 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuum Dropout for Neural Differential Equations
Nov 18, 2025Neural Differential Equations (NDEs) excel at modeling continuous-time dynamics, effectively handling challenges such as irregular observations, missing values, and noise. Despite their advantages, NDEs face a fundamental challenge in adopting dropout, a cornerstone of deep learning regularization, making them susceptible to overfitting. To address this research gap, we introduce Continuum Dropout, a universally applicable regularization technique for NDEs built upon the theory of alternating renewal processes. Continuum Dropout formulates the on-off mechanism of dropout as a stochastic process that alternates between active (evolution) and inactive (paused) states in continuous time. This provides a principled approach to prevent overfitting and enhance the generalization capabilities of NDEs. Moreover, Continuum Dropout offers a structured framework to quantify predictive uncertainty via Monte Carlo sampling at test time. Through extensive experiments, we demonstrate that Continuum Dropout outperforms existing regularization methods for NDEs, achieving superior performance on various time series and image classification tasks. It also yields better-calibrated and more trustworthy probability estimates, highlighting its effectiveness for uncertainty-aware modeling.
FlowPath: Learning Data-Driven Manifolds with Invertible Flows for Robust Irregularly-sampled Time Series Classification
Nov 13, 2025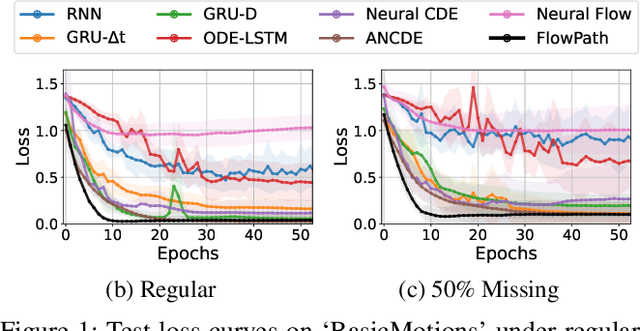
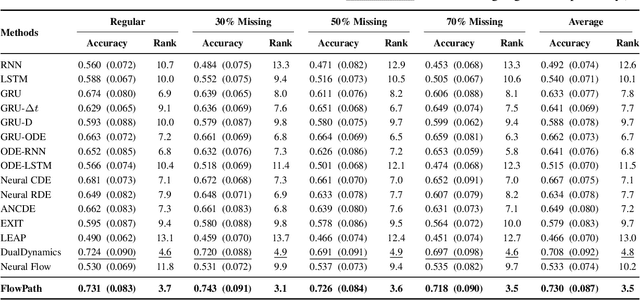
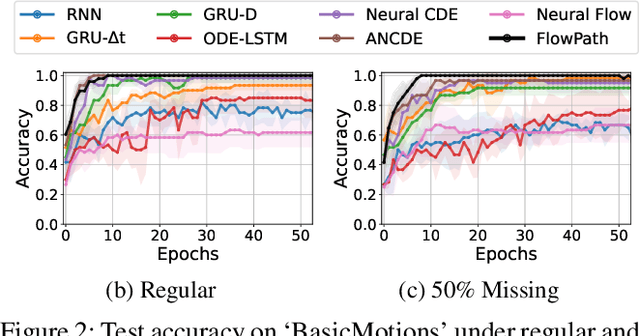

Modeling continuous-time dynamics from sparse and irregularly-sampled time series remains a fundamental challenge. Neural controlled differential equations provide a principled framework for such tasks, yet their performance is highly sensitive to the choice of control path constructed from discrete observations. Existing methods commonly employ fixed interpolation schemes, which impose simplistic geometric assumptions that often misrepresent the underlying data manifold, particularly under high missingness. We propose FlowPath, a novel approach that learns the geometry of the control path via an invertible neural flow. Rather than merely connecting observations, FlowPath constructs a continuous and data-adaptive manifold, guided by invertibility constraints that enforce information-preserving and well-behaved transformations. This inductive bias distinguishes FlowPath from prior unconstrained learnable path models. Empirical evaluations on 18 benchmark datasets and a real-world case study demonstrate that FlowPath consistently achieves statistically significant improvements in classification accuracy over baselines using fixed interpolants or non-invertible architectures. These results highlight the importance of modeling not only the dynamics along the path but also the geometry of the path itself, offering a robust and generalizable solution for learning from irregular time series.
