 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Augmentation : Can deep learning based medical image segmentation be trained using a single manually delineated scan?
Paper and Code
Oct 03, 2018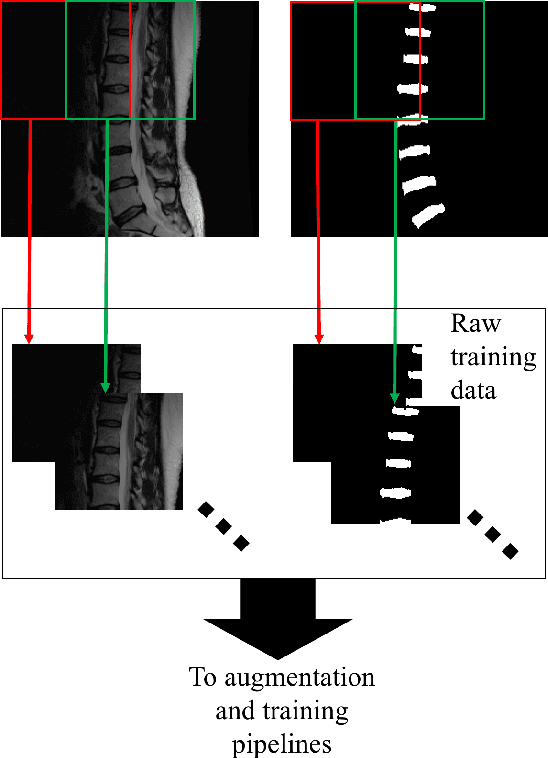
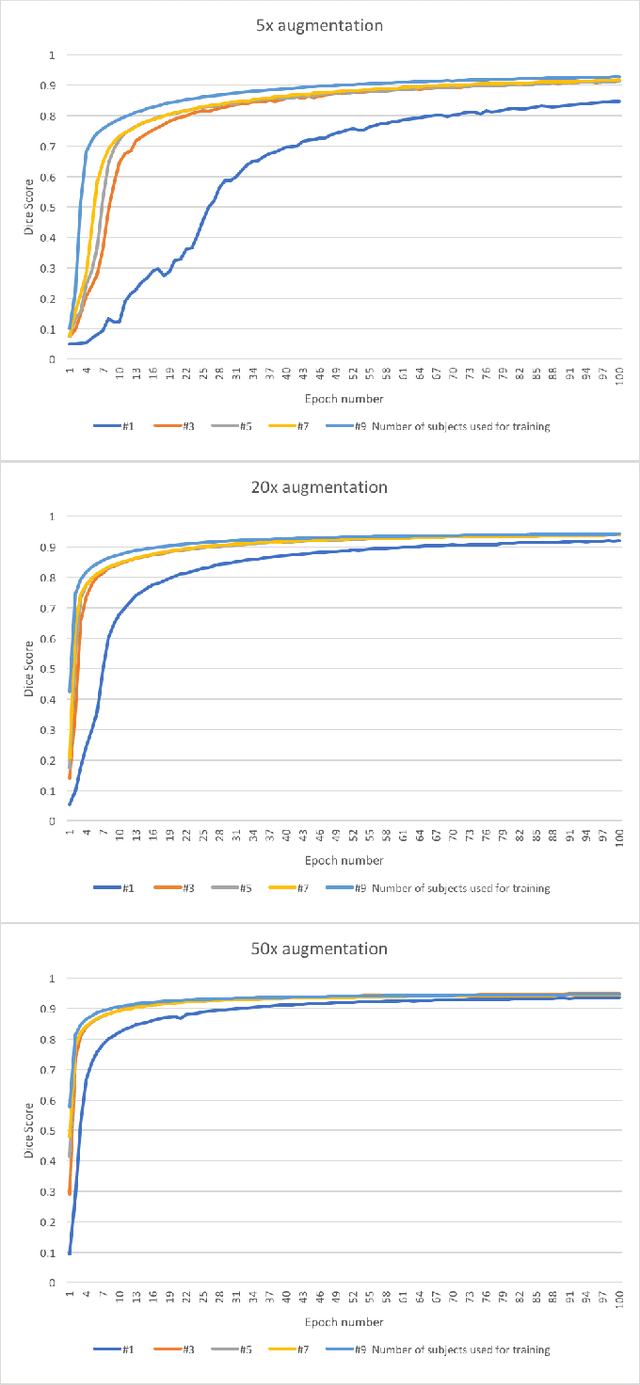
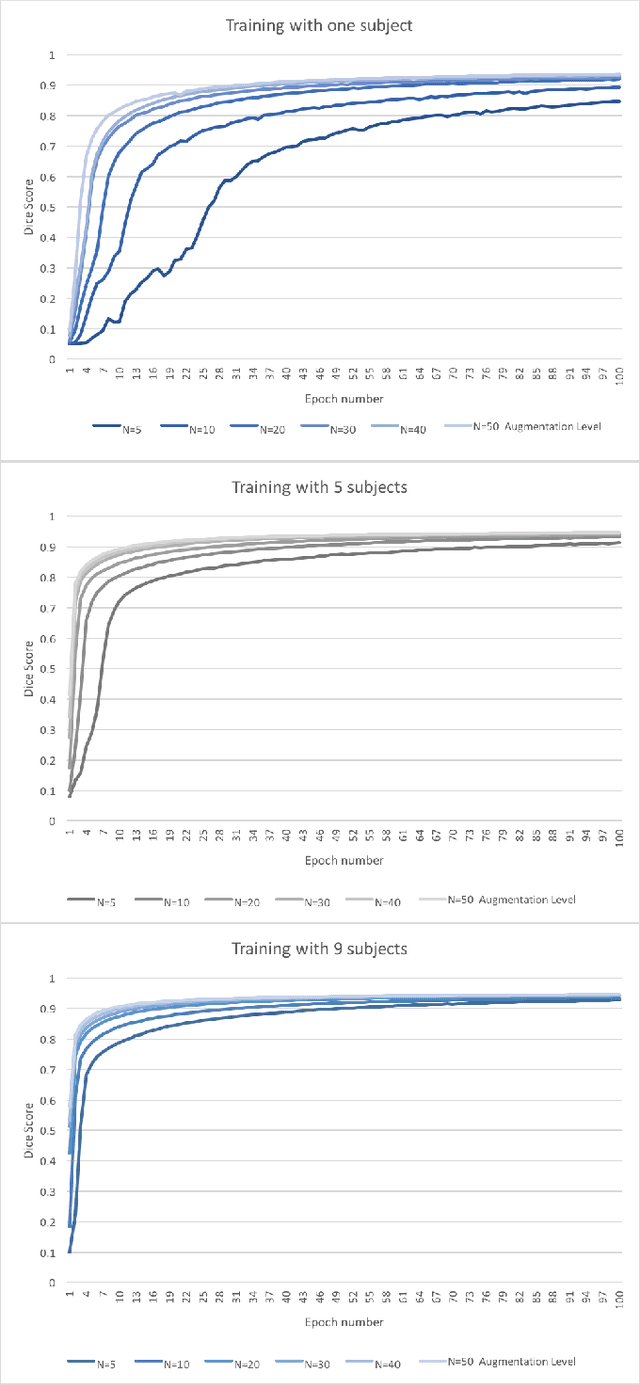
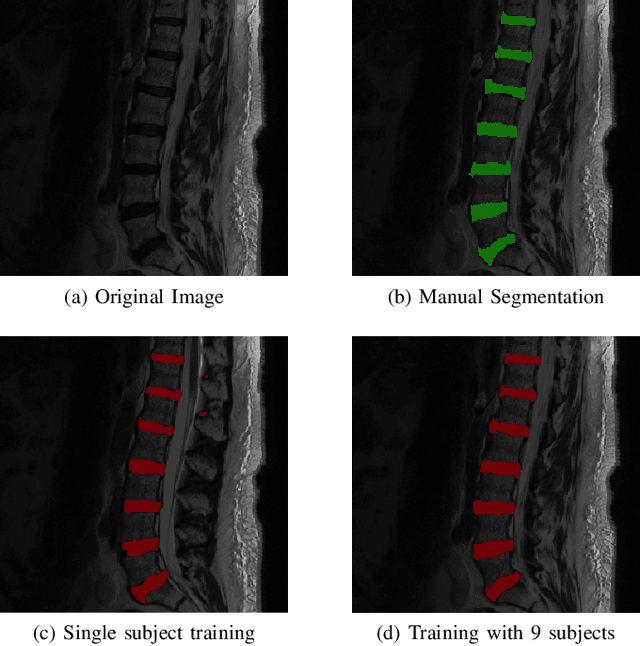
Yes, it can. Data augmentation is perhaps the oldest preprocessing step in computer vision literature. Almost every computer vision model trained on imaging data uses some form of augmentation. In this paper, we use the inter-vertebral disk segmentation task alongside a deep residual U-Net as the learning model, to explore the effectiveness of augmentation. In the extreme, we observed that a model trained on patches extracted from just one scan, with each patch augmented 50 times; achieved a Dice score of 0.73 in a validation set of 40 cases. Qualitative evaluation indicated a clinically usable segmentation algorithm, which appropriately segments regions of interest, alongside limited false positive specks. When the initial patches are extracted from nine scans the average Dice coefficient jumps to 0.86 and most of the false positives disappear. While this still falls short of state-of-the-art deep learning based segmentation of discs reported in literature, qualitative examination reveals that it does yield segmentation, which can be amended by expert clinicians with minimal effort to generate additional data for training improved deep models. Extreme augmentation of training data, should thus be construed as a strategy for training deep learning based algorithms, when very little manually annotated data is available to work with. Models trained with extreme augmentation can then be used to accelerate the generation of manually labelled data. Hence, we show that extreme augmentation can be a valuable tool in addressing scaling up small imaging data sets to address medical image segmentation tasks.