 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Active Ranking from Pairwise Preferences
Feb 05, 2024We investigate the problem of probably approximately correct and fair (PACF) ranking of items by adaptively evoking pairwise comparisons. Given a set of $n$ items that belong to disjoint groups, our goal is to find an $(\epsilon, \delta)$-PACF-Ranking according to a fair objective function that we propose. We assume access to an oracle, wherein, for each query, the learner can choose a pair of items and receive stochastic winner feedback from the oracle. Our proposed objective function asks to minimize the $\ell_q$ norm of the error of the groups, where the error of a group is the $\ell_p$ norm of the error of all the items within that group, for $p, q \geq 1$. This generalizes the objective function of $\epsilon$-Best-Ranking, proposed by Saha & Gopalan (2019). By adopting our objective function, we gain the flexibility to explore fundamental fairness concepts like equal or proportionate errors within a unified framework. Adjusting parameters $p$ and $q$ allows tailoring to specific fairness preferences. We present both group-blind and group-aware algorithms and analyze their sample complexity. We provide matching lower bounds up to certain logarithmic factors for group-blind algorithms. For a restricted class of group-aware algorithms, we show that we can get reasonable lower bounds. We conduct comprehensive experiments on both real-world and synthetic datasets to complement our theoretical findings.
Optimizing Group-Fair Plackett-Luce Ranking Models for Relevance and Ex-Post Fairness
Aug 25, 2023In learning-to-rank (LTR), optimizing only the relevance (or the expected ranking utility) can cause representational harm to certain categories of items. Moreover, if there is implicit bias in the relevance scores, LTR models may fail to optimize for true relevance. Previous works have proposed efficient algorithms to train stochastic ranking models that achieve fairness of exposure to the groups ex-ante (or, in expectation), which may not guarantee representation fairness to the groups ex-post, that is, after realizing a ranking from the stochastic ranking model. Typically, ex-post fairness is achieved by post-processing, but previous work does not train stochastic ranking models that are aware of this post-processing. In this paper, we propose a novel objective that maximizes expected relevance only over those rankings that satisfy given representation constraints to ensure ex-post fairness. Building upon recent work on an efficient sampler for ex-post group-fair rankings, we propose a group-fair Plackett-Luce model and show that it can be efficiently optimized for our objective in the LTR framework. Experiments on three real-world datasets show that our group-fair algorithm guarantees fairness alongside usually having better relevance compared to the LTR baselines. In addition, our algorithm also achieves better relevance than post-processing baselines, which also ensures ex-post fairness. Further, when implicit bias is injected into the training data, our algorithm typically outperforms existing LTR baselines in relevance.
Sampling Individually-Fair Rankings that are Always Group Fair
Jun 21, 2023Rankings on online platforms help their end-users find the relevant information -- people, news, media, and products -- quickly. Fair ranking tasks, which ask to rank a set of items to maximize utility subject to satisfying group-fairness constraints, have gained significant interest in the Algorithmic Fairness, Information Retrieval, and Machine Learning literature. Recent works, however, identify uncertainty in the utilities of items as a primary cause of unfairness and propose introducing randomness in the output. This randomness is carefully chosen to guarantee an adequate representation of each item (while accounting for the uncertainty). However, due to this randomness, the output rankings may violate group fairness constraints. We give an efficient algorithm that samples rankings from an individually-fair distribution while ensuring that every output ranking is group fair. The expected utility of the output ranking is at least $\alpha$ times the utility of the optimal fair solution. Here, $\alpha$ depends on the utilities, position-discounts, and constraints -- it approaches 1 as the range of utilities or the position-discounts shrinks, or when utilities satisfy distributional assumptions. Empirically, we observe that our algorithm achieves individual and group fairness and that Pareto dominates the state-of-the-art baselines.