Controllable Machine Unlearning via Gradient Pivoting
Oct 22, 2025



Machine unlearning (MU) aims to remove the influence of specific data from a trained model. However, approximate unlearning methods, often formulated as a single-objective optimization (SOO) problem, face a critical trade-off between unlearning efficacy and model fidelity. This leads to three primary challenges: the risk of over-forgetting, a lack of fine-grained control over the unlearning process, and the absence of metrics to holistically evaluate the trade-off. To address these issues, we reframe MU as a multi-objective optimization (MOO) problem. We then introduce a novel algorithm, Controllable Unlearning by Pivoting Gradient (CUP), which features a unique pivoting mechanism. Unlike traditional MOO methods that converge to a single solution, CUP's mechanism is designed to controllably navigate the entire Pareto frontier. This navigation is governed by a single intuitive hyperparameter, the `unlearning intensity', which allows for precise selection of a desired trade-off. To evaluate this capability, we adopt the hypervolume indicator, a metric that captures both the quality and diversity of the entire set of solutions an algorithm can generate. Our experimental results demonstrate that CUP produces a superior set of Pareto-optimal solutions, consistently outperforming existing methods across various vision tasks.
Flatness-Aware Stochastic Gradient Langevin Dynamics
Oct 02, 2025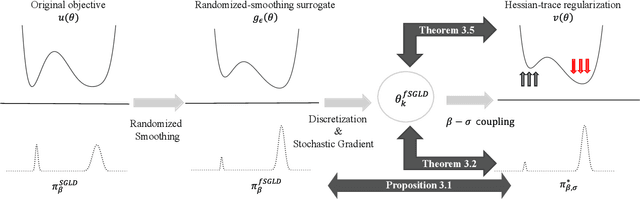
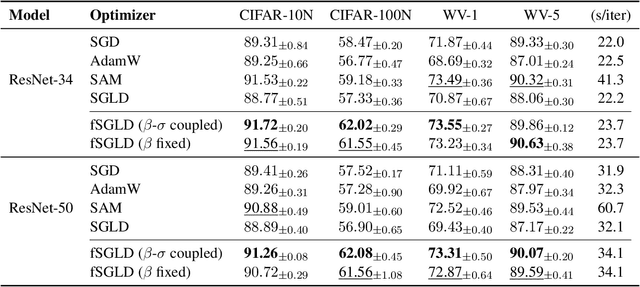
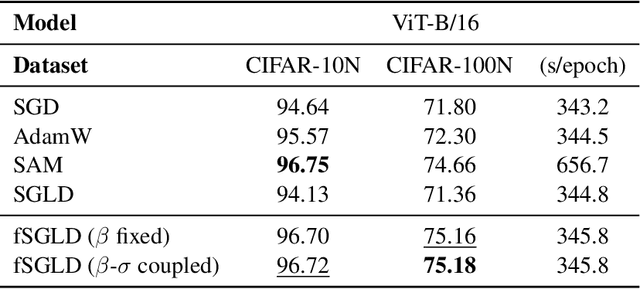
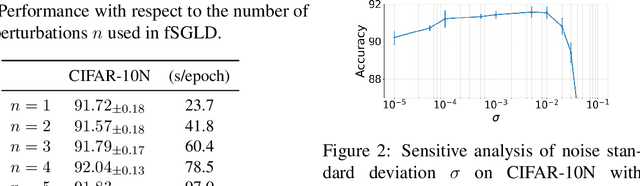
Generalization in deep learning is closely tied to the pursuit of flat minima in the loss landscape, yet classical Stochastic Gradient Langevin Dynamics (SGLD) offers no mechanism to bias its dynamics toward such low-curvature solutions. This work introduces Flatness-Aware Stochastic Gradient Langevin Dynamics (fSGLD), designed to efficiently and provably seek flat minima in high-dimensional nonconvex optimization problems. At each iteration, fSGLD uses the stochastic gradient evaluated at parameters perturbed by isotropic Gaussian noise, commonly referred to as Random Weight Perturbation (RWP), thereby optimizing a randomized-smoothing objective that implicitly captures curvature information. Leveraging these properties, we prove that the invariant measure of fSGLD stays close to a stationary measure concentrated on the global minimizers of a loss function regularized by the Hessian trace whenever the inverse temperature and the scale of random weight perturbation are properly coupled. This result provides a rigorous theoretical explanation for the benefits of random weight