 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlatness-Aware Stochastic Gradient Langevin Dynamics
Oct 02, 2025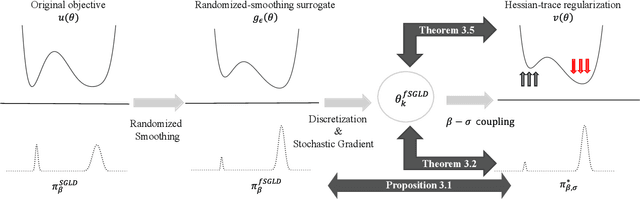
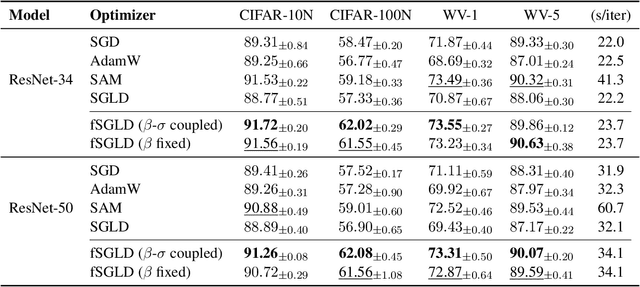
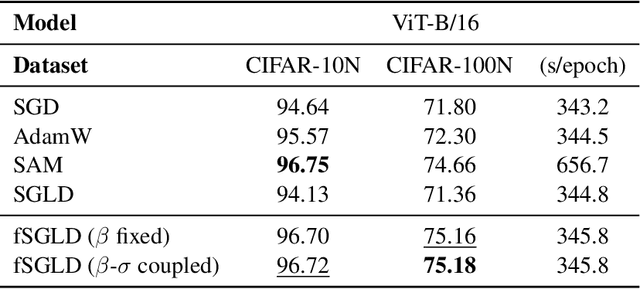
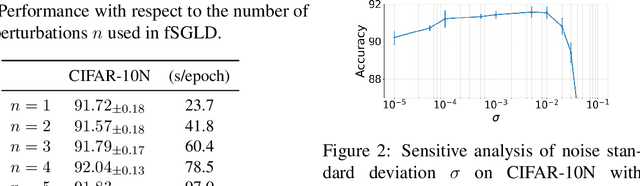
Generalization in deep learning is closely tied to the pursuit of flat minima in the loss landscape, yet classical Stochastic Gradient Langevin Dynamics (SGLD) offers no mechanism to bias its dynamics toward such low-curvature solutions. This work introduces Flatness-Aware Stochastic Gradient Langevin Dynamics (fSGLD), designed to efficiently and provably seek flat minima in high-dimensional nonconvex optimization problems. At each iteration, fSGLD uses the stochastic gradient evaluated at parameters perturbed by isotropic Gaussian noise, commonly referred to as Random Weight Perturbation (RWP), thereby optimizing a randomized-smoothing objective that implicitly captures curvature information. Leveraging these properties, we prove that the invariant measure of fSGLD stays close to a stationary measure concentrated on the global minimizers of a loss function regularized by the Hessian trace whenever the inverse temperature and the scale of random weight perturbation are properly coupled. This result provides a rigorous theoretical explanation for the benefits of random weight perturbation. In particular, we establish non-asymptotic convergence guarantees in Wasserstein distance with the best known rate and derive an excess-risk bound for the Hessian-trace regularized objective. Extensive experiments on noisy-label and large-scale vision tasks, in both training-from-scratch and fine-tuning settings, demonstrate that fSGLD achieves superior or comparable generalization and robustness to baseline algorithms while maintaining the computational cost of SGD, about half that of SAM. Hessian-spectrum analysis further confirms that fSGLD converges to significantly flatter minima.
