 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CoRa Tensor Compiler: Compilation for Ragged Tensors with Minimal Padding
Paper and Code
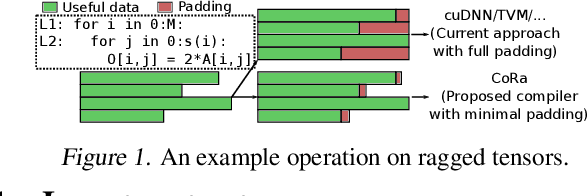
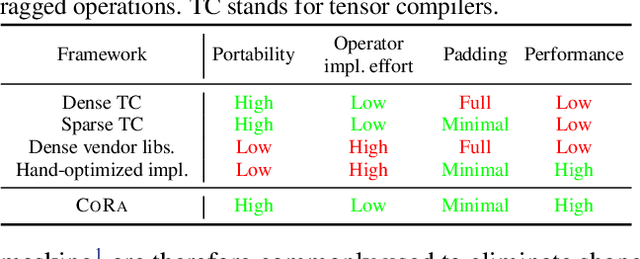
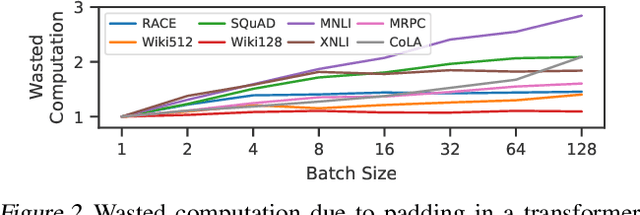
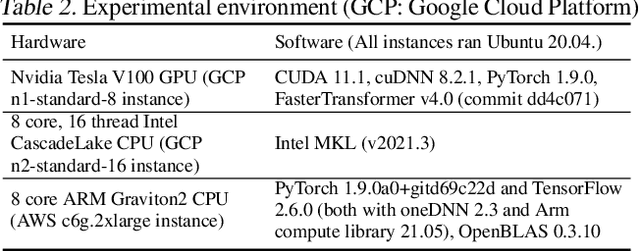
There is often variation in the shape and size of input data used for deep learning. In many cases, such data can be represented using tensors with non-uniform shapes, or ragged tensors. Due to limited and non-portable support for efficient execution on ragged tensors, current deep learning frameworks generally use techniques such as padding and masking to make the data shapes uniform and then offload the computations to optimized kernels for dense tensor algebra. Such techniques can, however, lead to a lot of wasted computation and therefore, a loss in performance. This paper presents CoRa, a tensor compiler that allows users to easily generate efficient code for ragged tensor operators targeting a wide range of CPUs and GPUs. Evaluating CoRa on a variety of operators on ragged tensors as well as on an encoder layer of the transformer model, we find that CoRa (i)performs competitively with hand-optimized implementations of the operators and the transformer encoder and (ii) achieves, over PyTorch, a 1.6X geomean speedup for the encoder on an Nvidia GPU and a 1.86X geomean speedup for the multi-head attention module used in transformers on an ARM CPU.