 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-MLP: Distilling Graph Knowledge from GNNs into Structure-Aware MLP
Oct 18, 2022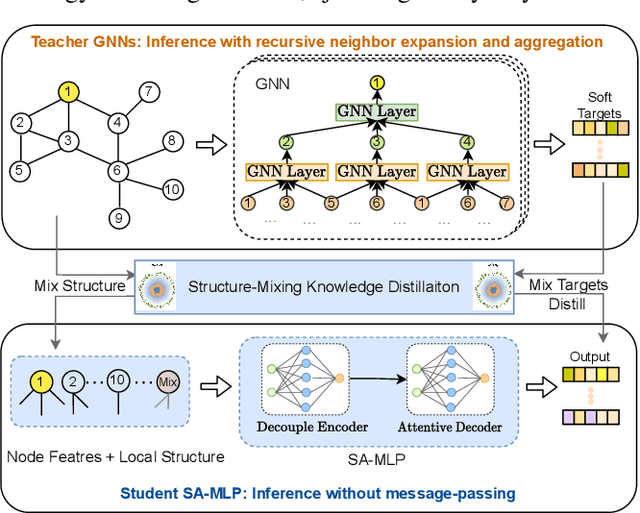
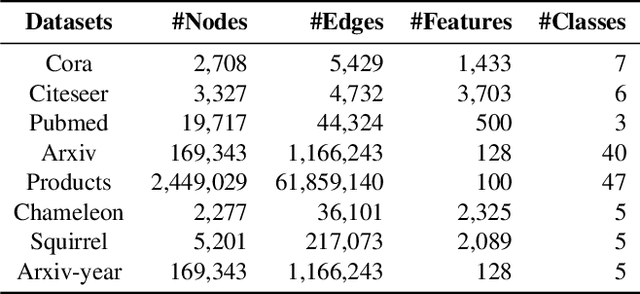
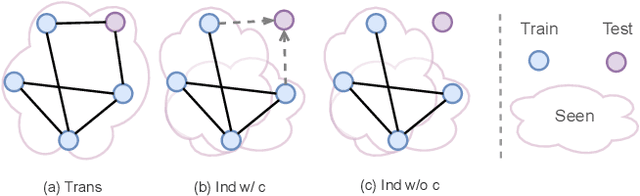
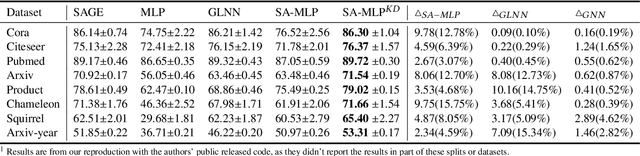
The message-passing mechanism helps Graph Neural Networks (GNNs) achieve remarkable results on various node classification tasks. Nevertheless, the recursive nodes fetching and aggregation in message-passing cause inference latency when deploying GNNs to large-scale graphs. One promising inference acceleration direction is to distill the GNNs into message-passing-free student multi-layer perceptrons (MLPs). However, the MLP student cannot fully learn the structure knowledge due to the lack of structure inputs, which causes inferior performance in the heterophily and inductive scenarios. To address this, we intend to inject structure information into MLP-like students in low-latency and interpretable ways. Specifically, we first design a Structure-Aware MLP (SA-MLP) student that encodes both features and structures without message-passing. Then, we introduce a novel structure-mixing knowledge distillation strategy to enhance the learning ability of MLPs for structure information. Furthermore, we design a latent structure embedding approximation technique with two-stage distillation for inductive scenarios. Extensive experiments on eight benchmark datasets under both transductive and inductive settings show that our SA-MLP can consistently outperform the teacher GNNs, while maintaining faster inference as MLPs. The source code of our work can be found in https://github.com/JC-202/SA-MLP.
