 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTANDEM: Temporal Attention-guided Neural Differential Equations for Missingness in Time Series Classification
Aug 24, 2025



Handling missing data in time series classification remains a significant challenge in various domains. Traditional methods often rely on imputation, which may introduce bias or fail to capture the underlying temporal dynamics. In this paper, we propose TANDEM (Temporal Attention-guided Neural Differential Equations for Missingness), an attention-guided neural differential equation framework that effectively classifies time series data with missing values. Our approach integrates raw observation, interpolated control path, and continuous latent dynamics through a novel attention mechanism, allowing the model to focus on the most informative aspects of the data. We evaluate TANDEM on 30 benchmark datasets and a real-world medical dataset, demonstrating its superiority over existing state-of-the-art methods. Our framework not only improves classification accuracy but also provides insights into the handling of missing data, making it a valuable tool in practice.
Platform for Representation and Integration of multimodal Molecular Embeddings
Jul 10, 2025Existing machine learning methods for molecular (e.g., gene) embeddings are restricted to specific tasks or data modalities, limiting their effectiveness within narrow domains. As a result, they fail to capture the full breadth of gene functions and interactions across diverse biological contexts. In this study, we have systematically evaluated knowledge representations of biomolecules across multiple dimensions representing a task-agnostic manner spanning three major data sources, including omics experimental data, literature-derived text data, and knowledge graph-based representations. To distinguish between meaningful biological signals from chance correlations, we devised an adjusted variant of Singular Vector Canonical Correlation Analysis (SVCCA) that quantifies signal redundancy and complementarity across different data modalities and sources. These analyses reveal that existing embeddings capture largely non-overlapping molecular signals, highlighting the value of embedding integration. Building on this insight, we propose Platform for Representation and Integration of multimodal Molecular Embeddings (PRISME), a machine learning based workflow using an autoencoder to integrate these heterogeneous embeddings into a unified multimodal representation. We validated this approach across various benchmark tasks, where PRISME demonstrated consistent performance, and outperformed individual embedding methods in missing value imputations. This new framework supports comprehensive modeling of biomolecules, advancing the development of robust, broadly applicable multimodal embeddings optimized for downstream biomedical machine learning applications.
Atherosclerosis through Hierarchical Explainable Neural Network Analysis
Jul 10, 2025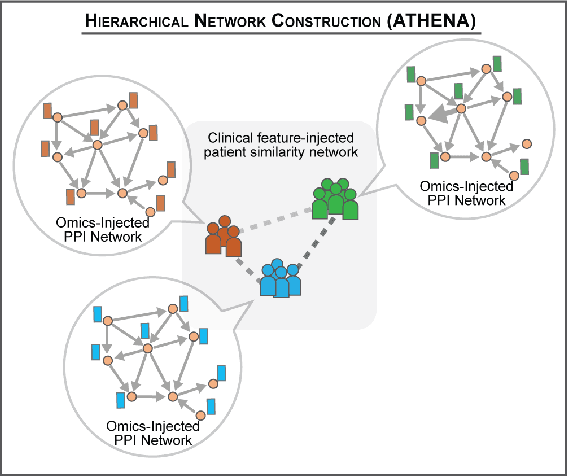

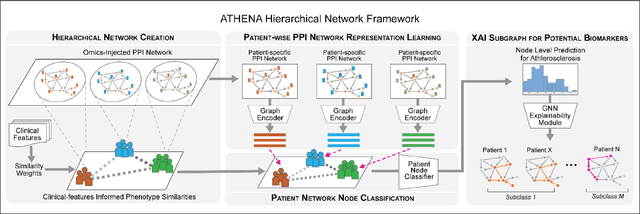
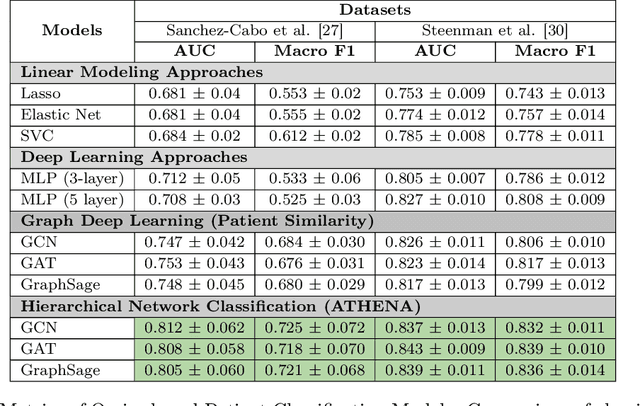
In this work, we study the problem pertaining to personalized classification of subclinical atherosclerosis by developing a hierarchical graph neural network framework to leverage two characteristic modalities of a patient: clinical features within the context of the cohort, and molecular data unique to individual patients. Current graph-based methods for disease classification detect patient-specific molecular fingerprints, but lack consistency and comprehension regarding cohort-wide features, which are an essential requirement for understanding pathogenic phenotypes across diverse atherosclerotic trajectories. Furthermore, understanding patient subtypes often considers clinical feature similarity in isolation, without integration of shared pathogenic interdependencies among patients. To address these challenges, we introduce ATHENA: Atherosclerosis Through Hierarchical Explainable Neural Network Analysis, which constructs a novel hierarchical network representation through integrated modality learning; subsequently, it optimizes learned patient-specific molecular fingerprints that reflect individual omics data, enforcing consistency with cohort-wide patterns. With a primary clinical dataset of 391 patients, we demonstrate that this heterogeneous alignment of clinical features with molecular interaction patterns has significantly boosted subclinical atherosclerosis classification performance across various baselines by up to 13% in area under the receiver operating curve (AUC) and 20% in F1 score. Taken together, ATHENA enables mechanistically-informed patient subtype discovery through explainable AI (XAI)-driven subnetwork clustering; this novel integration framework strengthens personalized intervention strategies, thereby improving the prediction of atherosclerotic disease progression and management of their clinical actionable outcomes.
