 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePithTrain: A Compact and Agent-Native MoE Training System
May 29, 2026Mixture-of-Experts (MoE) has become the dominant architecture for frontier language models. To meet this demand, production frameworks have built optimized MoE training stacks over years of engineering effort. Yet evolving these stacks for new architectures and system optimizations remains expensive. With the rise of AI coding agents, they could automate parts of training-framework development and accelerate this evolution. But applying them to these existing frameworks carries hidden costs, invisible to today's throughput-only evaluations. We name this missing dimension agent-task efficiency (ATE): the cost of using coding agents to understand, operate, and extend a framework. Grounded in four agent-native design principles, we build PithTrain, a compact, agent-native MoE training framework. We further introduce ATE-Bench, covering real-world training-framework tasks. Our evaluation shows PithTrain matches the throughput of production frameworks, and on ATE-Bench, PithTrain enables higher agent-task efficiency, with up to 62% fewer Agent Turns and 64% less Active GPU Time.
Event Tensor: A Unified Abstraction for Compiling Dynamic Megakernel
Apr 14, 2026Modern GPU workloads, especially large language model (LLM) inference, suffer from kernel launch overheads and coarse synchronization that limit inter-kernel parallelism. Recent megakernel techniques fuse multiple operators into a single persistent kernel to eliminate launch gaps and expose inter-kernel parallelism, but struggle to handle dynamic shapes and data-dependent computation in real workloads. We present Event Tensor, a unified compiler abstraction for dynamic megakernels. Event Tensor encodes dependencies between tiled tasks, and enables first-class support for both shape and data-dependent dynamism. Built atop this abstraction, our Event Tensor Compiler (ETC) applies static and dynamic scheduling transformations to generate high-performance persistent kernels. Evaluations show that ETC achieves state-of-the-art LLM serving latency while significantly reducing system warmup overhead.
LithOS: An Operating System for Efficient Machine Learning on GPUs
Apr 21, 2025The surging demand for GPUs in datacenters for machine learning (ML) has made efficient GPU utilization crucial. However, meeting the diverse needs of ML models while optimizing resource usage is challenging. To enable transparent, fine-grained GPU management that maximizes utilization and energy efficiency while maintaining strong isolation, an operating system (OS) approach is needed. This paper introduces LithOS, a first step toward a GPU OS. LithOS includes the following new abstractions and mechanisms for efficient GPU resource management: (i) a novel TPC Scheduler that supports spatial scheduling at the granularity of individual TPCs, unlocking efficient TPC stealing between workloads; (ii) transparent kernel atomization to reduce head-of-line blocking and enable dynamic resource reallocation mid-execution; (iii) a lightweight hardware right-sizing mechanism that determines the minimal TPC resources needed per atom; and (iv) a transparent power management mechanism that reduces power consumption based on in-flight work behavior. We implement LithOS in Rust and evaluate its performance across extensive ML environments, comparing it to state-of-the-art solutions from NVIDIA and prior research. For inference stacking, LithOS reduces tail latencies by 13x compared to MPS; compared to the best SotA, it reduces tail latencies by 3x while improving aggregate throughput by 1.6x. In hybrid inference-training stacking, LithOS reduces tail latencies by 4.7x compared to MPS; compared to the best SotA, it reduces tail latencies 1.18x while improving aggregate throughput by 1.35x. Finally, for a modest performance hit under 4%, LithOS's right-sizing provides a quarter of GPU capacity savings on average, while for a 7% hit, its power management yields a quarter of a GPU's energy savings. Overall, LithOS increases GPU efficiency, establishing a foundation for future OS research on GPUs.
Relax: Composable Abstractions for End-to-End Dynamic Machine Learning
Nov 01, 2023



Dynamic shape computations have become critical in modern machine learning workloads, especially in emerging large language models. The success of these models has driven demand for deploying them to a diverse set of backend environments. In this paper, we present Relax, a compiler abstraction for optimizing end-to-end dynamic machine learning workloads. Relax introduces first-class symbolic shape annotations to track dynamic shape computations globally across the program. It also introduces a cross-level abstraction that encapsulates computational graphs, loop-level tensor programs, and library calls in a single representation to enable cross-level optimizations. We build an end-to-end compilation framework using the proposed approach to optimize dynamic shape models. Experimental results on large language models show that Relax delivers performance competitive with state-of-the-art hand-optimized systems across platforms and enables deployment of emerging dynamic models to a broader set of environments, including mobile phones, embedded devices, and web browsers.
ACRoBat: Optimizing Auto-batching of Dynamic Deep Learning at Compile Time
May 17, 2023