Socially Fair Center-based and Linear Subspace Clustering
Aug 22, 2022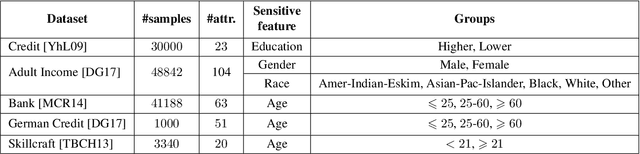
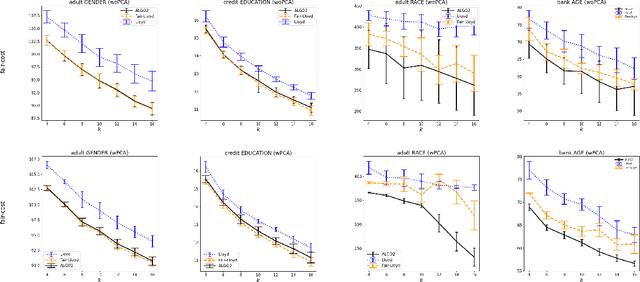
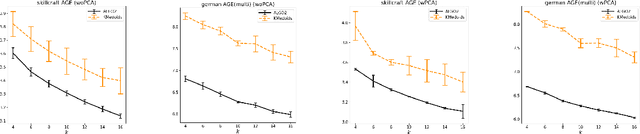
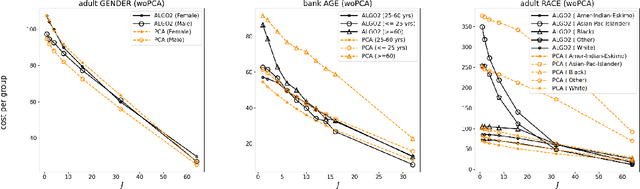
Center-based clustering (e.g., $k$-means, $k$-medians) and clustering using linear subspaces are two most popular techniques to partition real-world data into smaller clusters. However, when the data consists of sensitive demographic groups, significantly different clustering cost per point for different sensitive groups can lead to fairness-related harms (e.g., different quality-of-service). The goal of socially fair clustering is to minimize the maximum cost of clustering per point over all groups. In this work, we propose a unified framework to solve socially fair center-based clustering and linear subspace clustering, and give practical, efficient approximation algorithms for these problems. We do extensive experiments to show that on multiple benchmark datasets our algorithms either closely match or outperform state-of-the-art baselines.
Sampling Random Group Fair Rankings
Mar 02, 2022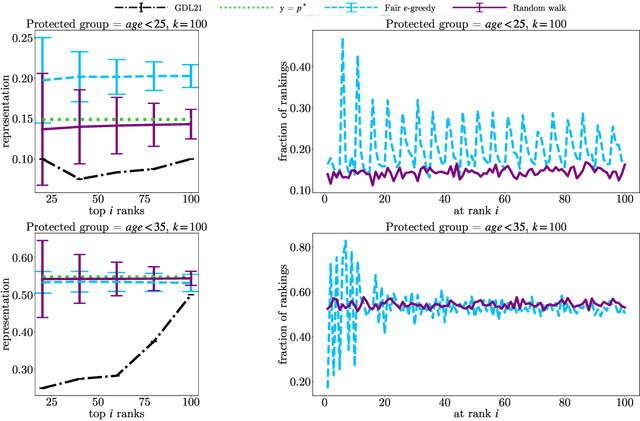
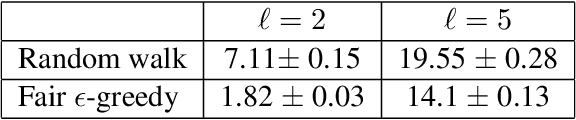
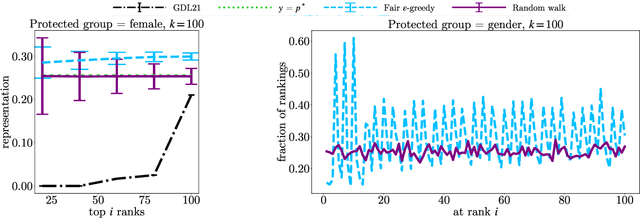
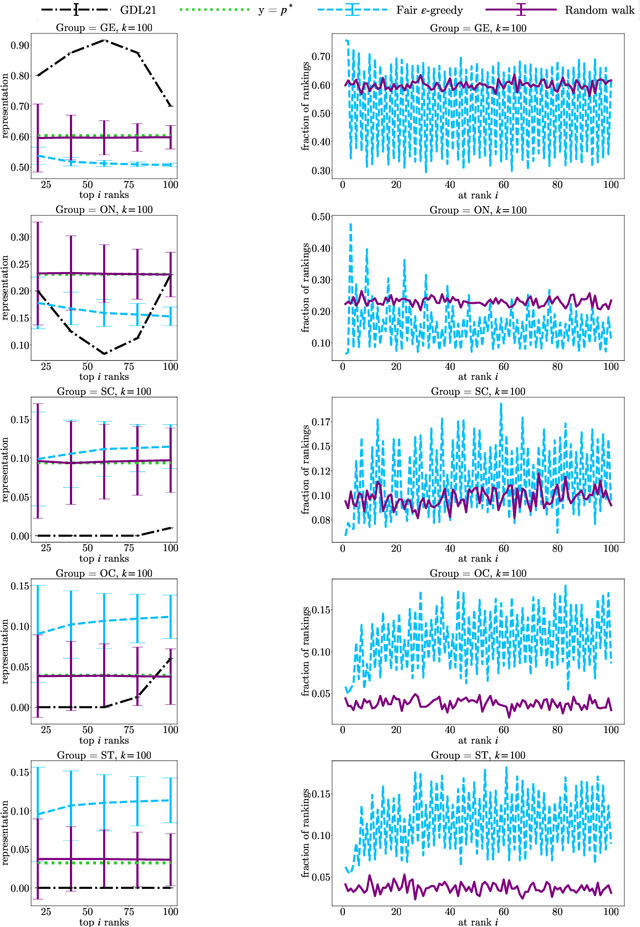