Exploiting Neighbor Effect: Conv-Agnostic GNNs Framework for Graphs with Heterophily
Apr 09, 2022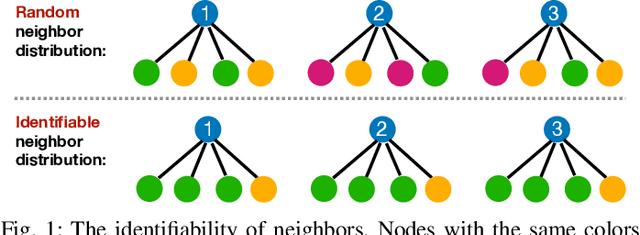
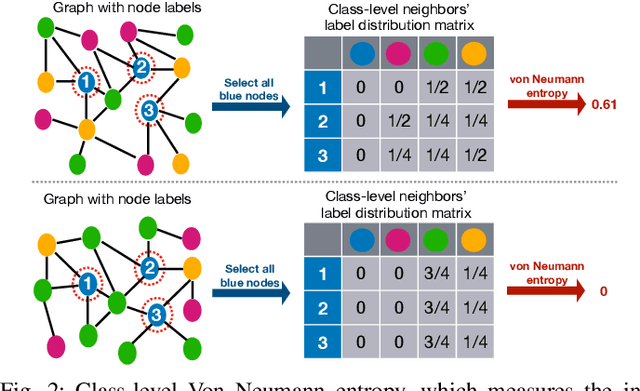
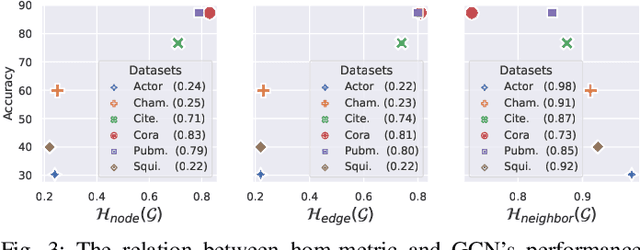
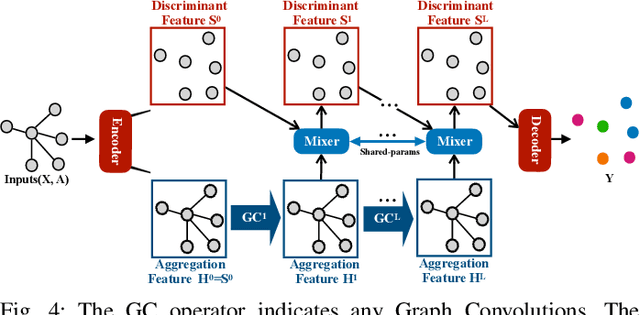
Due to the homophily assumption in graph convolution networks, a common consensus is that graph neural networks (GNNs) perform well on homophilic graphs but may fail on heterophilic graphs with many inter-class edges. In this work, we re-examine the heterophily problem of GNNs and investigate the feature aggregation of inter-class neighbors. Instead of treating the inter-class edges as harmful, under some conditions, we argue that they may provide helpful information for node classification from an entire neighbor's perspective. To better evaluate whether the neighbor is helpful for the downstream tasks, we present the concept of the neighbor effect of each node and use the von Neumann entropy to measure the randomness/identifiability of the neighbor distribution for each class. Moreover, we propose a Conv-Agnostic GNNs framework (CAGNNs) to enhance the performance of GNNs on heterophily datasets by learning the neighbor effect for each node. Specifically, we first decouple the feature of each node into the discriminative feature for downstream tasks and the aggregation feature for graph convolution. Then, we propose a shared mixer module for all layers to adaptively evaluate the neighbor effect of each node to incorporate the neighbor information. Experiments are performed on nine well-known benchmark datasets for the node classification task. The results indicate that our framework is able to improve the average prediction performance by 9.81%, 25.81%, and 20.61% for GIN, GAT, and GCN, respectively. Extensive ablation studies and robustness analysis further verify the effectiveness, robustness, and interpretability of our framework.