Dynamic control flow is an important technique often used to design expressive and efficient deep learning computations for applications such as text parsing, machine translation, exiting early out of deep models and so on. However, the resulting control flow divergence makes batching, an important performance optimization, difficult to perform manually. In this paper, we present ACRoBat, a framework that enables efficient automatic batching for dynamic deep learning computations by performing hybrid static+dynamic compiler optimizations and end-to-end tensor code generation. ACRoBat performs up to 8.5X better than DyNet, a state-of-the-art framework for automatic batching, on an Nvidia GeForce RTX 3070 GPU.
ED-Batch: Efficient Automatic Batching of Dynamic Neural Networks via Learned Finite State Machines
Feb 08, 2023



Batching has a fundamental influence on the efficiency of deep neural network (DNN) execution. However, for dynamic DNNs, efficient batching is particularly challenging as the dataflow graph varies per input instance. As a result, state-of-the-art frameworks use heuristics that result in suboptimal batching decisions. Further, batching puts strict restrictions on memory adjacency and can lead to high data movement costs. In this paper, we provide an approach for batching dynamic DNNs based on finite state machines, which enables the automatic discovery of batching policies specialized for each DNN via reinforcement learning. Moreover, we find that memory planning that is aware of the batching policy can save significant data movement overheads, which is automated by a PQ tree-based algorithm we introduce. Experimental results show that our framework speeds up state-of-the-art frameworks by on average 1.15x, 1.39x, and 2.45x for chain-based, tree-based, and lattice-based DNNs across CPU and GPU.
The CoRa Tensor Compiler: Compilation for Ragged Tensors with Minimal Padding
Oct 29, 2021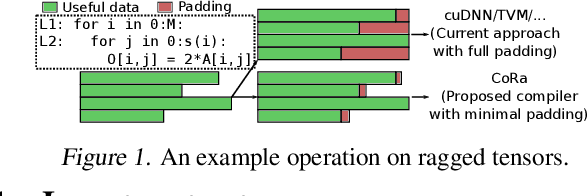
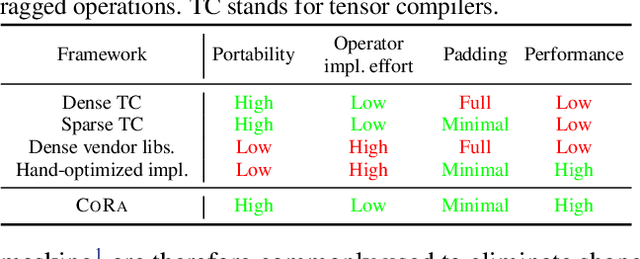
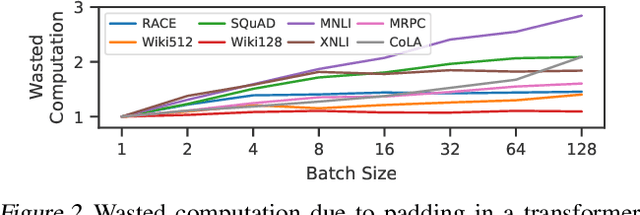
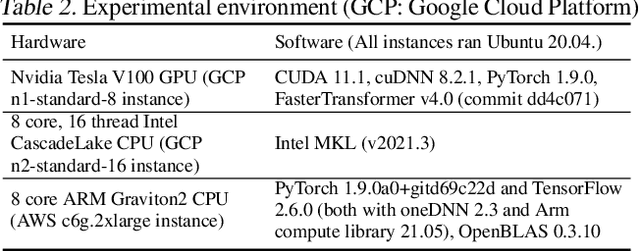
There is often variation in the shape and size of input data used for deep learning. In many cases, such data can be represented using tensors with non-uniform shapes, or ragged tensors. Due to limited and non-portable support for efficient execution on ragged tensors, current deep learning frameworks generally use techniques such as padding and masking to make the data shapes uniform and then offload the computations to optimized kernels for dense tensor algebra. Such techniques can, however, lead to a lot of wasted computation and therefore, a loss in performance. This paper presents CoRa, a tensor compiler that allows users to easily generate efficient code for ragged tensor operators targeting a wide range of CPUs and GPUs. Evaluating CoRa on a variety of operators on ragged tensors as well as on an encoder layer of the transformer model, we find that CoRa (i)performs competitively with hand-optimized implementations of the operators and the transformer encoder and (ii) achieves, over PyTorch, a 1.6X geomean speedup for the encoder on an Nvidia GPU and a 1.86X geomean speedup for the multi-head attention module used in transformers on an ARM CPU.