 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-norm for Unsupervised Probing of Knowledge
Paper and Code
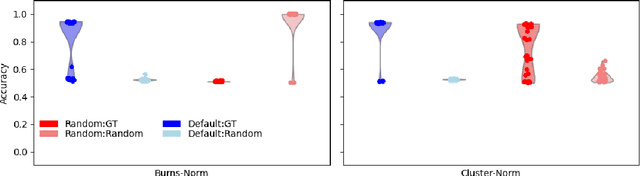

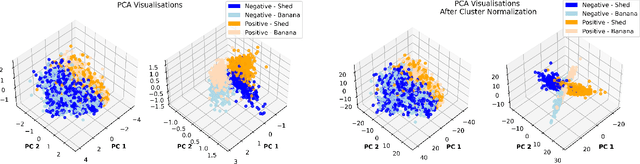

The deployment of language models brings challenges in generating reliable information, especially when these models are fine-tuned using human preferences. To extract encoded knowledge without (potentially) biased human labels, unsupervised probing techniques like Contrast-Consistent Search (CCS) have been developed (Burns et al., 2022). However, salient but unrelated features in a given dataset can mislead these probes (Farquhar et al., 2023). Addressing this, we propose a cluster normalization method to minimize the impact of such features by clustering and normalizing activations of contrast pairs before applying unsupervised probing techniques. While this approach does not address the issue of differentiating between knowledge in general and simulated knowledge - a major issue in the literature of latent knowledge elicitation (Christiano et al., 2021) - it significantly improves the ability of unsupervised probes to identify the intended knowledge amidst distractions.