 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Regularization via Spectral Neural Networks and Non-linear Matrix Sensing
Feb 27, 2024The phenomenon of implicit regularization has attracted interest in recent years as a fundamental aspect of the remarkable generalizing ability of neural networks. In a nutshell, it entails that gradient descent dynamics in many neural nets, even without any explicit regularizer in the loss function, converges to the solution of a regularized learning problem. However, known results attempting to theoretically explain this phenomenon focus overwhelmingly on the setting of linear neural nets, and the simplicity of the linear structure is particularly crucial to existing arguments. In this paper, we explore this problem in the context of more realistic neural networks with a general class of non-linear activation functions, and rigorously demonstrate the implicit regularization phenomenon for such networks in the setting of matrix sensing problems, together with rigorous rate guarantees that ensure exponentially fast convergence of gradient descent.In this vein, we contribute a network architecture called Spectral Neural Networks (abbrv. SNN) that is particularly suitable for matrix learning problems. Conceptually, this entails coordinatizing the space of matrices by their singular values and singular vectors, as opposed to by their entries, a potentially fruitful perspective for matrix learning. We demonstrate that the SNN architecture is inherently much more amenable to theoretical analysis than vanilla neural nets and confirm its effectiveness in the context of matrix sensing, via both mathematical guarantees and empirical investigations. We believe that the SNN architecture has the potential to be of wide applicability in a broad class of matrix learning scenarios.
Order-Optimal Error Bounds for Noisy Kernel-Based Bayesian Quadrature
Feb 22, 2022
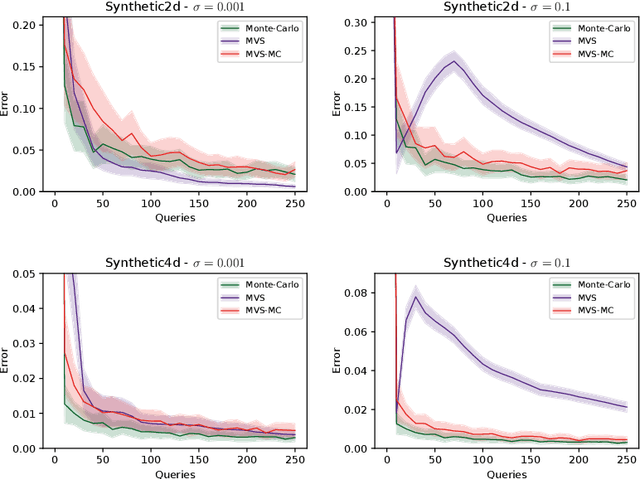
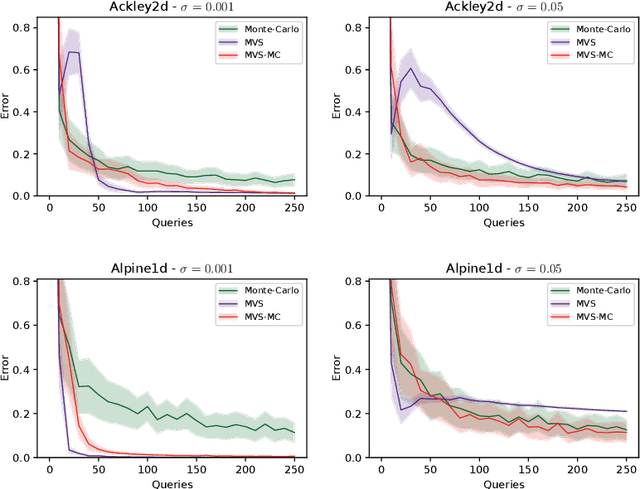
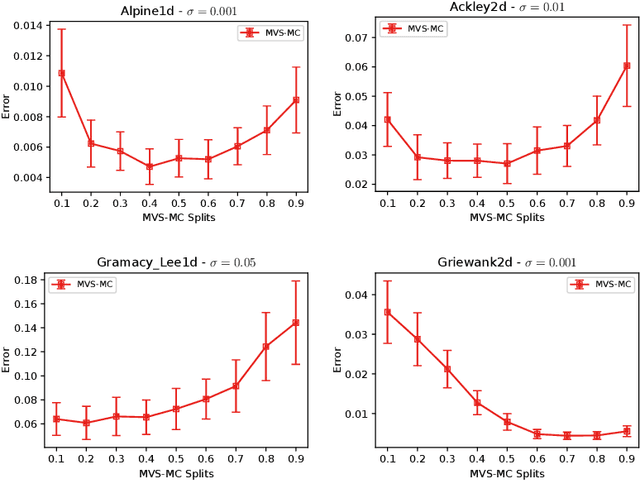
In this paper, we study the sample complexity of {\em noisy Bayesian quadrature} (BQ), in which we seek to approximate an integral based on noisy black-box queries to the underlying function. We consider functions in a {\em Reproducing Kernel Hilbert Space} (RKHS) with the Mat\'ern-$\nu$ kernel, focusing on combinations of the parameter $\nu$ and dimension $d$ such that the RKHS is equivalent to a Sobolev class. In this setting, we provide near-matching upper and lower bounds on the best possible average error. Specifically, we find that when the black-box queries are subject to Gaussian noise having variance $\sigma^2$, any algorithm making at most $T$ queries (even with adaptive sampling) must incur a mean absolute error of $\Omega(T^{-\frac{\nu}{d}-1} + \sigma T^{-\frac{1}{2}})$, and there exists a non-adaptive algorithm attaining an error of at most $O(T^{-\frac{\nu}{d}-1} + \sigma T^{-\frac{1}{2}})$. Hence, the bounds are order-optimal, and establish that there is no adaptivity gap in terms of scaling laws.