Building an Ethical and Trustworthy Biomedical AI Ecosystem for the Translational and Clinical Integration of Foundational Models
Jul 18, 2024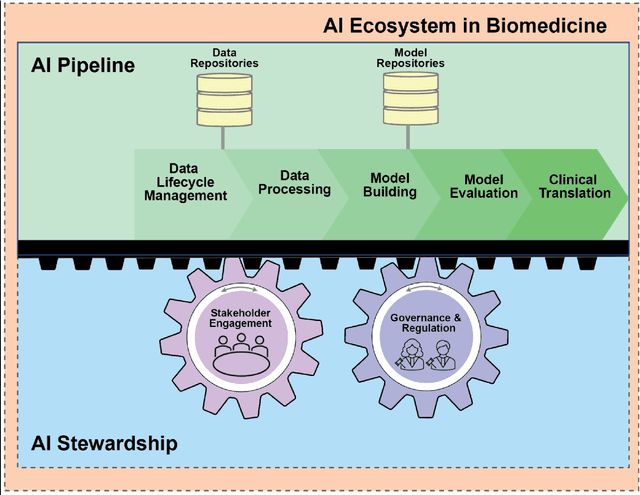
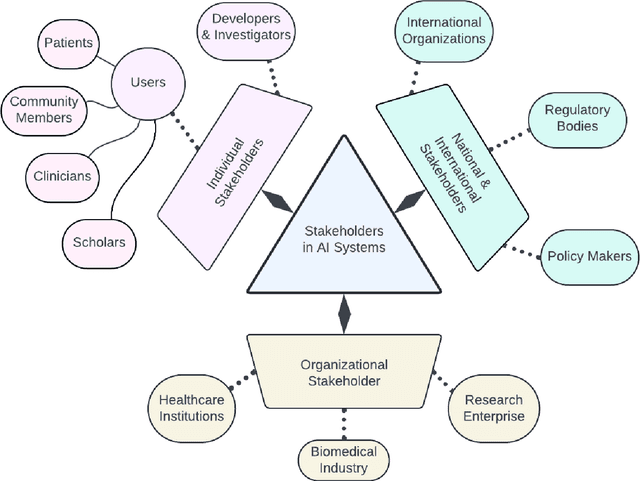
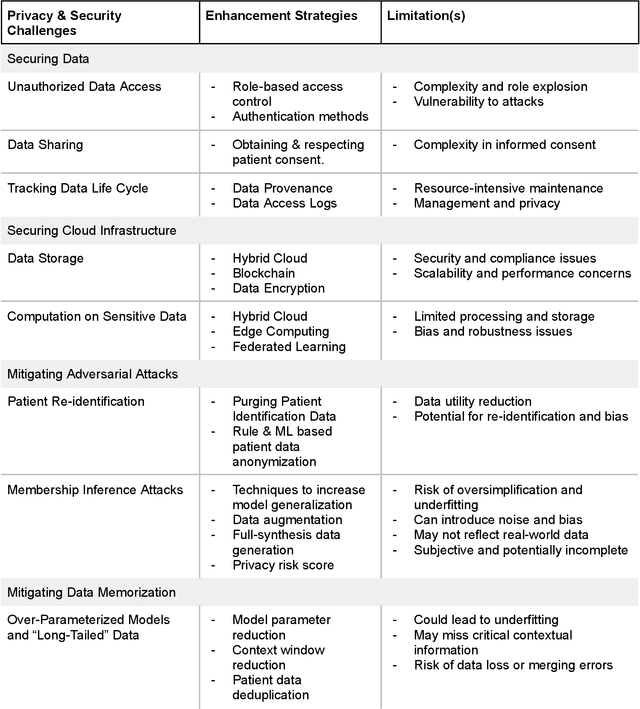
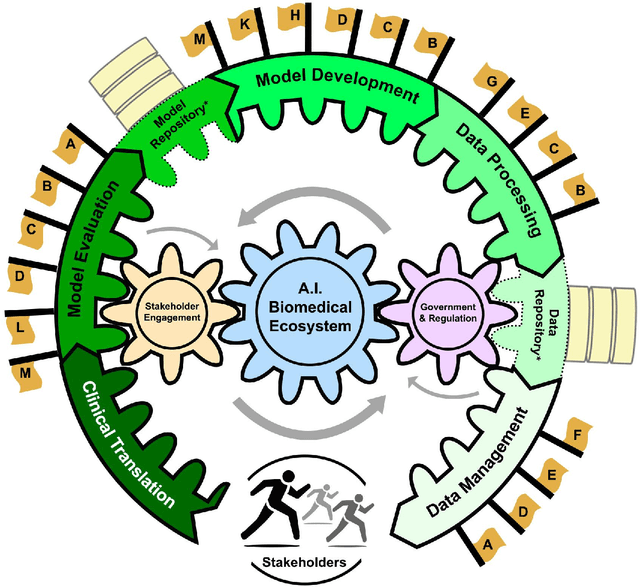
Foundational Models (FMs) are emerging as the cornerstone of the biomedical AI ecosystem due to their ability to represent and contextualize multimodal biomedical data. These capabilities allow FMs to be adapted for various tasks, including biomedical reasoning, hypothesis generation, and clinical decision-making. This review paper examines the foundational components of an ethical and trustworthy AI (ETAI) biomedical ecosystem centered on FMs, highlighting key challenges and solutions. The ETAI biomedical ecosystem is defined by seven key components which collectively integrate FMs into clinical settings: Data Lifecycle Management, Data Processing, Model Development, Model Evaluation, Clinical Translation, AI Governance and Regulation, and Stakeholder Engagement. While the potential of biomedical AI is immense, it requires heightened ethical vigilance and responsibility. For instance, biases can arise from data, algorithms, and user interactions, necessitating techniques to assess and mitigate bias prior to, during, and after model development. Moreover, interpretability, explainability, and accountability are key to ensuring the trustworthiness of AI systems, while workflow transparency in training, testing, and evaluation is crucial for reproducibility. Safeguarding patient privacy and security involves addressing challenges in data access, cloud data privacy, patient re-identification, membership inference attacks, and data memorization. Additionally, AI governance and regulation are essential for ethical AI use in biomedicine, guided by global standards. Furthermore, stakeholder engagement is essential at every stage of the AI pipeline and lifecycle for clinical translation. By adhering to these principles, we can harness the transformative potential of AI and develop an ETAI ecosystem.
