 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Regularization via Spectral Neural Networks and Non-linear Matrix Sensing
Feb 27, 2024The phenomenon of implicit regularization has attracted interest in recent years as a fundamental aspect of the remarkable generalizing ability of neural networks. In a nutshell, it entails that gradient descent dynamics in many neural nets, even without any explicit regularizer in the loss function, converges to the solution of a regularized learning problem. However, known results attempting to theoretically explain this phenomenon focus overwhelmingly on the setting of linear neural nets, and the simplicity of the linear structure is particularly crucial to existing arguments. In this paper, we explore this problem in the context of more realistic neural networks with a general class of non-linear activation functions, and rigorously demonstrate the implicit regularization phenomenon for such networks in the setting of matrix sensing problems, together with rigorous rate guarantees that ensure exponentially fast convergence of gradient descent.In this vein, we contribute a network architecture called Spectral Neural Networks (abbrv. SNN) that is particularly suitable for matrix learning problems. Conceptually, this entails coordinatizing the space of matrices by their singular values and singular vectors, as opposed to by their entries, a potentially fruitful perspective for matrix learning. We demonstrate that the SNN architecture is inherently much more amenable to theoretical analysis than vanilla neural nets and confirm its effectiveness in the context of matrix sensing, via both mathematical guarantees and empirical investigations. We believe that the SNN architecture has the potential to be of wide applicability in a broad class of matrix learning scenarios.
Minimax-optimal estimation for sparse multi-reference alignment with collision-free signals
Dec 13, 2023The Multi-Reference Alignment (MRA) problem aims at the recovery of an unknown signal from repeated observations under the latent action of a group of cyclic isometries, in the presence of additive noise of high intensity $\sigma$. It is a more tractable version of the celebrated cryo EM model. In the crucial high noise regime, it is known that its sample complexity scales as $\sigma^6$. Recent investigations have shown that for the practically significant setting of sparse signals, the sample complexity of the maximum likelihood estimator asymptotically scales with the noise level as $\sigma^4$. In this work, we investigate minimax optimality for signal estimation under the MRA model for so-called collision-free signals. In particular, this signal class covers the setting of generic signals of dilute sparsity (wherein the support size $s=O(L^{1/3})$, where $L$ is the ambient dimension. We demonstrate that the minimax optimal rate of estimation in for the sparse MRA problem in this setting is $\sigma^2/\sqrt{n}$, where $n$ is the sample size. In particular, this widely generalizes the sample complexity asymptotics for the restricted MLE in this setting, establishing it as the statistically optimal estimator. Finally, we demonstrate a concentration inequality for the restricted MLE on its deviations from the ground truth.
Learning Networks from Gaussian Graphical Models and Gaussian Free Fields
Aug 04, 2023We investigate the problem of estimating the structure of a weighted network from repeated measurements of a Gaussian Graphical Model (GGM) on the network. In this vein, we consider GGMs whose covariance structures align with the geometry of the weighted network on which they are based. Such GGMs have been of longstanding interest in statistical physics, and are referred to as the Gaussian Free Field (GFF). In recent years, they have attracted considerable interest in the machine learning and theoretical computer science. In this work, we propose a novel estimator for the weighted network (equivalently, its Laplacian) from repeated measurements of a GFF on the network, based on the Fourier analytic properties of the Gaussian distribution. In this pursuit, our approach exploits complex-valued statistics constructed from observed data, that are of interest on their own right. We demonstrate the effectiveness of our estimator with concrete recovery guarantees and bounds on the required sample complexity. In particular, we show that the proposed statistic achieves the parametric rate of estimation for fixed network size. In the setting of networks growing with sample size, our results show that for Erdos-Renyi random graphs $G(d,p)$ above the connectivity threshold, we demonstrate that network recovery takes place with high probability as soon as the sample size $n$ satisfies $n \gg d^4 \log d \cdot p^{-2}$.