In this paper, we consider the problem of randomized group fair ranking that merges given ranked list of items from different sensitive demographic groups while satisfying given lower and upper bounds on the representation of each group in the top ranks. Our randomized group fair ranking formulation works even when there is implicit bias, incomplete relevance information, or when only ordinal ranking is available instead of relevance scores or utility values. We take an axiomatic approach and show that there is a unique distribution $\mathcal{D}$ to sample a random group fair ranking that satisfies a natural set of consistency and fairness axioms. Moreover, $\mathcal{D}$ satisfies representation constraints for every group at every rank, a characteristic that cannot be satisfied by any deterministic ranking. We propose three algorithms to sample a random group fair ranking from $\mathcal{D}$. Our first algorithm samples rankings from $\mathcal{D}$ exactly, in time exponential in the number of groups. Our second algorithm samples random group fair rankings from $\mathcal{D}$ exactly and is faster than the first algorithm when the gap between upper and lower bounds on the representation for each group is small. Our third algorithm samples rankings from a distribution $\epsilon$-close to $\mathcal{D}$ in total variation distance, and has expected running time polynomial in all input parameters and $1/\epsilon$ when there is a large gap between upper and lower bound representation constraints for all the groups. We experimentally validate the above guarantees of our algorithms for group fairness in top ranks and representation in every rank on real-world data sets.