AgeFlow: Conditional Age Progression and Regression with Normalizing Flows
May 15, 2021
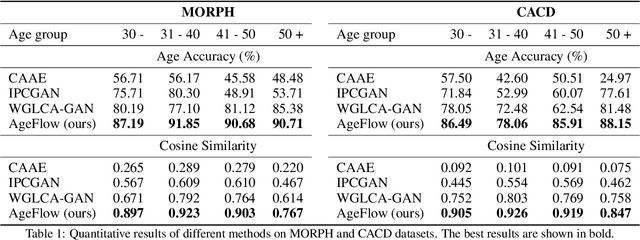
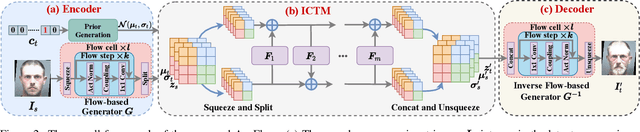
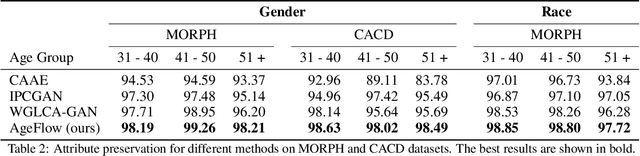
Age progression and regression aim to synthesize photorealistic appearance of a given face image with aging and rejuvenation effects, respectively. Existing generative adversarial networks (GANs) based methods suffer from the following three major issues: 1) unstable training introducing strong ghost artifacts in the generated faces, 2) unpaired training leading to unexpected changes in facial attributes such as genders and races, and 3) non-bijective age mappings increasing the uncertainty in the face transformation. To overcome these issues, this paper proposes a novel framework, termed AgeFlow, to integrate the advantages of both flow-based models and GANs. The proposed AgeFlow contains three parts: an encoder that maps a given face to a latent space through an invertible neural network, a novel invertible conditional translation module (ICTM) that translates the source latent vector to target one, and a decoder that reconstructs the generated face from the target latent vector using the same encoder network; all parts are invertible achieving bijective age mappings. The novelties of ICTM are two-fold. First, we propose an attribute-aware knowledge distillation to learn the manipulation direction of age progression while keeping other unrelated attributes unchanged, alleviating unexpected changes in facial attributes. Second, we propose to use GANs in the latent space to ensure the learned latent vector indistinguishable from the real ones, which is much easier than traditional use of GANs in the image domain. Experimental results demonstrate superior performance over existing GANs-based methods on two benchmarked datasets. The source code is available at https://github.com/Hzzone/AgeFlow.
Graph Decoupling Attention Markov Networks for Semi-supervised Graph Node Classification
Apr 28, 2021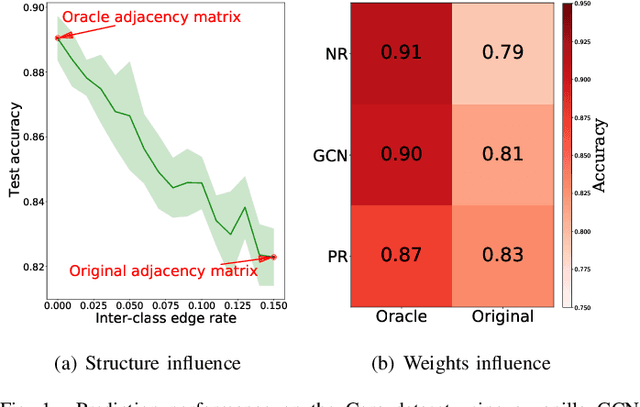
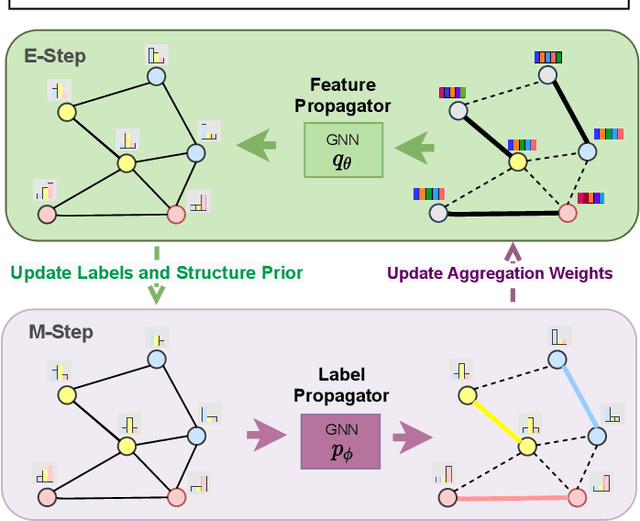
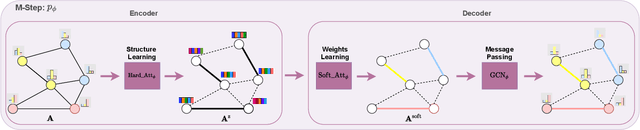
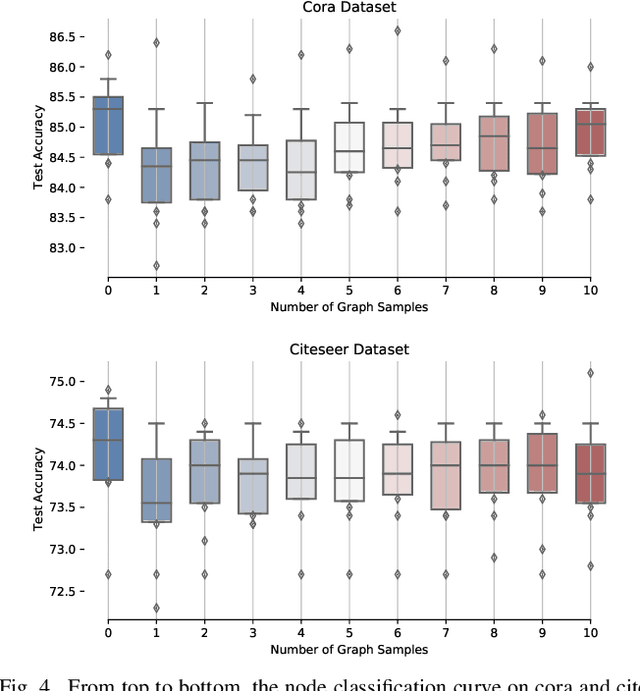
Graph neural networks (GNN) have been ubiquitous in graph learning tasks such as node classification. Most of GNN methods update the node embedding iteratively by aggregating its neighbors' information. However, they often suffer from negative disturbance, due to edges connecting nodes with different labels. One approach to alleviate this negative disturbance is to use attention, but current attention