Determinantal point processes based on orthogonal polynomials for sampling minibatches in SGD
Dec 11, 2021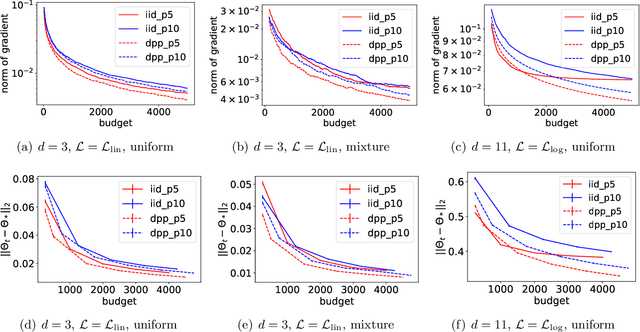
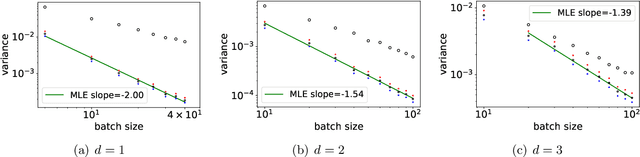

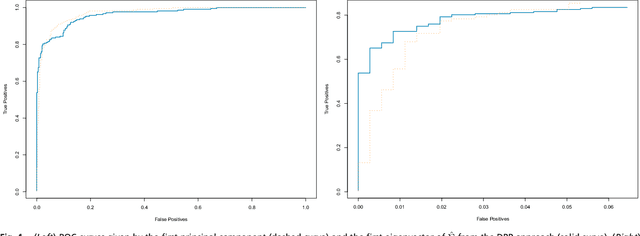
Stochastic gradient descent (SGD) is a cornerstone of machine learning. When the number N of data items is large, SGD relies on constructing an unbiased estimator of the gradient of the empirical risk using a small subset of the original dataset, called a minibatch. Default minibatch construction involves uniformly sampling a subset of the desired size, but alternatives have been explored for variance reduction. In particular, experimental evidence suggests drawing minibatches from determinantal point processes (DPPs), distributions over minibatches that favour diversity among selected items. However, like in recent work on DPPs for coresets, providing a systematic and principled understanding of how and why DPPs help has been difficult. In this work, we contribute an orthogonal polynomial-based DPP paradigm for minibatch sampling in SGD. Our approach leverages the specific data distribution at hand, which endows it with greater sensitivity and power over existing data-agnostic methods. We substantiate our method via a detailed theoretical analysis of its convergence properties, interweaving between the discrete data set and the underlying continuous domain. In particular, we show how specific DPPs and a string of controlled approximations can lead to gradient estimators with a variance that decays faster with the batchsize than under uniform sampling. Coupled with existing finite-time guarantees for SGD on convex objectives, this entails that, DPP minibatches lead to a smaller bound on the mean square approximation error than uniform minibatches. Moreover, our estimators are amenable to a recent algorithm that directly samples linear statistics of DPPs (i.e., the gradient estimator) without sampling the underlying DPP (i.e., the minibatch), thereby reducing computational overhead. We provide detailed synthetic as well as real data experiments to substantiate our theoretical claims.
Gaussian Determinantal Processes: a new model for directionality in data
Nov 19, 2021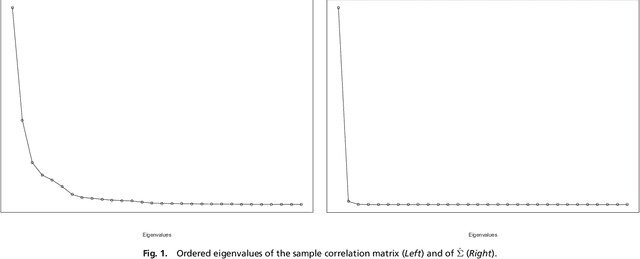
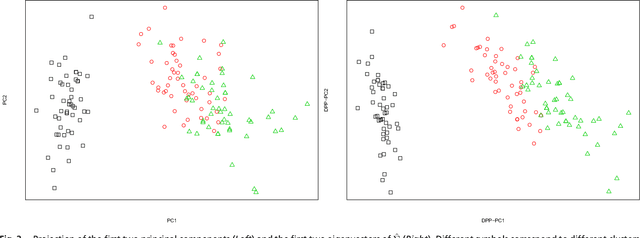
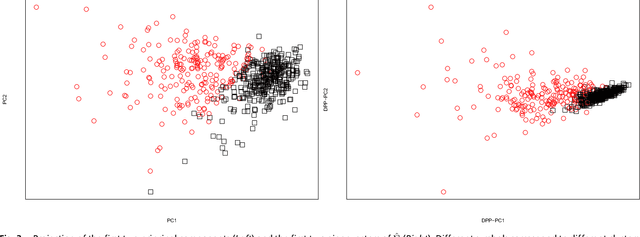
Determinantal point processes (a.k.a. DPPs) have recently become popular tools for modeling the phenomenon of negative dependence, or repulsion, in data. However, our understanding of an analogue of a classical parametric statistical theory is rather limited for this class of models. In this work, we investigate a parametric family of Gaussian DPPs with a clearly interpretable effect of parametric modulation on the observed points. We show that parameter modulation impacts the observed points by introducing directionality in their repulsion structure, and the principal directions correspond to the directions of maximal (i.e. the most long ranged) dependency. This model readily yields a novel and viable alternative to Principal Component Analysis (PCA) as a dimension reduction tool that favors directions along which the data is most spread out. This methodological contribution is complemented by a statistical analysis of a spiked model similar to that employed for covariance matrices as a framework to study PCA. These theoretical investigations unveil intriguing questions for further examination in random matrix theory, stochastic geometry and related topics.
