 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Benchmarks the Benchmarks? A Case Study of LLM Evaluation in Icelandic
Mar 17, 2026This paper evaluates current Large Language Model (LLM) benchmarking for Icelandic, identifies problems, and calls for improved evaluation methods in low/medium-resource languages in particular. We show that benchmarks that include synthetic or machine-translated data that have not been verified in any way, commonly contain severely flawed test examples that are likely to skew the results and undermine the tests' validity. We warn against the use of such methods without verification in low/medium-resource settings as the translation quality can, at best, only be as good as MT quality for a given language at any given time. Indeed, the results of our quantitative error analysis on existing benchmarks for Icelandic show clear differences between human-authored/-translated benchmarks vs. synthetic or machine-translated benchmarks.
Killing Two Flies with One Stone: An Attempt to Break LLMs Using English->Icelandic Idioms and Proper Names
Oct 04, 2024

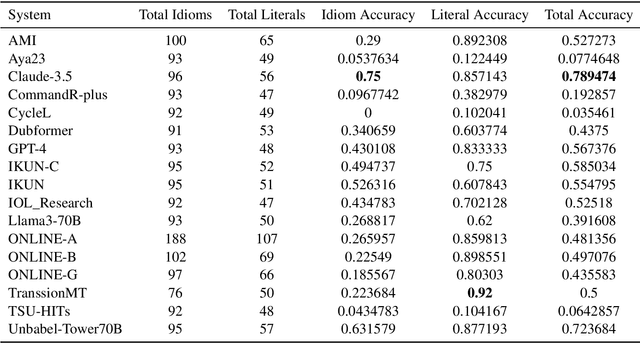
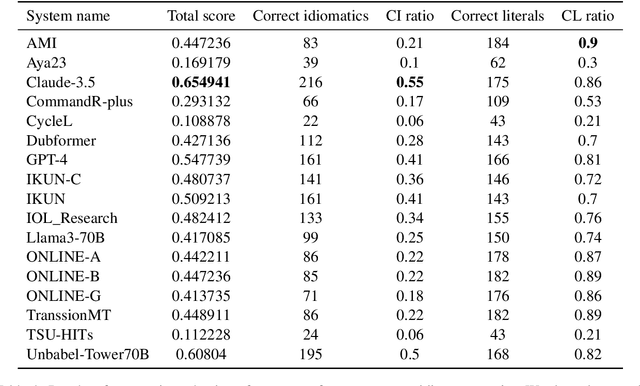
This paper presents the submission of the \'Arni Magn\'usson Institute's team to the WMT24 test suite subtask, focusing on idiomatic expressions and proper names for the English->Icelandic translation direction. Intuitively and empirically, idioms and proper names are known to be a significant challenge for modern translation models. We create two different test suites. The first evaluates the competency of MT systems in translating common English idiomatic expressions, as well as testing whether systems can distinguish between those expressions and the same phrases when used in a literal context. The second test suite consists of place names that should be translated into their Icelandic exonyms (and correctly inflected) and pairs of Icelandic names that share a surface form between the male and female variants, so that incorrect translations impact meaning as well as readability. The scores reported are relatively low, especially for idiomatic expressions and place names, and indicate considerable room for improvement.
Cogs in a Machine, Doing What They're Meant to Do -- The AMI Submission to the WMT24 General Translation Task
Oct 04, 2024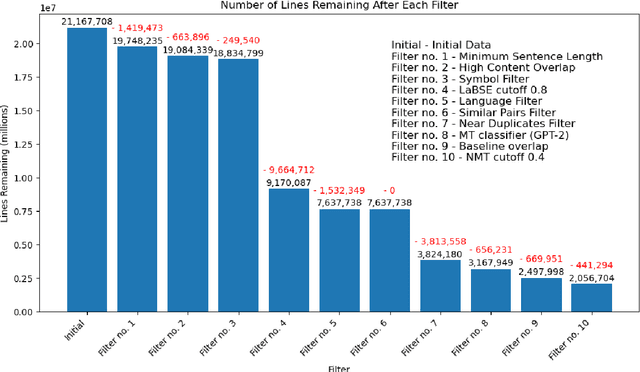
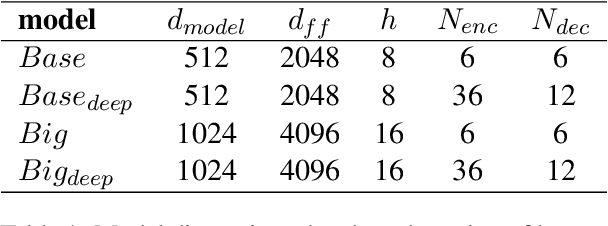

