 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACRoBat: Optimizing Auto-batching of Dynamic Deep Learning at Compile Time
May 17, 2023



Dynamic control flow is an important technique often used to design expressive and efficient deep learning computations for applications such as text parsing, machine translation, exiting early out of deep models and so on. However, the resulting control flow divergence makes batching, an important performance optimization, difficult to perform manually. In this paper, we present ACRoBat, a framework that enables efficient automatic batching for dynamic deep learning computations by performing hybrid static+dynamic compiler optimizations and end-to-end tensor code generation. ACRoBat performs up to 8.5X better than DyNet, a state-of-the-art framework for automatic batching, on an Nvidia GeForce RTX 3070 GPU.
ED-Batch: Efficient Automatic Batching of Dynamic Neural Networks via Learned Finite State Machines
Feb 08, 2023



Batching has a fundamental influence on the efficiency of deep neural network (DNN) execution. However, for dynamic DNNs, efficient batching is particularly challenging as the dataflow graph varies per input instance. As a result, state-of-the-art frameworks use heuristics that result in suboptimal batching decisions. Further, batching puts strict restrictions on memory adjacency and can lead to high data movement costs. In this paper, we provide an approach for batching dynamic DNNs based on finite state machines, which enables the automatic discovery of batching policies specialized for each DNN via reinforcement learning. Moreover, we find that memory planning that is aware of the batching policy can save significant data movement overheads, which is automated by a PQ tree-based algorithm we introduce. Experimental results show that our framework speeds up state-of-the-art frameworks by on average 1.15x, 1.39x, and 2.45x for chain-based, tree-based, and lattice-based DNNs across CPU and GPU.
The CoRa Tensor Compiler: Compilation for Ragged Tensors with Minimal Padding
Oct 29, 2021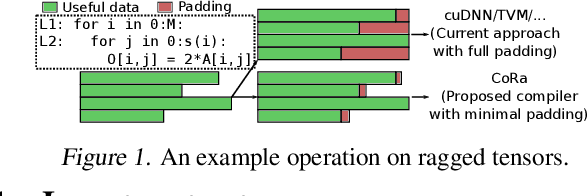
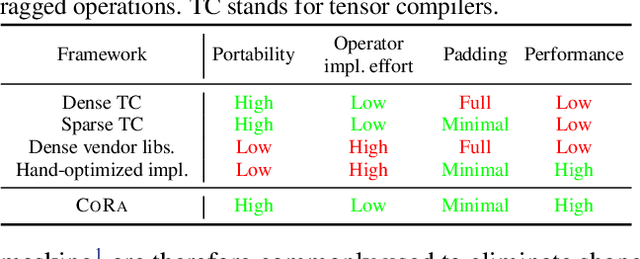
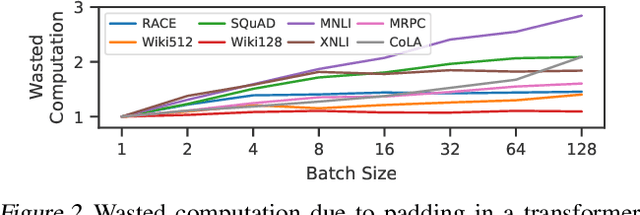
There is often variation in the shape and size of input data used for deep learning. In many cases, such data can be represented using tensors with non-uniform shapes, or ragged tensors. Due to limited and non-portable support for efficient execution on ragged tensors, current deep learning frameworks generally use techniques such as padding and masking to make the data shapes uniform and then offload the computations to optimized kernels for dense tensor algebra. Such techniques can, however, lead to a lot of wasted computation and therefore, a loss in performance. This paper presents CoRa, a tensor compiler that allows users to easily generate efficient code for ragged tensor operators targeting a wide range of CPUs and GPUs. Evaluating CoRa on a variety of operators on ragged tensors as well as on an encoder layer of the transformer model, we find that CoRa (i)performs competitively with hand-optimized implementations of the operators and the transformer encoder and (ii) achieves, over PyTorch, a 1.6X geomean speedup for the encoder on an Nvidia GPU and a 1.86X geomean speedup for the multi-head attention module used in transformers on an ARM CPU.
Cortex: A Compiler for Recursive Deep Learning Models
Nov 02, 2020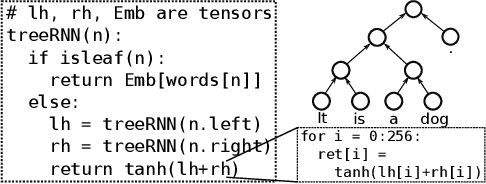
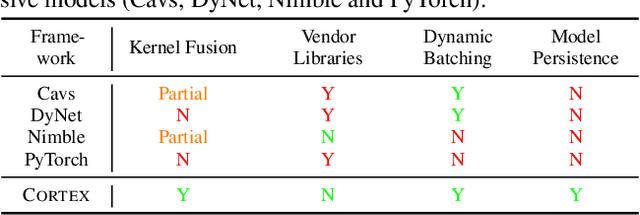
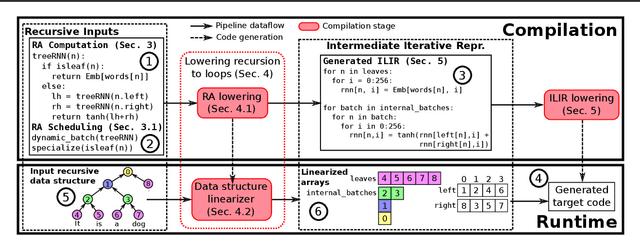

Optimizing deep learning models is generally performed in two steps: (i) high-level graph optimizations such as kernel fusion and (ii) low level kernel optimizations such as those found in vendor libraries. This approach often leaves significant performance on the table, especially for the case of recursive deep learning models. In this paper, we present Cortex, a compiler-based approach to generate highly-efficient code for recursive models for low latency inference. Our compiler approach and low reliance on vendor libraries enables us to perform end-to-end optimizations, leading to up to 14X lower inference latencies over past work, across different backends.