* Published in the Proceedings of the National Academy of Sciences (Direct Submission)
Multi-Reference Alignment for sparse signals, Uniform Uncertainty Principles and the Beltway Problem
Jun 24, 2021Motivated by cutting-edge applications like cryo-electron microscopy (cryo-EM), the Multi-Reference Alignment (MRA) model entails the learning of an unknown signal from repeated measurements of its images under the latent action of a group of isometries and additive noise of magnitude $\sigma$. Despite significant interest, a clear picture for understanding rates of estimation in this model has emerged only recently, particularly in the high-noise regime $\sigma \gg 1$ that is highly relevant in applications. Recent investigations have revealed a remarkable asymptotic sample complexity of order $\sigma^6$ for certain signals whose Fourier transforms have full support, in stark contrast to the traditional $\sigma^2$ that arise in regular models. Often prohibitively large in practice, these results have prompted the investigation of variations around the MRA model where better sample complexity may be achieved. In this paper, we show that \emph{sparse} signals exhibit an intermediate $\sigma^4$ sample complexity even in the classical MRA model. Our results explore and exploit connections of the MRA estimation problem with two classical topics in applied mathematics: the \textit{beltway problem} from combinatorial optimization, and \textit{uniform uncertainty principles} from harmonic analysis.
Disordered complex networks: energy optimal lattices and persistent homology
Sep 13, 2020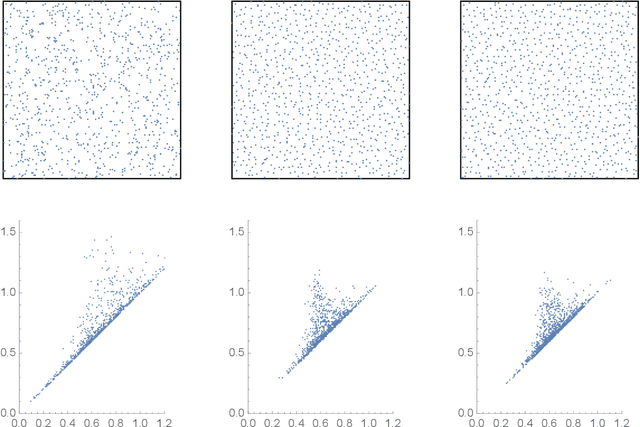
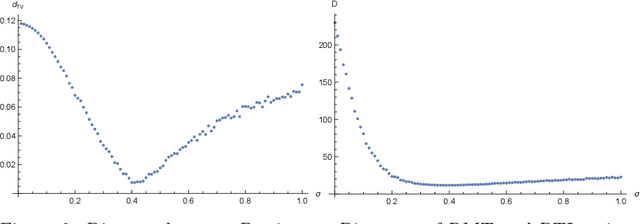
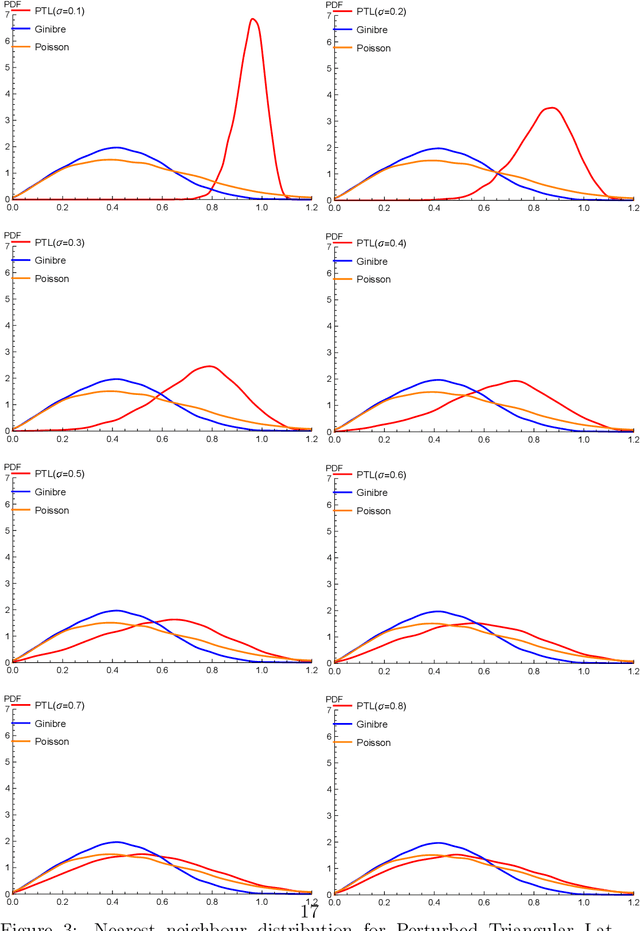
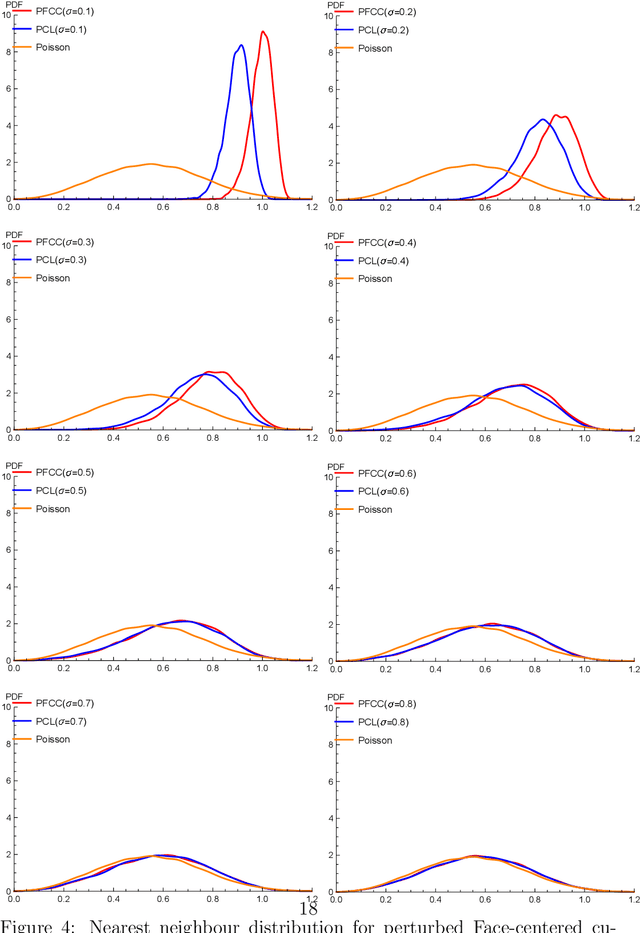