EigenRank by Committee: A Data Subset Selection and Failure Prediction paradigm for Robust Deep Learning based Medical Image Segmentation
Aug 17, 2019
Translation of fully automated deep learning based medical image segmentation technologies to clinical workflows face two main algorithmic challenges. The first, is the collection and archival of large quantities of manually annotated ground truth data for both training and validation. The second is the relative inability of the majority of deep learning based segmentation techniques to alert physicians to a likely segmentation failure. Here we propose a novel algorithm, named `Eigenrank' which addresses both of these challenges. Eigenrank can select for manual labeling, a subset of medical images from a large database, such that a U-Net trained on this subset is superior to one trained on a randomly selected subset of the same size. Eigenrank can also be used to pick out, cases in a large database, where deep learning segmentation will fail. We present our algorithm, followed by results and a discussion of how Eigenrank exploits the Von Neumann information to perform both data subset selection and failure prediction for medical image segmentation using deep learning.
Extreme Augmentation : Can deep learning based medical image segmentation be trained using a single manually delineated scan?
Oct 03, 2018
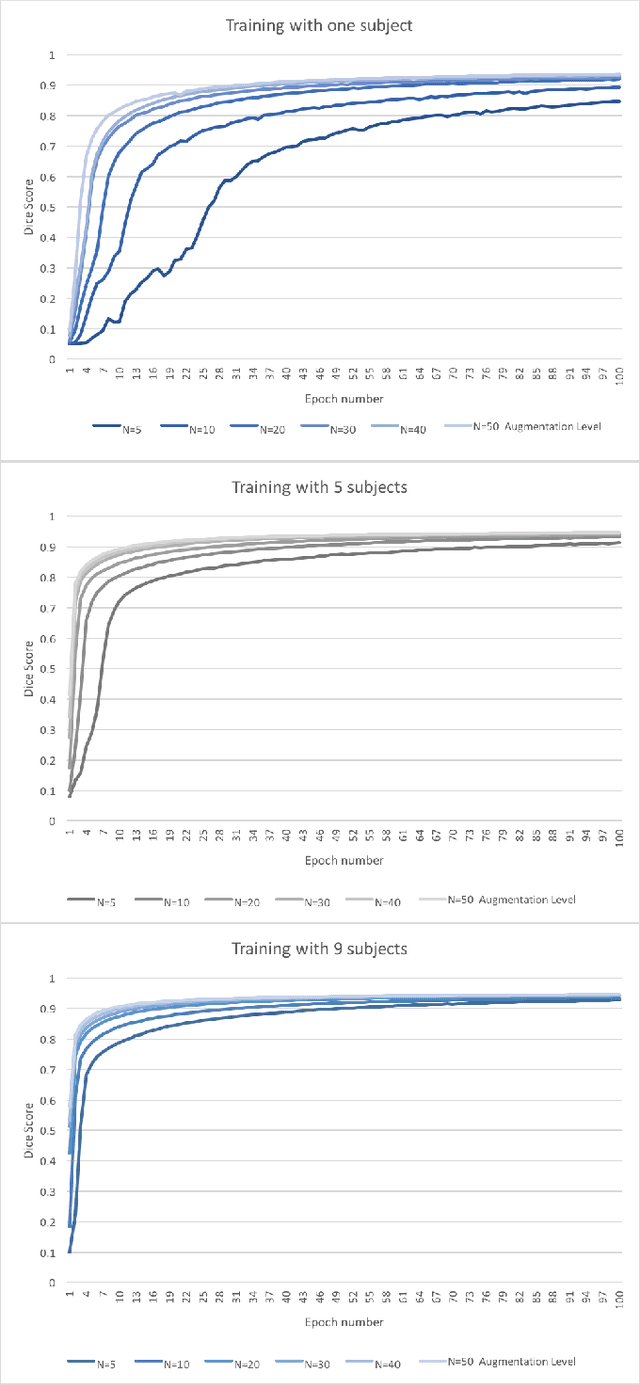
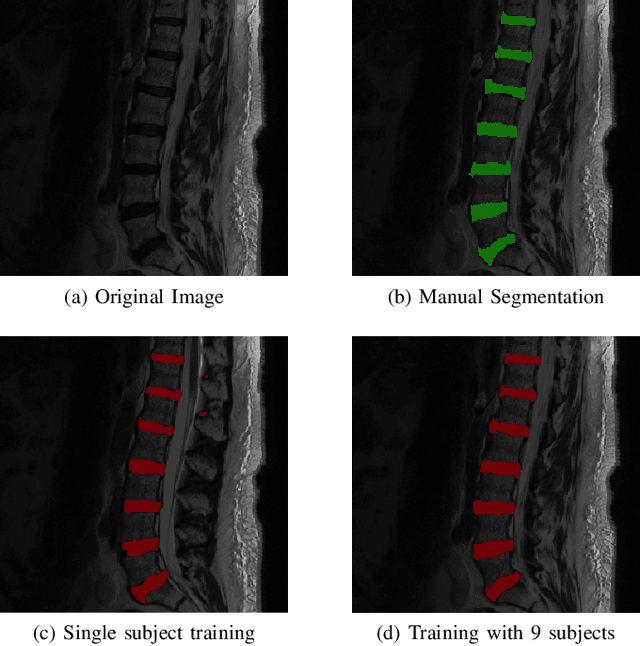
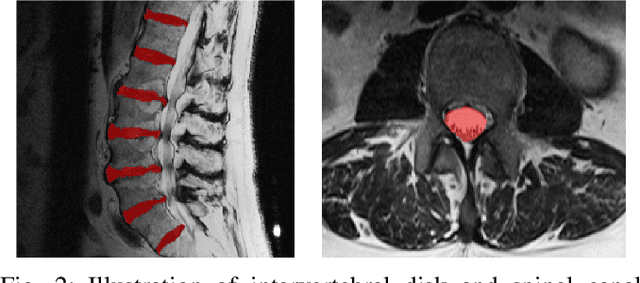
Yes, it can. Data augmentation is perhaps the oldest preprocessing step in computer vision literature. Almost every computer vision model trained on imaging data uses some form of augmentation. In this paper, we use the inter-vertebral disk segmentation task alongside a deep residual U-Net as the learning model, to explore the effectiveness of augmentation. In the extreme, we observed that a model trained on patches extracted from just one scan, with each patch augmented 50 times; achieved a Dice score of 0.73 in a validation set of 40 cases. Qualitative evaluation indicated a clinically usable segmentation algorithm, which appropriately segments regions of interest, alongside limited false positive specks. When the initial patches are extracted from nine scans the average Dice coefficient jumps to 0.86 and most of the false positives disappear. While this still falls short of state-of-the-art deep learning based segmentation of discs reported in literature, qualitative examination reveals that it does yield segmentation, which can be amended by expert clinicians with minimal effort to generate additional data for training improved deep models. Extreme augmentation of training data, should thus be construed as a strategy for training deep learning based algorithms, when very little manually annotated data is available to work with. Models trained with extreme augmentation can then be used to accelerate the generation of manually labelled data. Hence, we show that extreme augmentation can be a valuable tool in addressing scaling up small imaging data sets to address medical image segmentation tasks.