 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocially Fair Center-based and Linear Subspace Clustering
Aug 22, 2022
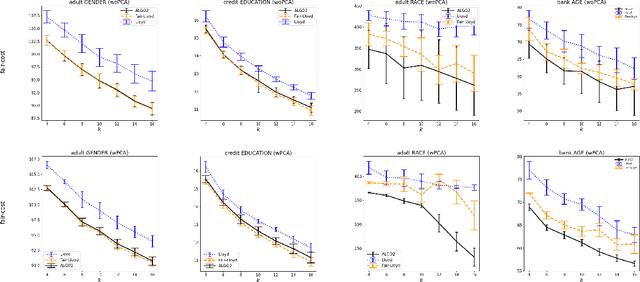
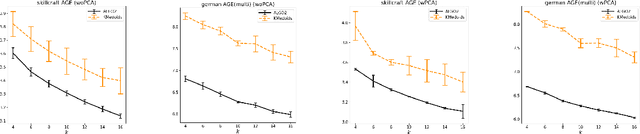
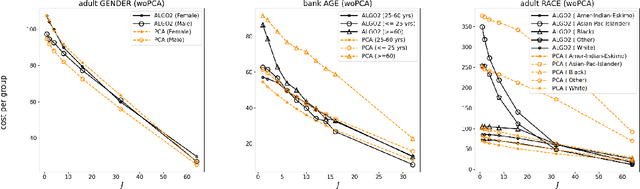
Center-based clustering (e.g., $k$-means, $k$-medians) and clustering using linear subspaces are two most popular techniques to partition real-world data into smaller clusters. However, when the data consists of sensitive demographic groups, significantly different clustering cost per point for different sensitive groups can lead to fairness-related harms (e.g., different quality-of-service). The goal of socially fair clustering is to minimize the maximum cost of clustering per point over all groups. In this work, we propose a unified framework to solve socially fair center-based clustering and linear subspace clustering, and give practical, efficient approximation algorithms for these problems. We do extensive experiments to show that on multiple benchmark datasets our algorithms either closely match or outperform state-of-the-art baselines.