Disordered complex networks are of fundamental interest as stochastic models for information transmission over wireless networks. Well-known networks based on the Poisson point process model have limitations vis-a-vis network efficiency, whereas strongly correlated alternatives, such as those based on random matrix spectra (RMT), have tractability and robustness issues. In this work, we demonstrate that network models based on random perturbations of Euclidean lattices interpolate between Poisson and rigidly structured networks, and allow us to achieve the best of both worlds : significantly improve upon the Poisson model in terms of network efficacy measured by the Signal to Interference plus Noise Ratio (abbrv. SINR) and the related concept of coverage probabilities, at the same time retaining a considerable measure of mathematical and computational simplicity and robustness to erasure and noise. We investigate the optimal choice of the base lattice in this model, connecting it to the celebrated problem optimality of Euclidean lattices with respect to the Epstein Zeta function, which is in turn related to notions of lattice energy. This leads us to the choice of the triangular lattice in 2D and face centered cubic lattice in 3D. We demonstrate that the coverage probability decreases with increasing strength of perturbation, eventually converging to that of the Poisson network. In the regime of low disorder, we approximately characterize the statistical law of the coverage function. In 2D, we determine the disorder strength at which the PTL and the RMT networks are the closest measured by comparing their network topologies via a comparison of their Persistence Diagrams . We demonstrate that the PTL network at this disorder strength can be taken to be an effective substitute for the RMT network model, while at the same time offering the advantages of greater tractability.