always considers feature similarity and suffers from the lack of supervision. In this paper, we consider the label dependency of graph nodes and propose a decoupling attention mechanism to learn both hard and soft attention. The hard attention is learned on labels for a refined graph structure with fewer inter-class edges. Its purpose is to reduce the aggregation's negative disturbance. The soft attention is learned on features maximizing the information gain by message passing over better graph structures. Moreover, the learned attention guides the label propagation and the feature propagation. Extensive experiments are performed on five well-known benchmark graph datasets to verify the effectiveness of the proposed method.
PFA-GAN: Progressive Face Aging with Generative Adversarial Network
Dec 07, 2020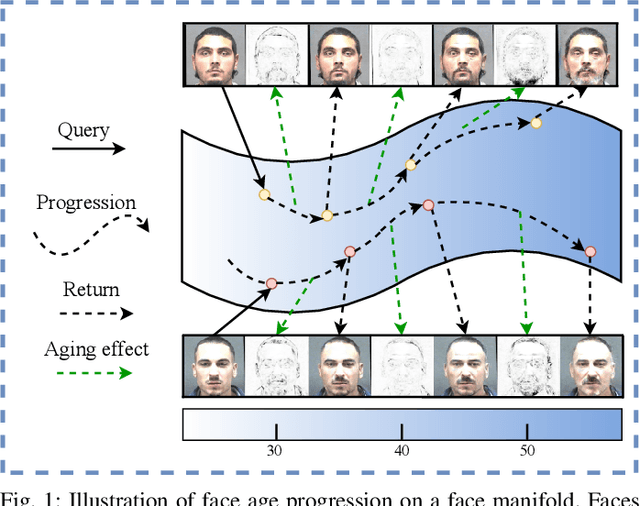



Face aging is to render a given face to predict its future appearance, which plays an important role in the information forensics and security field as the appearance of the face typically varies with age. Although impressive results have been achieved with conditional generative adversarial networks (cGANs), the existing cGANs-based methods typically use a single network to learn various aging effects between any two different age groups. However, they cannot simultaneously meet three essential requirements of face aging -- including image quality, aging accuracy, and identity preservation -- and usually generate aged faces with strong ghost artifacts when the age gap becomes large. Inspired by the fact that faces gradually age over time, this paper proposes a novel progressive face aging framework based on generative adversarial network (PFA-GAN) to mitigate these issues. Unlike the existing cGANs-based methods, the proposed framework contains several sub-networks to mimic the face aging process from young to old, each of which only learns some specific aging effects between two adjacent age groups. The proposed framework can be trained in an end-to-end manner to eliminate accumulative artifacts and blurriness. Moreover, this paper introduces an age estimation loss to take into account the age distribution for an improved aging accuracy, and proposes to use the Pearson correlation coefficient as an evaluation metric measuring the aging smoothness for face aging methods. Extensively experimental results demonstrate superior performance over existing (c)GANs-based methods, including the state-of-the-art one, on two benchmarked datasets. The source code is available at~\url{https://github.com/Hzzone/PFA-GAN}.
