 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to See for Long-term Traffic Data Collection on Power-constrained Devices
Jan 25, 2024



Collecting traffic data is crucial for transportation systems and urban planning, and is often more desirable through easy-to-deploy but power-constrained devices, due to the unavailability or high cost of power and network infrastructure. The limited power means an inevitable trade-off between data collection duration and accuracy/resolution. We introduce a novel learning-based framework that strategically decides observation timings for battery-powered devices and reconstructs the full data stream from sparsely sampled observations, resulting in minimal performance loss and a significantly prolonged system lifetime. Our framework comprises a predictor, a controller, and an estimator. The predictor utilizes historical data to forecast future trends within a fixed time horizon. The controller uses the forecasts to determine the next optimal timing for data collection. Finally, the estimator reconstructs the complete data profile from the sampled observations. We evaluate the performance of the proposed method on PeMS data by an RNN (Recurrent Neural Network) predictor and estimator, and a DRQN (Deep Recurrent Q-Network) controller, and compare it against the baseline that uses Kalman filter and uniform sampling. The results indicate that our method outperforms the baseline, primarily due to the inclusion of more representative data points in the profile, resulting in an overall 10\% improvement in estimation accuracy. Source code will be publicly available.
AutoEncoding Tree for City Generation and Applications
Sep 27, 2023