perturbation. In particular, we establish non-asymptotic convergence guarantees in Wasserstein distance with the best known rate and derive an excess-risk bound for the Hessian-trace regularized objective. Extensive experiments on noisy-label and large-scale vision tasks, in both training-from-scratch and fine-tuning settings, demonstrate that fSGLD achieves superior or comparable generalization and robustness to baseline algorithms while maintaining the computational cost of SGD, about half that of SAM. Hessian-spectrum analysis further confirms that fSGLD converges to significantly flatter minima.
TANDEM: Temporal Attention-guided Neural Differential Equations for Missingness in Time Series Classification
Aug 24, 2025



Handling missing data in time series classification remains a significant challenge in various domains. Traditional methods often rely on imputation, which may introduce bias or fail to capture the underlying temporal dynamics. In this paper, we propose TANDEM (Temporal Attention-guided Neural Differential Equations for Missingness), an attention-guided neural differential equation framework that effectively classifies time series data with missing values. Our approach integrates raw observation, interpolated control path, and continuous latent dynamics through a novel attention mechanism, allowing the model to focus on the most informative aspects of the data. We evaluate TANDEM on 30 benchmark datasets and a real-world medical dataset, demonstrating its superiority over existing state-of-the-art methods. Our framework not only improves classification accuracy but also provides insights into the handling of missing data, making it a valuable tool in practice.
Modeling Irregular Astronomical Time Series with Neural Stochastic Delay Differential Equations
Aug 24, 2025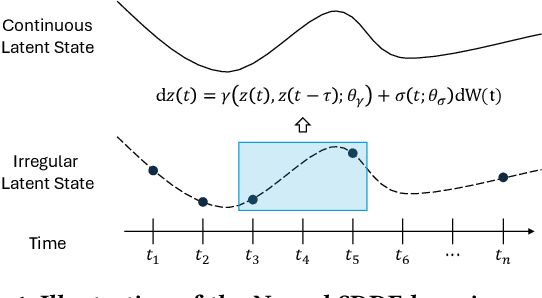
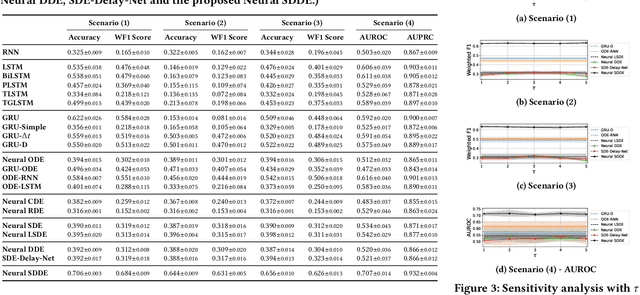
Astronomical time series from large-scale surveys like LSST are often irregularly sampled and incomplete, posing challenges for classification and anomaly detection. We introduce a new framework based on Neural Stochastic Delay Differential Equations (Neural SDDEs) that combines stochastic modeling with neural networks to capture delayed temporal dynamics and handle irregular observations. Our approach integrates a delay-aware neural architecture, a numerical solver for SDDEs, and mechanisms to robustly learn from noisy, sparse sequences. Experiments on irregularly sampled astronomical data demonstrate strong classification accuracy and effective detection of novel astrophysical events, even with partial labels. This work highlights Neural SDDEs as a principled and practical tool for time series analysis under observational constraints.