Empirical Likelihood Under Mis-specification: Degeneracies and Random Critical Points
Oct 03, 2019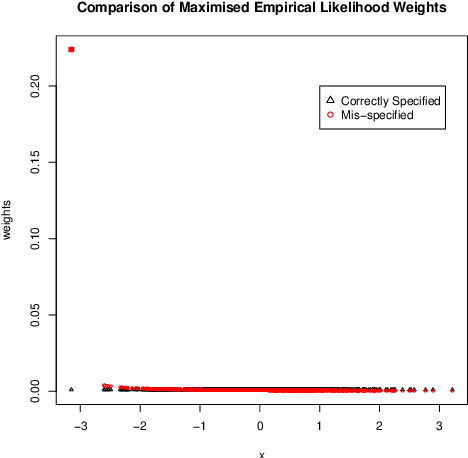
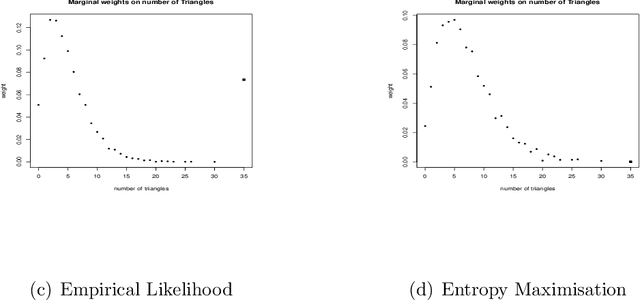
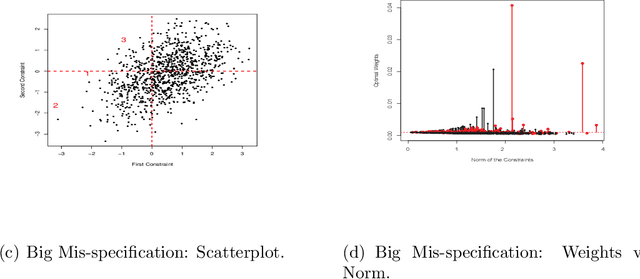
We investigate empirical likelihood obtained from mis-specified (i.e. biased) estimating equations. We establish that the behaviour of the optimal weights under mis-specification differ markedly from their properties under the null, i.e. when the estimating equations are unbiased and correctly specified. This is manifested by certain ``degeneracies'' in the optimal weights which define the likelihood. Such degeneracies in weights are not observed under the null. Furthermore, we establish an anomalous behaviour of the Wilks' statistic, which, unlike under correct specification, does not exhibit a chi-squared limit. In the Bayesian setting, we rigorously establish the posterior consistency of so called BayesEL procedures, where instead of a parametric likelihood, an empirical likelihood is used to define the posterior. In particular, we show that the BayesEL posterior, as a random probability measure, rapidly converges to the delta measure at the true parameter value. A novel feature of our approach is the investigation of critical points of random functions in the context of empirical likelihood. In particular, we obtain the location and the mass of the degenerate optimal weights as the leading and sub-leading terms in a canonical expansion of a particular critical point of a random function that is naturally associated with the model.