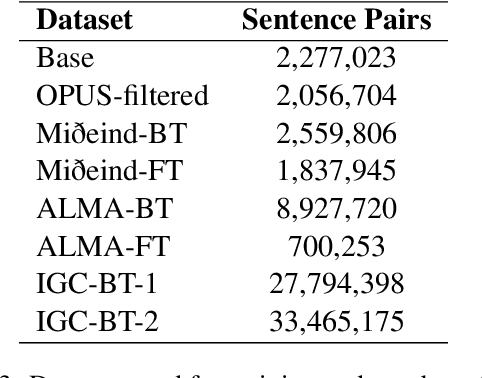
This paper presents the submission of the \'Arni Magnusson Institute's team to the WMT24 General translation task. We work on the English->Icelandic translation direction. Our system comprises four translation models and a grammar correction model. For training our models we carefully curate our datasets, aggressively filtering out sentence pairs that may detrimentally affect the quality of our system's output. Some of our data are collected from human translations and some are synthetically generated. A part of the synthetic data is generated using an LLM, and we find that it increases the translation capability of our system significantly.
Preliminary WMT24 Ranking of General MT Systems and LLMs
Jul 29, 2024



This is the preliminary ranking of WMT24 General MT systems based on automatic metrics. The official ranking will be a human evaluation, which is superior to the automatic ranking and supersedes it. The purpose of this report is not to interpret any findings but only provide preliminary results to the participants of the General MT task that may be useful during the writing of the system submission.
SentAlign: Accurate and Scalable Sentence Alignment
Nov 15, 2023We present SentAlign, an accurate sentence alignment tool designed to handle very large parallel document pairs. Given user-defined parameters, the alignment algorithm evaluates all possible alignment paths in fairly large documents of thousands of sentences and uses a divide-and-conquer approach to align documents containing tens of thousands of sentences. The scoring function is based on LaBSE bilingual sentence representations. SentAlign outperforms five other sentence alignment tools when evaluated on two different evaluation sets, German-French and English-Icelandic, and on a downstream machine translation task.
Language Technology Programme for Icelandic 2019-2023
Mar 20, 2020
In this paper, we describe a new national language technology programme for Icelandic. The programme, which spans a period of five years, aims at making Icelandic usable in communication and interactions in the digital world, by developing accessible, open-source language resources and software. The research and development work within the programme is carried out by a consortium of universities, institutions, and private companies, with a strong emphasis on cooperation between academia and industries. Five core projects will be the main content of the programme: language resources, speech recognition, speech synthesis, machine translation, and spell and grammar checking. We also describe other national language technology programmes and give an overview over the history of language technology in Iceland.
Augmenting a BiLSTM tagger with a Morphological Lexicon and a Lexical Category Identification Step
Jul 21, 2019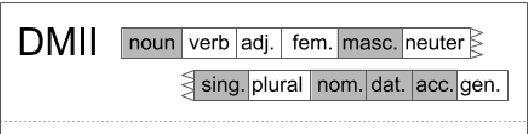
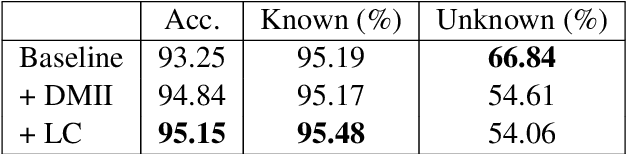
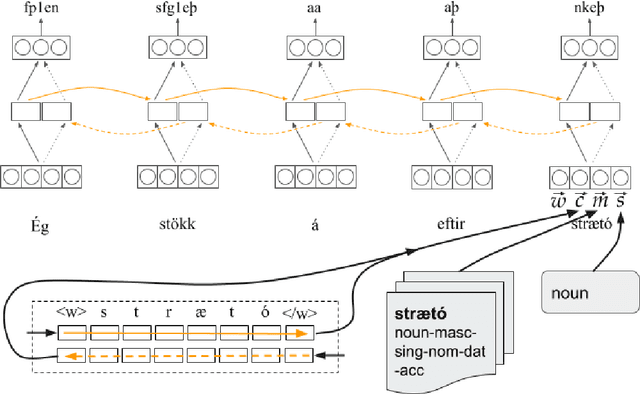
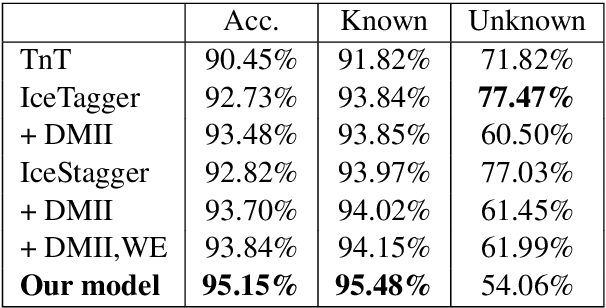
Previous work on using BiLSTM models for PoS tagging has primarily focused on small tagsets. We evaluate BiLSTM models for tagging Icelandic, a morphologically rich language, using a relatively large tagset. Our baseline BiLSTM model achieves higher accuracy than any previously published tagger not taking advantage of a morphological lexicon. When we extend the model by incorporating such data, we outperform previous state-of-the-art results by a significant margin. We also report on work in progress that attempts to address the problem of data sparsity inherent in morphologically detailed, fine-grained tagsets. We experiment with training a separate model on only the lexical category and using the coarse-grained output tag as an input for the main model. This method further increases the accuracy and reduces the tagging errors by 21.3% compared to previous state-of-the-art results. Finally, we train and test our tagger on a new gold standard for Icelandic.