of removing a subset of training data, thereby removing its contributions to a trained model. Approximate unlearning are one class of methods for this task which avoid the need to retrain the model from scratch on the retained data. Bayes' rule can be used to cast approximate unlearning as an inference problem where the objective is to obtain the updated posterior by dividing out the likelihood of deleted data. However this has its own set of challenges as one often doesn't have access to the exact posterior of the model parameters. In this work we examine the use of the Laplace approximation and Variational Inference to obtain the updated posterior. With a neural network trained for a regression task as the guiding example, we draw insights on the applicability of Bayesian unlearning in practical scenarios.
Efficient Gaussian Neural Processes for Regression
Aug 24, 2021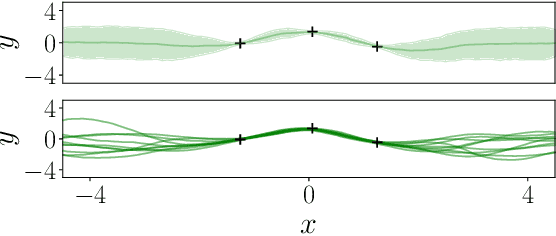
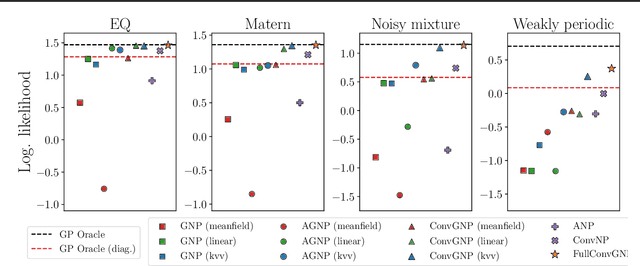
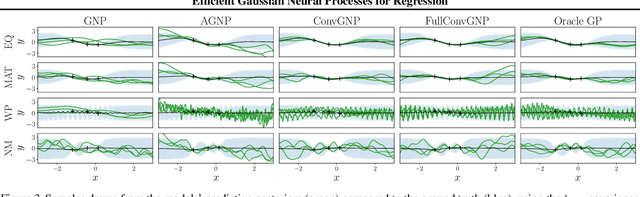
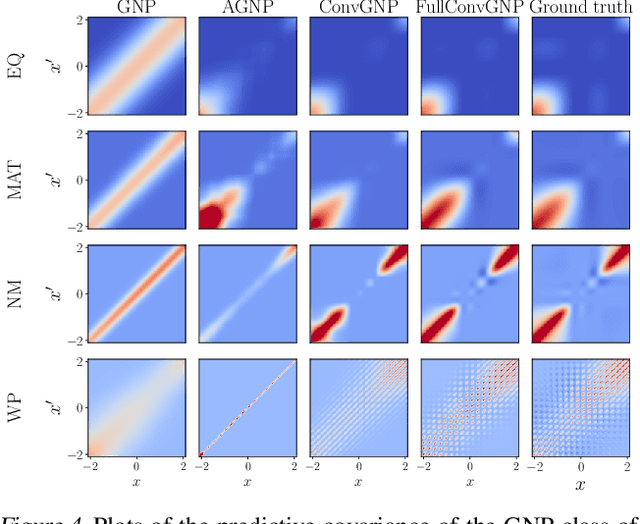
Conditional Neural Processes (CNP; Garnelo et al., 2018) are an attractive family of meta-learning models which produce well-calibrated predictions, enable fast inference at test time, and are trainable via a simple maximum likelihood procedure. A limitation of CNPs is their inability to model dependencies in the outputs. This significantly hurts predictive performance and renders it impossible to draw coherent function samples, which limits the applicability of CNPs in down-stream applications and decision making. Neural Processes (NPs; Garnelo et al., 2018) attempt to alleviate this issue by using latent variables, relying on these to model output dependencies, but introduces difficulties stemming from approximate inference. One recent alternative (Bruinsma et al.,2021), which we refer to as the FullConvGNP, models dependencies in the predictions while still being trainable via exact maximum-likelihood. Unfortunately, the FullConvGNP relies on expensive 2D-dimensional convolutions, which limit its applicability to only one-dimensional data. In this work, we present an alternative way to model output dependencies which also lends itself maximum likelihood training but, unlike the FullConvGNP, can be scaled to two- and three-dimensional data. The proposed models exhibit good performance in synthetic experiments.