DGSAM: Domain Generalization via Individual Sharpness-Aware Minimization
Mar 30, 2025



Domain generalization (DG) aims to learn models that can generalize well to unseen domains by training only on a set of source domains. Sharpness-Aware Minimization (SAM) has been a popular approach for this, aiming to find flat minima in the total loss landscape. However, we show that minimizing the total loss sharpness does not guarantee sharpness across individual domains. In particular, SAM can converge to fake flat minima, where the total loss may exhibit flat minima, but sharp minima are present in individual domains. Moreover, the current perturbation update in gradient ascent steps is ineffective in directly updating the sharpness of individual domains. Motivated by these findings, we introduce a novel DG algorithm, Decreased-overhead Gradual Sharpness-Aware Minimization (DGSAM), that applies gradual domain-wise perturbation to reduce sharpness consistently across domains while maintaining computational efficiency. Our experiments demonstrate that DGSAM outperforms state-of-the-art DG methods, achieving improved robustness to domain shifts and better performance across various benchmarks, while reducing computational overhead compared to SAM.
Dual Cone Gradient Descent for Training Physics-Informed Neural Networks
Sep 27, 2024



Physics-informed neural networks (PINNs) have emerged as a prominent approach for solving partial differential equations (PDEs) by minimizing a combined loss function that incorporates both boundary loss and PDE residual loss. Despite their remarkable empirical performance in various scientific computing tasks, PINNs often fail to generate reasonable solutions, and such pathological behaviors remain difficult to explain and resolve. In this paper, we identify that PINNs can be adversely trained when gradients of each loss function exhibit a significant imbalance in their magnitudes and present a negative inner product value. To address these issues, we propose a novel optimization framework, Dual Cone Gradient Descent (DCGD), which adjusts the direction of the updated gradient to ensure it falls within a dual cone region. This region is defined as a set of vectors where the inner products with both the gradients of the PDE residual loss and the boundary loss are non-negative. Theoretically, we analyze the convergence properties of DCGD algorithms in a non-convex setting. On a variety of benchmark equations, we demonstrate that DCGD outperforms other optimization algorithms in terms of various evaluation metrics. In particular, DCGD achieves superior predictive accuracy and enhances the stability of training for failure modes of PINNs and complex PDEs, compared to existing optimally tuned models. Moreover, DCGD can be further improved by combining it with popular strategies for PINNs, including learning rate annealing and the Neural Tangent Kernel (NTK).
On diffusion-based generative models and their error bounds: The log-concave case with full convergence estimates
Nov 22, 2023

We provide full theoretical guarantees for the convergence behaviour of diffusion-based generative models under the assumption of strongly logconcave data distributions while our approximating class of functions used for score estimation is made of Lipschitz continuous functions. We demonstrate via a motivating example, sampling from a Gaussian distribution with unknown mean, the powerfulness of our approach. In this case, explicit estimates are provided for the associated optimization problem, i.e. score approximation, while these are combined with the corresponding sampling estimates. As a result, we obtain the best known upper bound estimates in terms of key quantities of interest, such as the dimension and rates of convergence, for the Wasserstein-2 distance between the data distribution (Gaussian with unknown mean) and our sampling algorithm. Beyond the motivating example and in order to allow for the use of a diverse range of stochastic optimizers, we present our results using an $L^2$-accurate score estimation assumption, which crucially is formed under an expectation with respect to the stochastic optimizer and our novel auxiliary process that uses only known information. This approach yields the best known convergence rate for our sampling algorithm.