One More Question is Enough, Expert Question Decomposition (EQD) Model for Domain Quantitative Reasoning
Oct 01, 2025Domain-specific quantitative reasoning remains a major challenge for large language models (LLMs), especially in fields requiring expert knowledge and complex question answering (QA). In this work, we propose Expert Question Decomposition (EQD), an approach designed to balance the use of domain knowledge with computational efficiency. EQD is built on a two-step fine-tuning framework and guided by a reward function that measures the effectiveness of generated sub-questions in improving QA outcomes. It requires only a few thousand training examples and a single A100 GPU for fine-tuning, with inference time comparable to zero-shot prompting. Beyond its efficiency, EQD outperforms state-of-the-art domain-tuned models and advanced prompting strategies. We evaluate EQD in the financial domain, characterized by specialized knowledge and complex quantitative reasoning, across four benchmark datasets. Our method consistently improves QA performance by 0.6% to 10.5% across different LLMs. Our analysis reveals an important insight: in domain-specific QA, a single supporting question often provides greater benefit than detailed guidance steps.
kTULA: A Langevin sampling algorithm with improved KL bounds under super-linear log-gradients
Jun 05, 2025Motivated by applications in deep learning, where the global Lipschitz continuity condition is often not satisfied, we examine the problem of sampling from distributions with super-linearly growing log-gradients. We propose a novel tamed Langevin dynamics-based algorithm, called kTULA, to solve the aforementioned sampling problem, and provide a theoretical guarantee for its performance. More precisely, we establish a non-asymptotic convergence bound in Kullback-Leibler (KL) divergence with the best-known rate of convergence equal to $2-\overline{\epsilon}$, $\overline{\epsilon}>0$, which significantly improves relevant results in existing literature. This enables us to obtain an improved non-asymptotic error bound in Wasserstein-2 distance, which can be used to further derive a non-asymptotic guarantee for kTULA to solve the associated optimization problems. To illustrate the applicability of kTULA, we apply the proposed algorithm to the problem of sampling from a high-dimensional double-well potential distribution and to an optimization problem involving a neural network. We show that our main results can be used to provide theoretical guarantees for the performance of kTULA.
Wasserstein Convergence of Score-based Generative Models under Semiconvexity and Discontinuous Gradients
May 06, 2025

Score-based Generative Models (SGMs) approximate a data distribution by perturbing it with Gaussian noise and subsequently denoising it via a learned reverse diffusion process. These models excel at modeling complex data distributions and generating diverse samples, achieving state-of-the-art performance across domains such as computer vision, audio generation, reinforcement learning, and computational biology. Despite their empirical success, existing Wasserstein-2 convergence analysis typically assume strong regularity conditions-such as smoothness or strict log-concavity of the data distribution-that are rarely satisfied in practice. In this work, we establish the first non-asymptotic Wasserstein-2 convergence guarantees for SGMs targeting semiconvex distributions with potentially discontinuous gradients. Our upper bounds are explicit and sharp in key parameters, achieving optimal dependence of $O(\sqrt{d})$ on the data dimension $d$ and convergence rate of order one. The framework accommodates a wide class of practically relevant distributions, including symmetric modified half-normal distributions, Gaussian mixtures, double-well potentials, and elastic net potentials. By leveraging semiconvexity without requiring smoothness assumptions on the potential such as differentiability, our results substantially broaden the theoretical foundations of SGMs, bridging the gap between empirical success and rigorous guarantees in non-smooth, complex data regimes.
The Performance Of The Unadjusted Langevin Algorithm Without Smoothness Assumptions
Feb 05, 2025

In this article, we study the problem of sampling from distributions whose densities are not necessarily smooth nor log-concave. We propose a simple Langevin-based algorithm that does not rely on popular but computationally challenging techniques, such as the Moreau Yosida envelope or Gaussian smoothing. We derive non-asymptotic guarantees for the convergence of the algorithm to the target distribution in Wasserstein distances. Non asymptotic bounds are also provided for the performance of the algorithm as an optimizer, specifically for the solution of associated excess risk optimization problems.