GP-ALPS: Automatic Latent Process Selection for Multi-Output Gaussian Process Models
Dec 17, 2019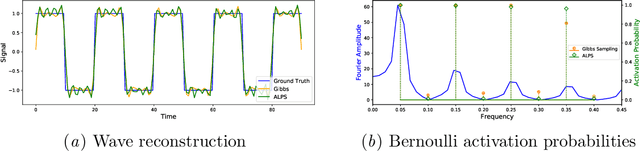
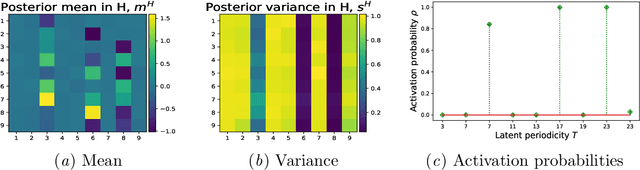
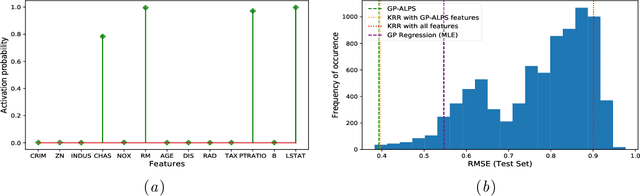
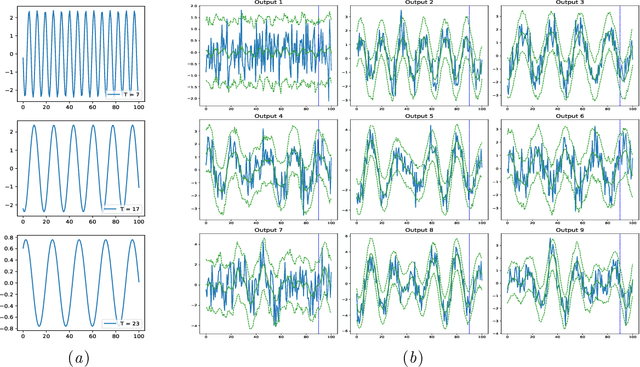
A simple and widely adopted approach to extend Gaussian processes (GPs) to multiple outputs is to model each output as a linear combination of a collection of shared, unobserved latent GPs. An issue with this approach is choosing the number of latent processes and their kernels. These choices are typically done manually, which can be time consuming and prone to human biases. We propose Gaussian Process Automatic Latent Process Selection (GP-ALPS), which automatically chooses the latent processes by turning off those that do not meaningfully contribute to explaining the data. We develop a variational inference scheme, assess the quality of the variational posterior by comparing it against the gold standard MCMC, and demonstrate the suitability of GP-ALPS in a set of preliminary experiments.
Learning Causally-Generated Stationary Time Series
Feb 22, 2018
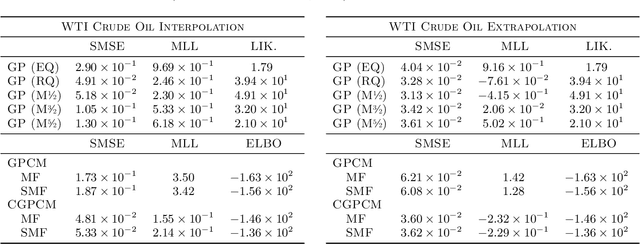


We present the Causal Gaussian Process Convolution Model (CGPCM), a doubly nonparametric model for causal, spectrally complex dynamical phenomena. The CGPCM is a generative model in which white noise is passed through a causal, nonparametric-window moving-average filter, a construction that we show to be equivalent to a Gaussian process with a nonparametric kernel that is biased towards causally-generated signals. We develop enhanced variational inference and learning schemes for the CGPCM and its previous acausal variant, the GPCM (Tobar et al., 2015b), that significantly improve statistical accuracy. These modelling and inferential contributions are demonstrated on a range of synthetic and real-world signals.
The Gaussian Process Autoregressive Regression Model (GPAR)
Feb 21, 2018
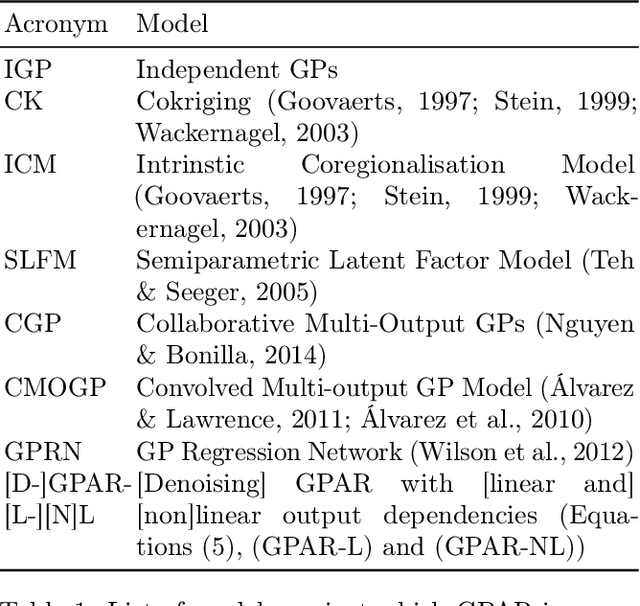
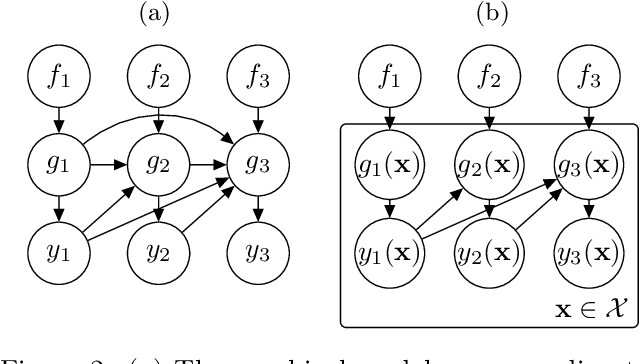
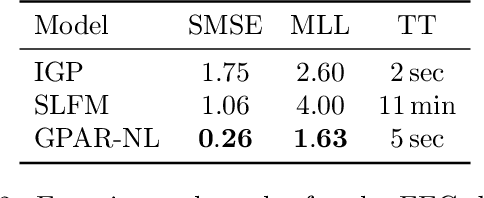
Multi-output regression models must exploit dependencies between outputs to maximise predictive performance. The application of Gaussian processes (GPs) to this setting typically yields models that are computationally demanding and have limited representational power. We present the Gaussian Process Autoregressive Regression (GPAR) model, a scalable multi-output GP model that is able to capture nonlinear, possibly input-varying, dependencies between outputs in a simple and tractable way: the product rule is used to decompose the joint distribution over the outputs into a set of conditionals, each of which is modelled by a standard GP. GPAR's efficacy is demonstrated on a variety of synthetic and real-world problems, outperforming existing GP models and achieving state-of-the-art performance on the tasks with existing benchmarks.