City modeling and generation have attracted an increased interest in various applications, including gaming, urban planning, and autonomous driving. Unlike previous works focused on the generation of single objects or indoor scenes, the huge volumes of spatial data in cities pose a challenge to the generative models. Furthermore, few publicly available 3D real-world city datasets also hinder the development of methods for city generation. In this paper, we first collect over 3,000,000 geo-referenced objects for the city of New York, Zurich, Tokyo, Berlin, Boston and several other large cities. Based on this dataset, we propose AETree, a tree-structured auto-encoder neural network, for city generation. Specifically, we first propose a novel Spatial-Geometric Distance (SGD) metric to measure the similarity between building layouts and then construct a binary tree over the raw geometric data of building based on the SGD metric. Next, we present a tree-structured network whose encoder learns to extract and merge spatial information from bottom-up iteratively. The resulting global representation is reversely decoded for reconstruction or generation. To address the issue of long-dependency as the level of the tree increases, a Long Short-Term Memory (LSTM) Cell is employed as a basic network element of the proposed AETree. Moreover, we introduce a novel metric, Overlapping Area Ratio (OAR), to quantitatively evaluate the generation results. Experiments on the collected dataset demonstrate the effectiveness of the proposed model on 2D and 3D city generation. Furthermore, the latent features learned by AETree can serve downstream urban planning applications.
Simultaneous Navigation and Construction Benchmarking Environments
Mar 31, 2021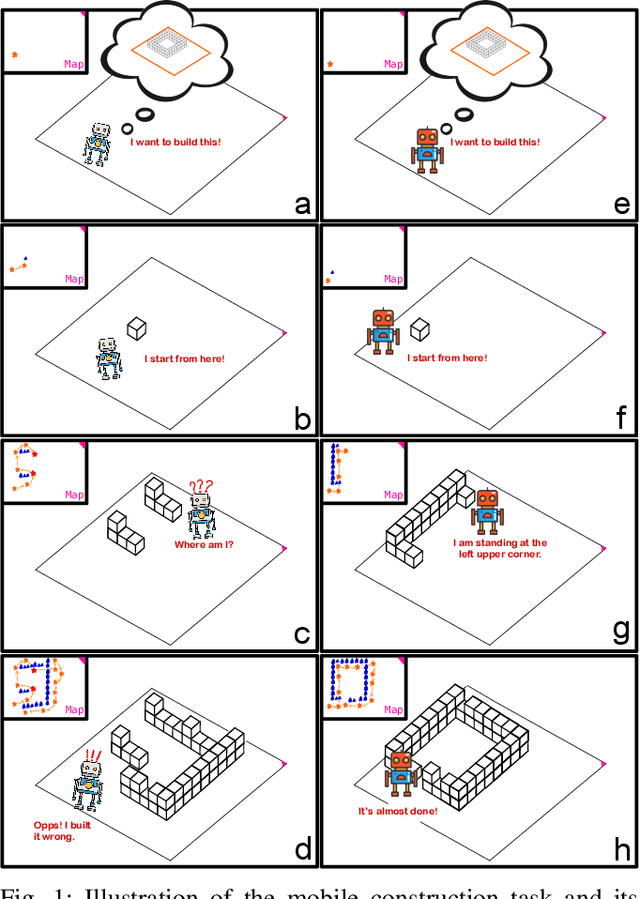
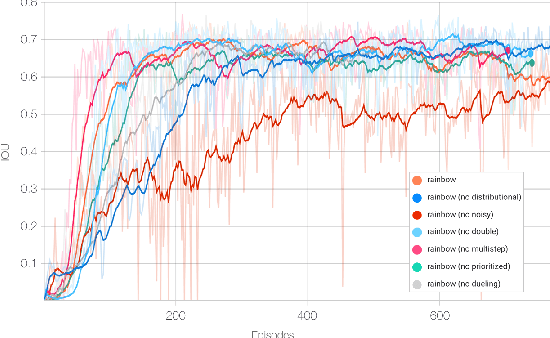
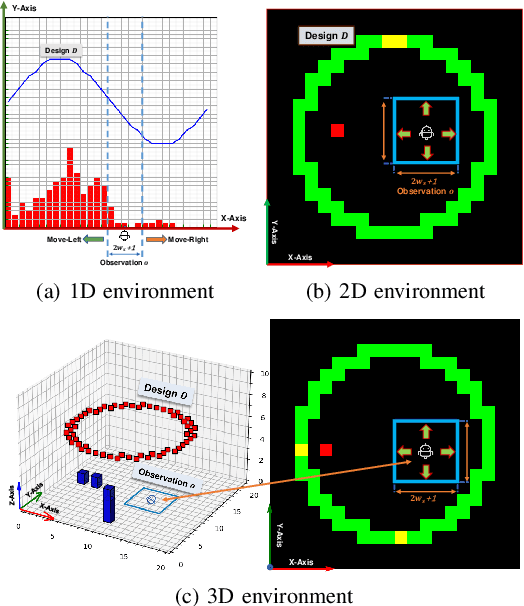
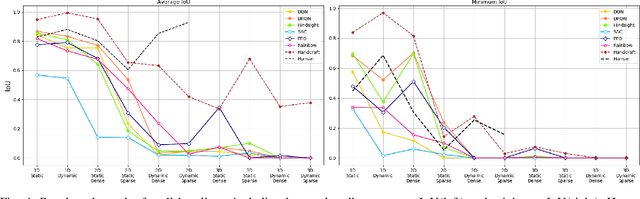
We need intelligent robots for mobile construction, the process of navigating in an environment and modifying its structure according to a geometric design. In this task, a major robot vision and learning challenge is how to exactly achieve the design without GPS, due to the difficulty caused by the bi-directional coupling of accurate robot localization and navigation together with strategic environment manipulation. However, many existing robot vision and learning tasks such as visual navigation and robot manipulation address only one of these two coupled aspects. To stimulate the pursuit of a generic and adaptive solution, we reasonably simplify mobile construction as a partially observable Markov decision process (POMDP) in 1/2/3D grid worlds and benchmark the performance of a handcrafted policy with basic localization and planning, and state-of-the-art deep reinforcement learning (RL) methods. Our extensive experiments show that the coupling makes this problem very challenging for those methods, and emphasize the need for novel task-specific solutions.
SPARE3D: A Dataset for SPAtial REasoning on Three-View Line Drawings
Mar 31, 2020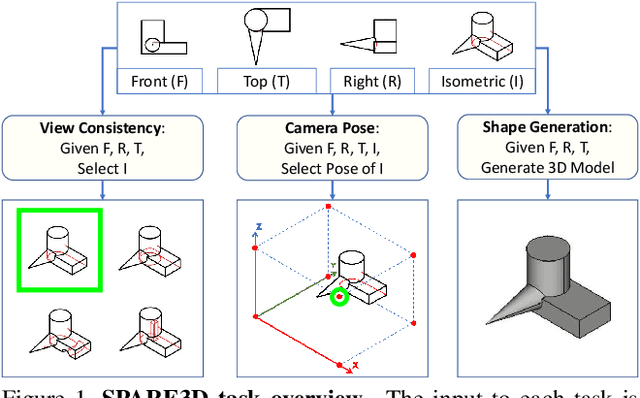
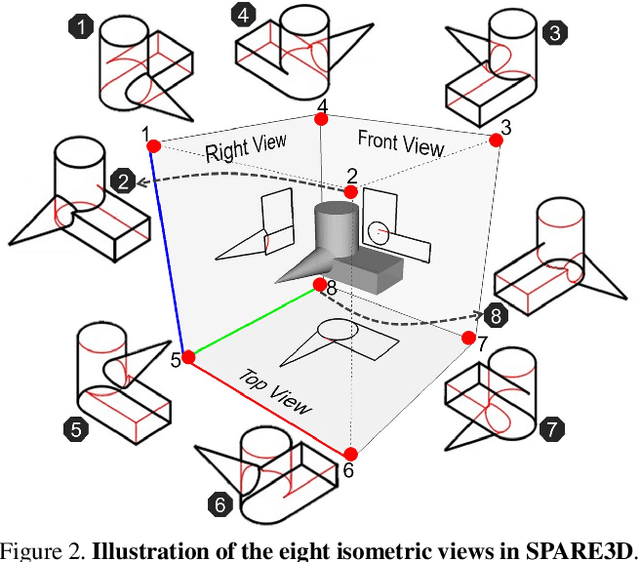

Spatial reasoning is an important component of human intelligence. We can imagine the shapes of 3D objects and reason about their spatial relations by merely looking at their three-view line drawings in 2D, with different levels of competence. Can deep networks be trained to perform spatial reasoning tasks? How can we measure their "spatial intelligence"? To answer these questions, we present the SPARE3D dataset. Based on cognitive science and psychometrics, SPARE3D contains three types of 2D-3D reasoning tasks on view consistency, camera pose, and shape generation, with increasing difficulty. We then design a method to automatically generate a large number of challenging questions with ground truth answers for each task. They are used to provide supervision for training our baseline models using state-of-the-art architectures like ResNet. Our experiments show that although convolutional networks have achieved superhuman performance in many visual learning tasks, their spatial reasoning performance in SPARE3D is almost equal to random guesses. We hope SPARE3D can stimulate new problem formulations and network designs for spatial reasoning to empower intelligent robots to operate effectively in the 3D world via 2D sensors. The dataset and code are available at https://ai4ce.github.io/SPARE3D.