STAS: Adaptive Selecting Spatio-Temporal Deep Features for Improving Bias Correction on Precipitation
Apr 13, 2020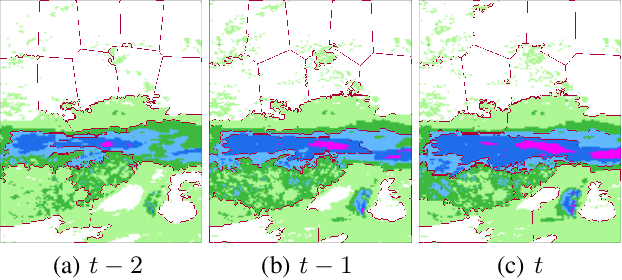

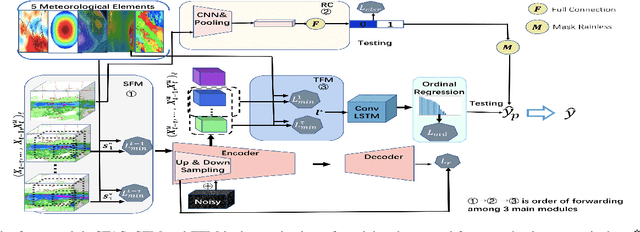
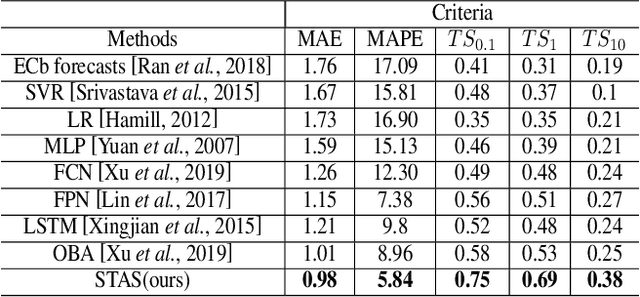
Numerical Weather Prediction (NWP) can reduce human suffering by predicting disastrous precipitation in time. A commonly-used NWP in the world is the European Centre for medium-range weather forecasts (EC). However, it is necessary to correct EC forecast through Bias Correcting on Precipitation (BCoP) since we still have not fully understood the mechanism of precipitation, making EC often have some biases. The existing BCoPs suffers from limited prior data and the fixed Spatio-Temporal (ST) scale. We thus propose an end-to-end deep-learning BCoP model named Spatio-Temporal feature Auto-Selective (STAS) model to select optimal ST regularity from EC via the ST Feature-selective Mechanisms (SFM/TFM). Given different input features, these two mechanisms can automatically adjust the spatial and temporal scales for correcting. Experiments on an EC public dataset indicate that compared with 8 published BCoP methods, STAS shows state-of-the-art performance on several criteria of BCoP, named threat scores (TS). Further, ablation studies justify that the SFM/TFM indeed work well in boosting the performance of BCoP, especially on the heavy precipitation.