 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Consistency in Story Visualization with Rich-Contextual Conditional Diffusion Models
Jul 02, 2024



Recent research showcases the considerable potential of conditional diffusion models for generating consistent stories. However, current methods, which predominantly generate stories in an autoregressive and excessively caption-dependent manner, often underrate the contextual consistency and relevance of frames during sequential generation. To address this, we propose a novel Rich-contextual Conditional Diffusion Models (RCDMs), a two-stage approach designed to enhance story generation's semantic consistency and temporal consistency. Specifically, in the first stage, the frame-prior transformer diffusion model is presented to predict the frame semantic embedding of the unknown clip by aligning the semantic correlations between the captions and frames of the known clip. The second stage establishes a robust model with rich contextual conditions, including reference images of the known clip, the predicted frame semantic embedding of the unknown clip, and text embeddings of all captions. By jointly injecting these rich contextual conditions at the image and feature levels, RCDMs can generate semantic and temporal consistency stories. Moreover, RCDMs can generate consistent stories with a single forward inference compared to autoregressive models. Our qualitative and quantitative results demonstrate that our proposed RCDMs outperform in challenging scenarios. The code and model will be available at https://github.com/muzishen/RCDMs.
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Aug 13, 2023Recent years have witnessed the strong power of large text-to-image diffusion models for the impressive generative capability to create high-fidelity images. However, it is very tricky to generate desired images using only text prompt as it often involves complex prompt engineering. An alternative to text prompt is image prompt, as the saying goes: "an image is worth a thousand words". Although existing methods of direct fine-tuning from pretrained models are effective, they require large computing resources and are not compatible with other base models, text prompt, and structural controls. In this paper, we present IP-Adapter, an effective and lightweight adapter to achieve image prompt capability for the pretrained text-to-image diffusion models. The key design of our IP-Adapter is decoupled cross-attention mechanism that separates cross-attention layers for text features and image features. Despite the simplicity of our method, an IP-Adapter with only 22M parameters can achieve comparable or even better performance to a fully fine-tuned image prompt model. As we freeze the pretrained diffusion model, the proposed IP-Adapter can be generalized not only to other custom models fine-tuned from the same base model, but also to controllable generation using existing controllable tools. With the benefit of the decoupled cross-attention strategy, the image prompt can also work well with the text prompt to achieve multimodal image generation. The project page is available at \url{https://ip-adapter.github.io}.
LYSTO: The Lymphocyte Assessment Hackathon and Benchmark Dataset
Jan 16, 2023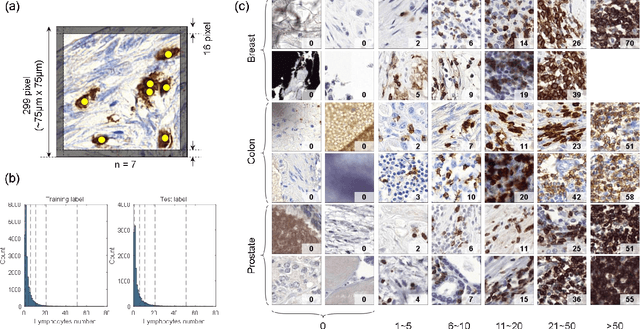
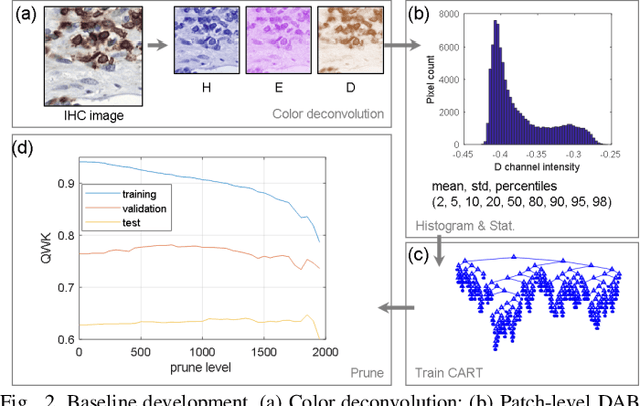
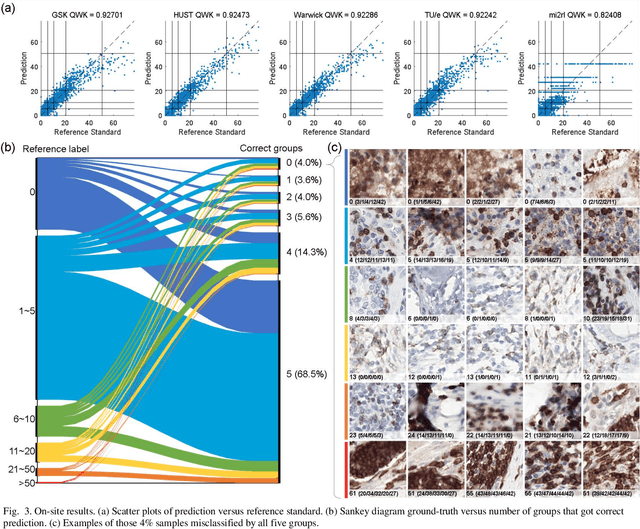
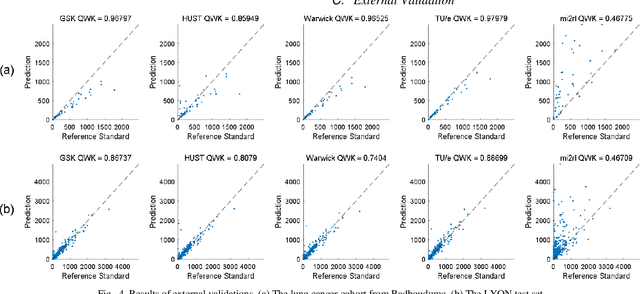
We introduce LYSTO, the Lymphocyte Assessment Hackathon, which was held in conjunction with the MICCAI 2019 Conference in Shenzen (China). The competition required participants to automatically assess the number of lymphocytes, in particular T-cells, in histopathological images of colon, breast, and prostate cancer stained with CD3 and CD8 immunohistochemistry. Differently from other challenges setup in medical image analysis, LYSTO participants were solely given a few hours to address this problem. In this paper, we describe the goal and the multi-phase organization of the hackathon; we describe the proposed methods and the on-site results. Additionally, we present post-competition results where we show how the presented methods perform on an independent set of lung cancer slides, which was not part of the initial competition, as well as a comparison on lymphocyte assessment between presented methods and a panel of pathologists. We show that some of the participants were capable to achieve pathologist-level performance at lymphocyte assessment. After the hackathon, LYSTO was left as a lightweight plug-and-play benchmark dataset on grand-challenge website, together with an automatic evaluation platform. LYSTO has supported a number of research in lymphocyte assessment in oncology. LYSTO will be a long-lasting educational challenge for deep learning and digital pathology, it is available at https://lysto.grand-challenge.org/.