Ranking for Individual and Group Fairness Simultaneously
Sep 24, 2020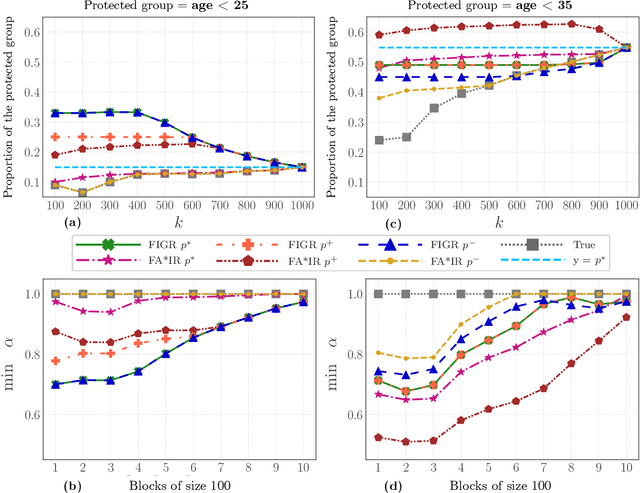
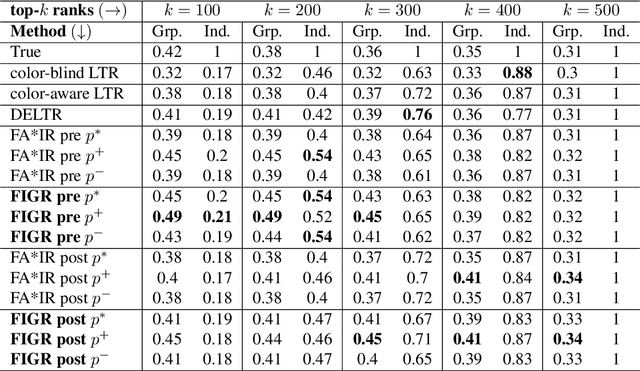
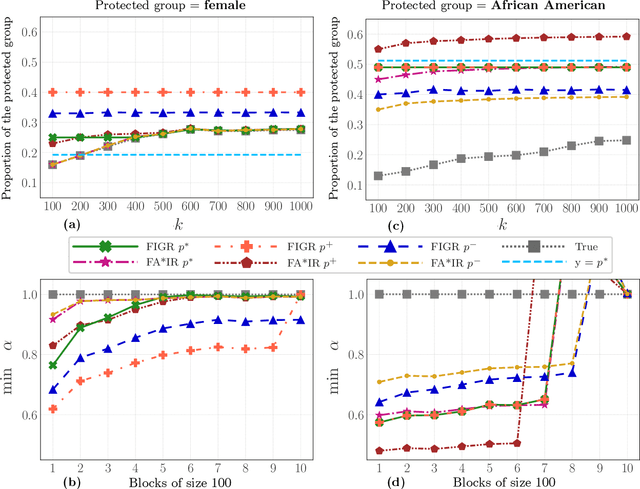
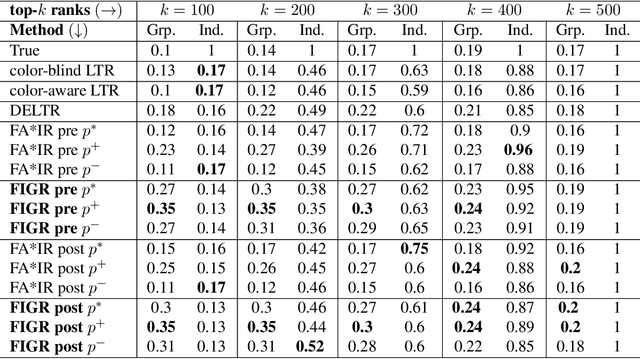
Search and recommendation systems, such as search engines, recruiting tools, online marketplaces, news, and social media, output ranked lists of content, products, and sometimes, people. Credit ratings, standardized tests, risk assessments output only a score, but are also used implicitly for ranking. Bias in such ranking systems, especially among the top ranks, can worsen social and economic inequalities, polarize opinions, and reinforce stereotypes. On the other hand, a bias correction for minority groups can cause more harm if perceived as favoring group-fair outcomes over meritocracy. In this paper, we study a trade-off between individual fairness and group fairness in ranking. We define individual fairness based on how close the predicted rank of each item is to its true rank, and prove a lower bound on the trade-off achievable for simultaneous individual and group fairness in ranking. We give a fair ranking algorithm that takes any given ranking and outputs another ranking with simultaneous individual and group fairness guarantees comparable to the lower bound we prove. Our algorithm can be used to both pre-process training data as well as post-process the output of existing ranking algorithms. Our experimental results show that our algorithm performs better than the state-of-the-art fair learning to rank and fair post-processing baselines.