Taming the Interacting Particle Langevin Algorithm -- the superlinear case
Apr 03, 2024Recent advances in stochastic optimization have yielded the interactive particle Langevin algorithm (IPLA), which leverages the notion of interacting particle systems (IPS) to efficiently sample from approximate posterior densities. This becomes particularly crucial within the framework of Expectation-Maximization (EM), where the E-step is computationally challenging or even intractable. Although prior research has focused on scenarios involving convex cases with gradients of log densities that grow at most linearly, our work extends this framework to include polynomial growth. Taming techniques are employed to produce an explicit discretization scheme that yields a new class of stable, under such non-linearities, algorithms which are called tamed interactive particle Langevin algorithms (tIPLA). We obtain non-asymptotic convergence error estimates in Wasserstein-2 distance for the new class under an optimal rate.
On diffusion-based generative models and their error bounds: The log-concave case with full convergence estimates
Nov 22, 2023

We provide full theoretical guarantees for the convergence behaviour of diffusion-based generative models under the assumption of strongly logconcave data distributions while our approximating class of functions used for score estimation is made of Lipschitz continuous functions. We demonstrate via a motivating example, sampling from a Gaussian distribution with unknown mean, the powerfulness of our approach. In this case, explicit estimates are provided for the associated optimization problem, i.e. score approximation, while these are combined with the corresponding sampling estimates. As a result, we obtain the best known upper bound estimates in terms of key quantities of interest, such as the dimension and rates of convergence, for the Wasserstein-2 distance between the data distribution (Gaussian with unknown mean) and our sampling algorithm. Beyond the motivating example and in order to allow for the use of a diverse range of stochastic optimizers, we present our results using an $L^2$-accurate score estimation assumption, which crucially is formed under an expectation with respect to the stochastic optimizer and our novel auxiliary process that uses only known information. This approach yields the best known convergence rate for our sampling algorithm.
Taming under isoperimetry
Nov 15, 2023In this article we propose a novel taming Langevin-based scheme called $\mathbf{sTULA}$ to sample from distributions with superlinearly growing log-gradient which also satisfy a Log-Sobolev inequality. We derive non-asymptotic convergence bounds in $KL$ and consequently total variation and Wasserstein-$2$ distance from the target measure. Non-asymptotic convergence guarantees are provided for the performance of the new algorithm as an optimizer. Finally, some theoretical results on isoperimertic inequalities for distributions with superlinearly growing gradients are provided. Key findings are a Log-Sobolev inequality with constant independent of the dimension, in the presence of a higher order regularization and a Poincare inequality with constant independent of temperature and dimension under a novel non-convex theoretical framework.
Interacting Particle Langevin Algorithm for Maximum Marginal Likelihood Estimation
Mar 23, 2023


We study a class of interacting particle systems for implementing a marginal maximum likelihood estimation (MLE) procedure to optimize over the parameters of a latent variable model. To do so, we propose a continuous-time interacting particle system which can be seen as a Langevin diffusion over an extended state space, where the number of particles acts as the inverse temperature parameter in classical settings for optimisation. Using Langevin diffusions, we prove nonasymptotic concentration bounds for the optimisation error of the maximum marginal likelihood estimator in terms of the number of particles in the particle system, the number of iterations of the algorithm, and the step-size parameter for the time discretisation analysis.
Kinetic Langevin MCMC Sampling Without Gradient Lipschitz Continuity -- the Strongly Convex Case
Jan 19, 2023In this article we consider sampling from log concave distributions in Hamiltonian setting, without assuming that the objective gradient is globally Lipschitz. We propose two algorithms based on monotone polygonal (tamed) Euler schemes, to sample from a target measure, and provide non-asymptotic 2-Wasserstein distance bounds between the law of the process of each algorithm and the target measure. Finally, we apply these results to bound the excess risk optimization error of the associated optimization problem.