 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effects of Hallucinations in Synthetic Training Data for Relation Extraction
Oct 10, 2024
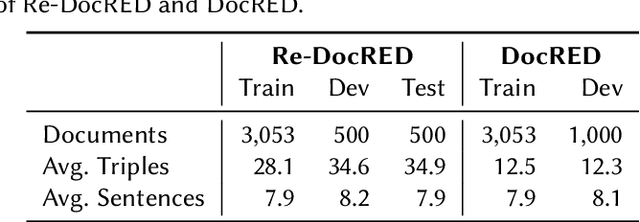
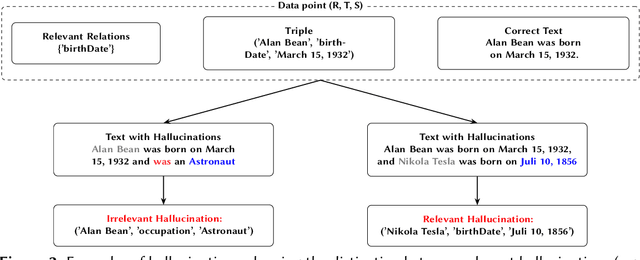
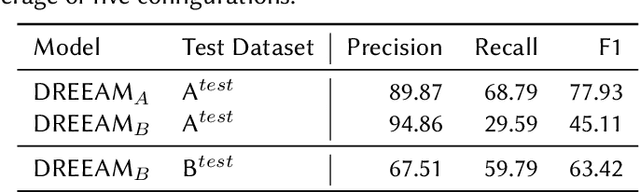
Relation extraction is crucial for constructing knowledge graphs, with large high-quality datasets serving as the foundation for training, fine-tuning, and evaluating models. Generative data augmentation (GDA) is a common approach to expand such datasets. However, this approach often introduces hallucinations, such as spurious facts, whose impact on relation extraction remains underexplored. In this paper, we examine the effects of hallucinations on the performance of relation extraction on the document and sentence levels. Our empirical study reveals that hallucinations considerably compromise the ability of models to extract relations from text, with recall reductions between 19.1% and 39.2%. We identify that relevant hallucinations impair the model's performance, while irrelevant hallucinations have a minimal impact. Additionally, we develop methods for the detection of hallucinations to improve data quality and model performance. Our approaches successfully classify texts as either 'hallucinated' or 'clean,' achieving high F1-scores of 83.8% and 92.2%. These methods not only assist in removing hallucinations but also help in estimating their prevalence within datasets, which is crucial for selecting high-quality data. Overall, our work confirms the profound impact of relevant hallucinations on the effectiveness of relation extraction models.
Vocab-Expander: A System for Creating Domain-Specific Vocabularies Based on Word Embeddings
Aug 07, 2023In this paper, we propose Vocab-Expander at https://vocab-expander.com, an online tool that enables end-users (e.g., technology scouts) to create and expand a vocabulary of their domain of interest. It utilizes an ensemble of state-of-the-art word embedding techniques based on web text and ConceptNet, a common-sense knowledge base, to suggest related terms for already given terms. The system has an easy-to-use interface that allows users to quickly confirm or reject term suggestions. Vocab-Expander offers a variety of potential use cases, such as improving concept-based information retrieval in technology and innovation management, enhancing communication and collaboration within organizations or interdisciplinary projects, and creating vocabularies for specific courses in education.
Few-Shot Document-Level Relation Extraction
May 04, 2022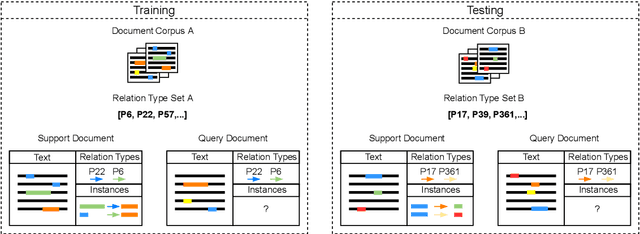



We present FREDo, a few-shot document-level relation extraction (FSDLRE) benchmark. As opposed to existing benchmarks which are built on sentence-level relation extraction corpora, we argue that document-level corpora provide more realism, particularly regarding none-of-the-above (NOTA) distributions. Therefore, we propose a set of FSDLRE tasks and construct a benchmark based on two existing supervised learning data sets, DocRED and sciERC. We adapt the state-of-the-art sentence-level method MNAV to the document-level and develop it further for improved domain adaptation. We find FSDLRE to be a challenging setting with interesting new characteristics such as the ability to sample NOTA instances from the support set. The data, code, and trained models are available online (https://github.com/nicpopovic/FREDo).
AIFB-WebScience at SemEval-2022 Task 12: Relation Extraction First -- Using Relation Extraction to Identify Entities
Mar 10, 2022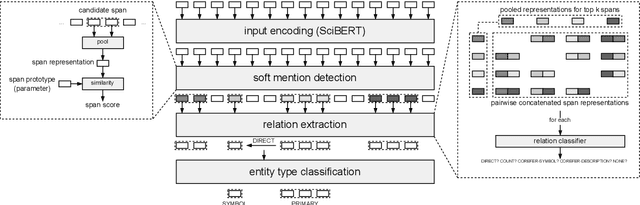
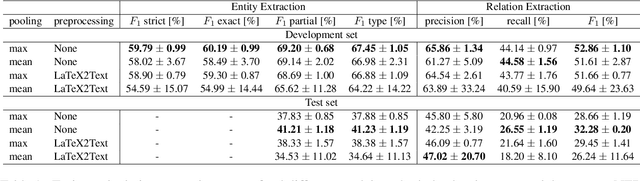


In this paper, we present an end-to-end joint entity and relation extraction approach based on transformer-based language models. We apply the model to the task of linking mathematical symbols to their descriptions in LaTeX documents. In contrast to existing approaches, which perform entity and relation extraction in sequence, our system incorporates information from relation extraction into entity extraction. This means that the system can be trained even on data sets where only a subset of all valid entity spans is annotated. We provide an extensive evaluation of the proposed system and its strengths and weaknesses. Our approach, which can be scaled dynamically in computational complexity at inference time, produces predictions with high precision and reaches 3rd place in the leaderboard of SemEval-2022 Task 12. For inputs in the domain of physics and math, it achieves high relation extraction macro f1 scores of 95.43% and 79.17%, respectively. The code used for training and evaluating our models is available at: https://github.com/nicpopovic/RE1st