Aspect-Sentiment Embeddings for Company Profiling and Employee Opinion Mining
Feb 22, 2019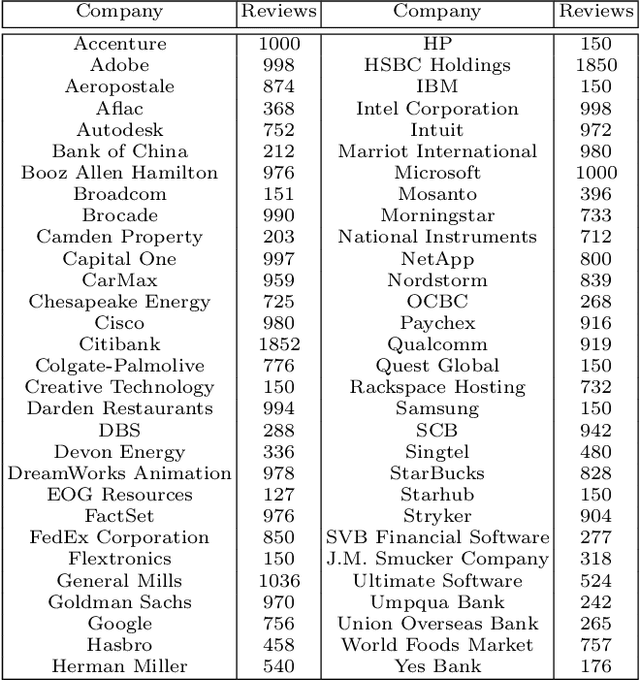
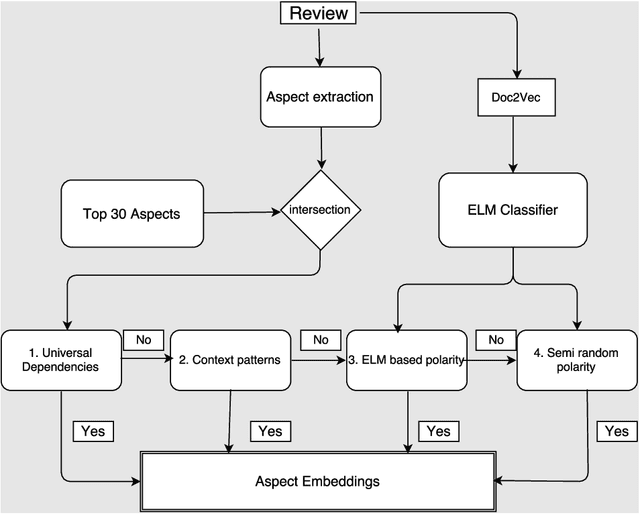
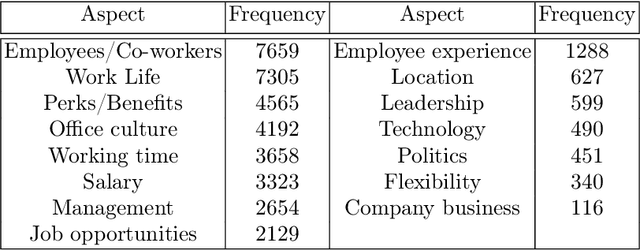
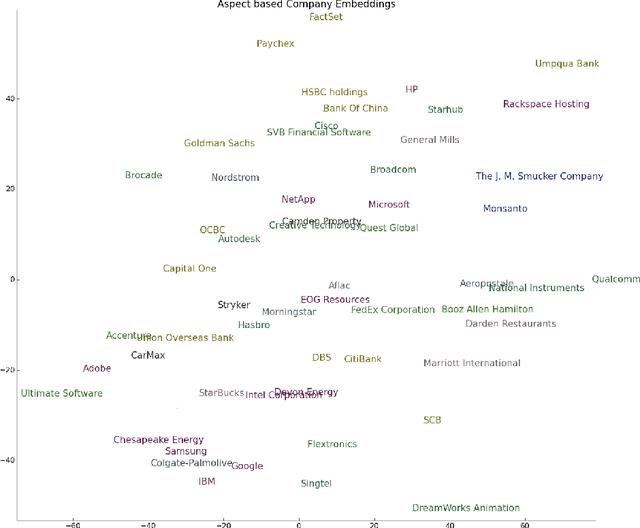
With the multitude of companies and organizations abound today, ranking them and choosing one out of the many is a difficult and cumbersome task. Although there are many available metrics that rank companies, there is an inherent need for a generalized metric that takes into account the different aspects that constitute employee opinions of the companies. In this work, we aim to overcome the aforementioned problem by generating aspect-sentiment based embedding for the companies by looking into reliable employee reviews of them. We created a comprehensive dataset of company reviews from the famous website Glassdoor.com and employed a novel ensemble approach to perform aspect-level sentiment analysis. Although a relevant amount of work has been done on reviews centered on subjects like movies, music, etc., this work is the first of its kind. We also provide several insights from the collated embeddings, thus helping users gain a better understanding of their options as well as select companies using customized preferences.
