 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Expanding Convolutional Neural Networks
Jan 17, 2024In this paper, we present a novel method for dynamically expanding Convolutional Neural Networks (CNNs) during training, aimed at meeting the increasing demand for efficient and sustainable deep learning models. Our approach, drawing from the seminal work on Self-Expanding Neural Networks (SENN), employs a natural expansion score as an expansion criteria to address the common issue of over-parameterization in deep convolutional neural networks, thereby ensuring that the model's complexity is finely tuned to the task's specific needs. A significant benefit of this method is its eco-friendly nature, as it obviates the necessity of training multiple models of different sizes. We employ a strategy where a single model is dynamically expanded, facilitating the extraction of checkpoints at various complexity levels, effectively reducing computational resource use and energy consumption while also expediting the development cycle by offering diverse model complexities from a single training session. We evaluate our method on the CIFAR-10 dataset and our experimental results validate this approach, demonstrating that dynamically adding layers not only maintains but also improves CNN performance, underscoring the effectiveness of our expansion criteria. This approach marks a considerable advancement in developing adaptive, scalable, and environmentally considerate neural network architectures, addressing key challenges in the field of deep learning.
Mixtral of Experts
Jan 08, 2024



We introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e. experts). For every token, at each layer, a router network selects two experts to process the current state and combine their outputs. Even though each token only sees two experts, the selected experts can be different at each timestep. As a result, each token has access to 47B parameters, but only uses 13B active parameters during inference. Mixtral was trained with a context size of 32k tokens and it outperforms or matches Llama 2 70B and GPT-3.5 across all evaluated benchmarks. In particular, Mixtral vastly outperforms Llama 2 70B on mathematics, code generation, and multilingual benchmarks. We also provide a model fine-tuned to follow instructions, Mixtral 8x7B - Instruct, that surpasses GPT-3.5 Turbo, Claude-2.1, Gemini Pro, and Llama 2 70B - chat model on human benchmarks. Both the base and instruct models are released under the Apache 2.0 license.
1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022

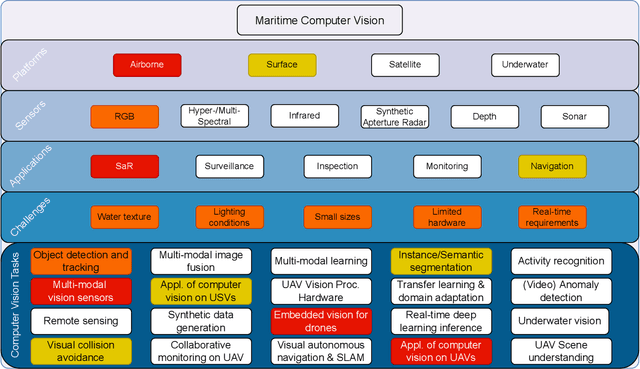
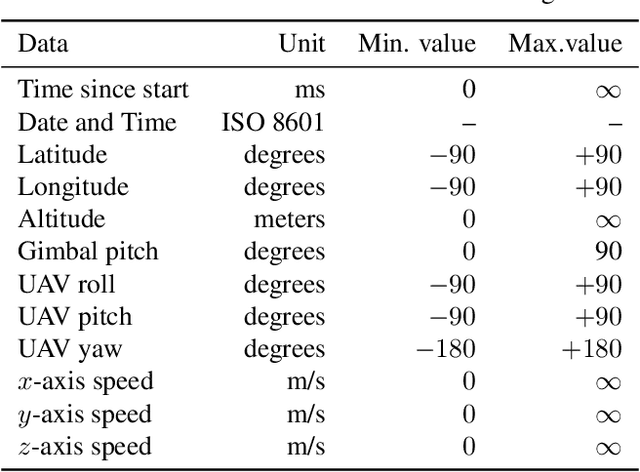
The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.