Reconstruct high-resolution multi-focal plane images from a single 2D wide field image
Sep 21, 2020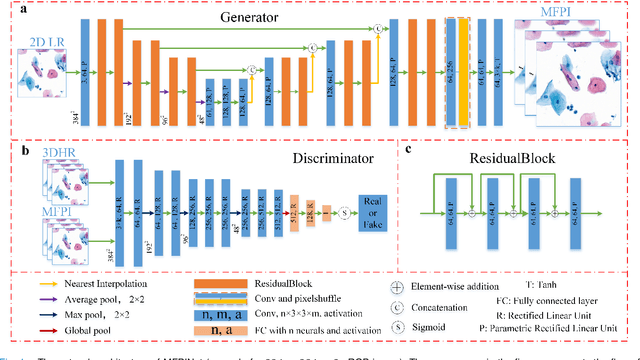
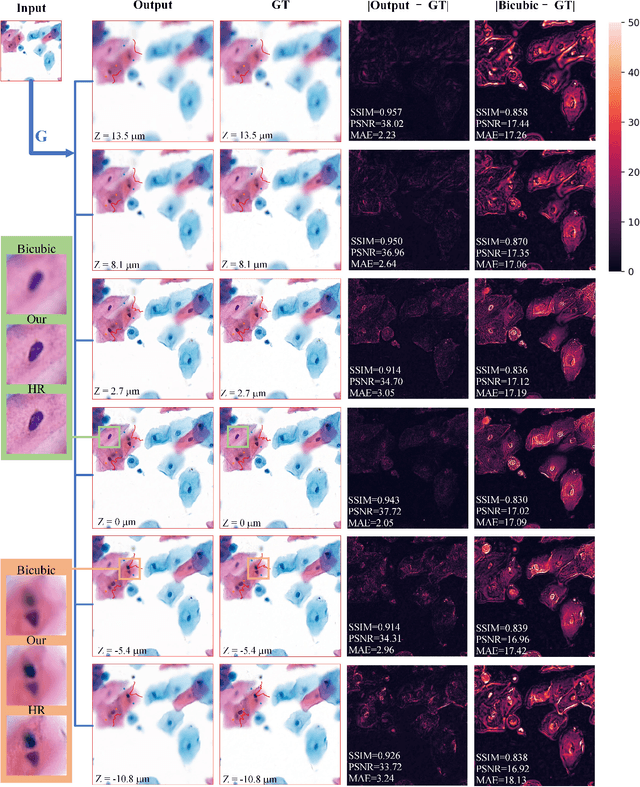
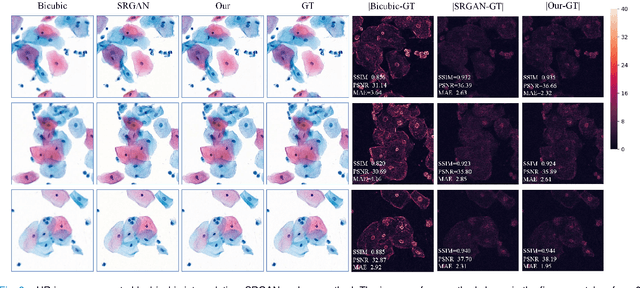

High-resolution 3D medical images are important for analysis and diagnosis, but axial scanning to acquire them is very time-consuming. In this paper, we propose a fast end-to-end multi-focal plane imaging network (MFPINet) to reconstruct high-resolution multi-focal plane images from a single 2D low-resolution wild filed image without relying on scanning. To acquire realistic MFP images fast, the proposed MFPINet adopts generative adversarial network framework and the strategies of post-sampling and refocusing all focal planes at one time. We conduct a series experiments on cytology microscopy images and demonstrate that MFPINet performs well on both axial refocusing and horizontal super resolution. Furthermore, MFPINet is approximately 24 times faster than current refocusing methods for reconstructing the same volume images. The proposed method has the potential to greatly increase the speed of high-resolution 3D imaging and expand the application of low-resolution wide-field images.