CASCADE: Contextual Sarcasm Detection in Online Discussion Forums
May 16, 2018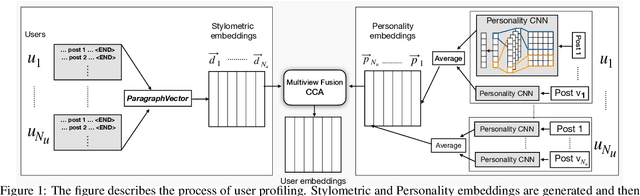
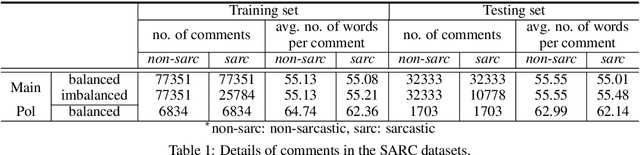
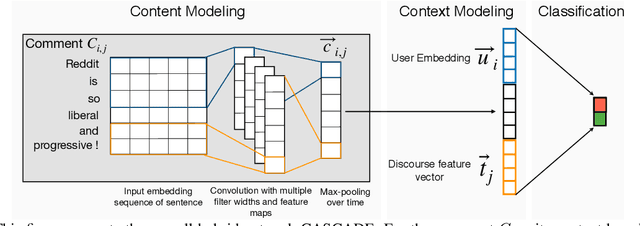
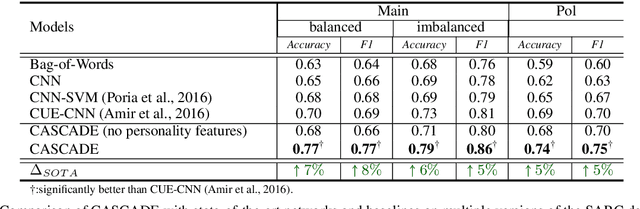
The literature in automated sarcasm detection has mainly focused on lexical, syntactic and semantic-level analysis of text. However, a sarcastic sentence can be expressed with contextual presumptions, background and commonsense knowledge. In this paper, we propose CASCADE (a ContextuAl SarCasm DEtector) that adopts a hybrid approach of both content and context-driven modeling for sarcasm detection in online social media discussions. For the latter, CASCADE aims at extracting contextual information from the discourse of a discussion thread. Also, since the sarcastic nature and form of expression can vary from person to person, CASCADE utilizes user embeddings that encode stylometric and personality features of the users. When used along with content-based feature extractors such as Convolutional Neural Networks (CNNs), we see a significant boost in the classification performance on a large Reddit corpus.