An easy-to-use empirical likelihood ABC method
Oct 08, 2018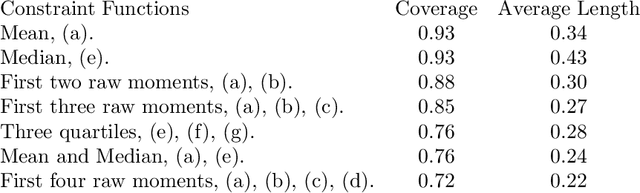
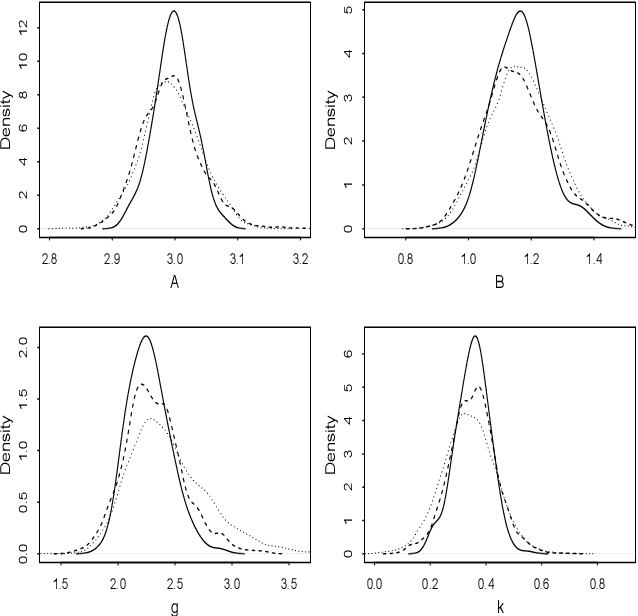
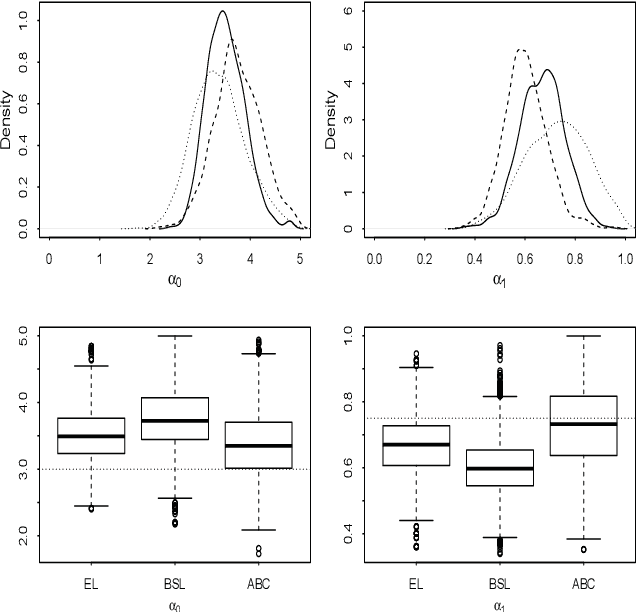
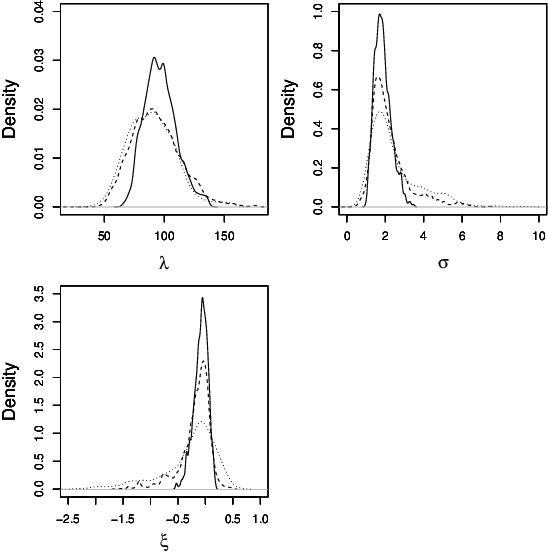
Many scientifically well-motivated statistical models in natural, engineering and environmental sciences are specified through a generative process, but in some cases it may not be possible to write down a likelihood for these models analytically. Approximate Bayesian computation (ABC) methods, which allow Bayesian inference in these situations, are typically computationally intensive. Recently, computationally attractive empirical likelihood based ABC methods have been suggested in the literature. These methods heavily rely on the availability of a set of suitable analytically tractable estimating equations. We propose an easy-to-use empirical likelihood ABC method, where the only inputs required are a choice of summary statistic, it's observed value, and the ability to simulate summary statistics for any parameter value under the model. It is shown that the posterior obtained using the proposed method is consistent, and its performance is explored using various examples.