 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-norm for Unsupervised Probing of Knowledge
Jul 26, 2024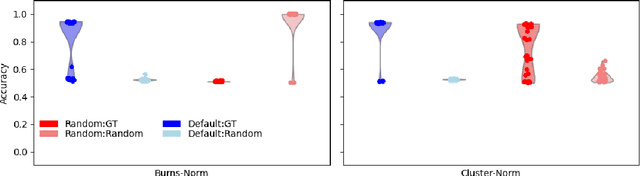

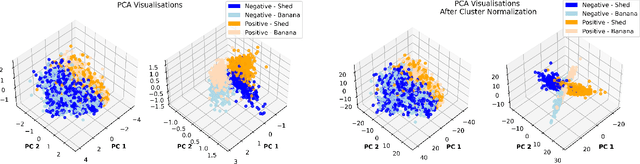

The deployment of language models brings challenges in generating reliable information, especially when these models are fine-tuned using human preferences. To extract encoded knowledge without (potentially) biased human labels, unsupervised probing techniques like Contrast-Consistent Search (CCS) have been developed (Burns et al., 2022). However, salient but unrelated features in a given dataset can mislead these probes (Farquhar et al., 2023). Addressing this, we propose a cluster normalization method to minimize the impact of such features by clustering and normalizing activations of contrast pairs before applying unsupervised probing techniques. While this approach does not address the issue of differentiating between knowledge in general and simulated knowledge - a major issue in the literature of latent knowledge elicitation (Christiano et al., 2021) - it significantly improves the ability of unsupervised probes to identify the intended knowledge amidst distractions.
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023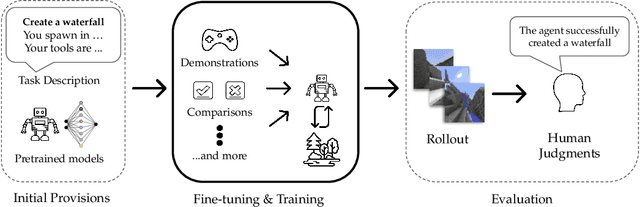

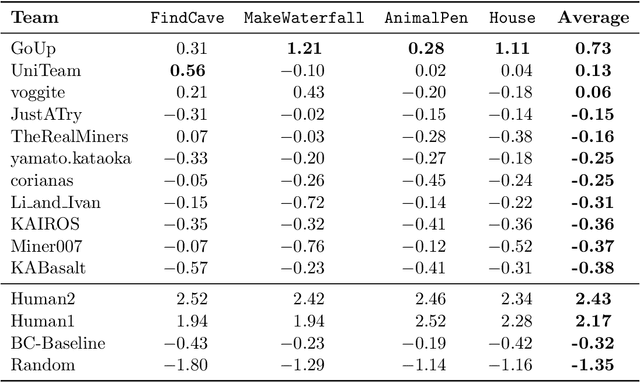
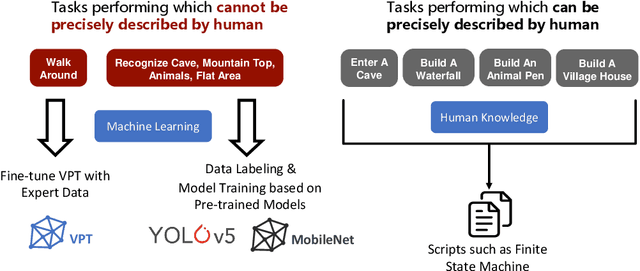
To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.
AIFB-WebScience at SemEval-2022 Task 12: Relation Extraction First -- Using Relation Extraction to Identify Entities
Mar 10, 2022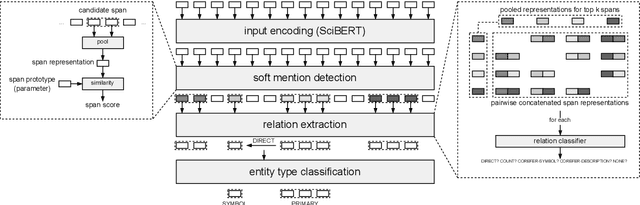
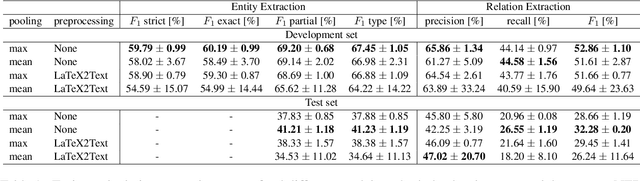


In this paper, we present an end-to-end joint entity and relation extraction approach based on transformer-based language models. We apply the model to the task of linking mathematical symbols to their descriptions in LaTeX documents. In contrast to existing approaches, which perform entity and relation extraction in sequence, our system incorporates information from relation extraction into entity extraction. This means that the system can be trained even on data sets where only a subset of all valid entity spans is annotated. We provide an extensive evaluation of the proposed system and its strengths and weaknesses. Our approach, which can be scaled dynamically in computational complexity at inference time, produces predictions with high precision and reaches 3rd place in the leaderboard of SemEval-2022 Task 12. For inputs in the domain of physics and math, it achieves high relation extraction macro f1 scores of 95.43% and 79.17%, respectively. The code used for training and evaluating our models is available at: https://github.com/nicpopovic/RE1st