Langevin dynamics based algorithm e-TH$\varepsilon$O POULA for stochastic optimization problems with discontinuous stochastic gradient
Oct 24, 2022
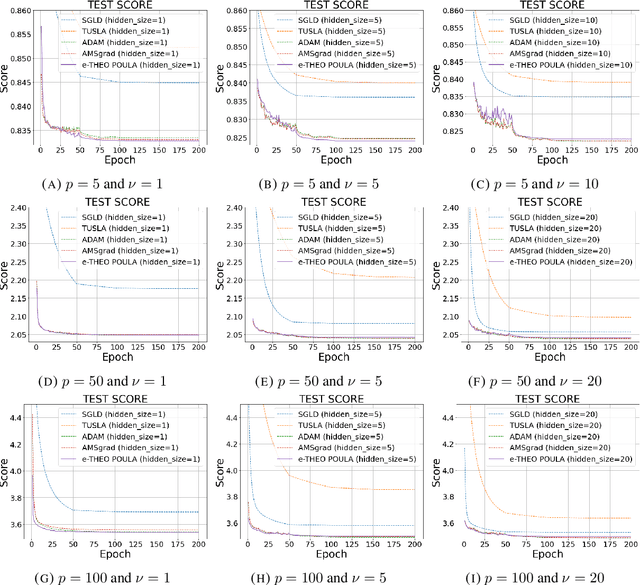
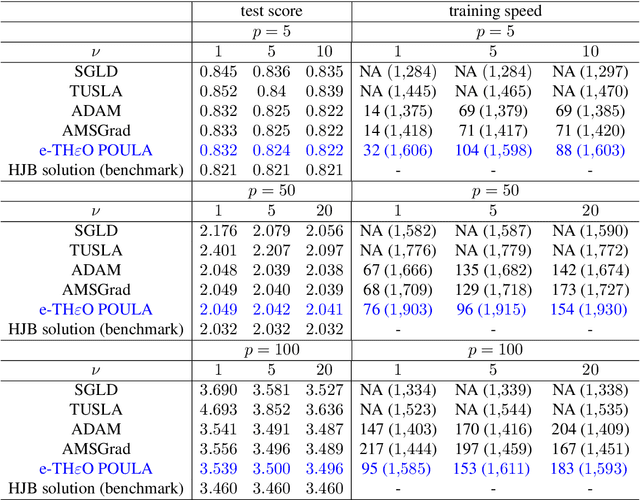
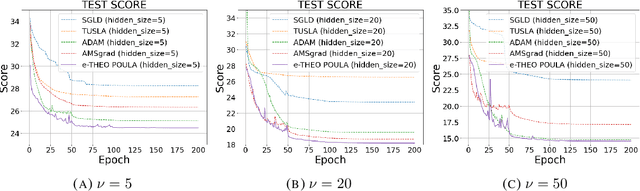
We introduce a new Langevin dynamics based algorithm, called e-TH$\varepsilon$O POULA, to solve optimization problems with discontinuous stochastic gradients which naturally appear in real-world applications such as quantile estimation, vector quantization, CVaR minimization, and regularized optimization problems involving ReLU neural networks. We demonstrate both theoretically and numerically the applicability of the e-TH$\varepsilon$O POULA algorithm. More precisely, under the conditions that the stochastic gradient is locally Lipschitz in average and satisfies a certain convexity at infinity condition, we establish non-asymptotic error bounds for e-TH$\varepsilon$O POULA in Wasserstein distances and provide a non-asymptotic estimate for the expected excess risk, which can be controlled to be arbitrarily small. Three key applications in finance and insurance are provided, namely, multi-period portfolio optimization, transfer learning in multi-period portfolio optimization, and insurance claim prediction, which involve neural networks with (Leaky)-ReLU activation functions. Numerical experiments conducted using real-world datasets illustrate the superior empirical performance of e-TH$\varepsilon$O POULA compared to SGLD, ADAM, and AMSGrad in terms of model accuracy.