 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Driven Processes for Continuous-Time Control
Oct 30, 2025At the heart of reinforcement learning are actions -- decisions made in response to observations of the environment. Actions are equally fundamental in the modeling of stochastic processes, as they trigger discontinuous state transitions and enable the flow of information through large, complex systems. In this paper, we unify the perspectives of stochastic processes and reinforcement learning through action-driven processes, and illustrate their application to spiking neural networks. Leveraging ideas from control-as-inference, we show that minimizing the Kullback-Leibler divergence between a policy-driven true distribution and a reward-driven model distribution for a suitably defined action-driven process is equivalent to maximum entropy reinforcement learning.
Word2rate: training and evaluating multiple word embeddings as statistical transitions
Apr 16, 2021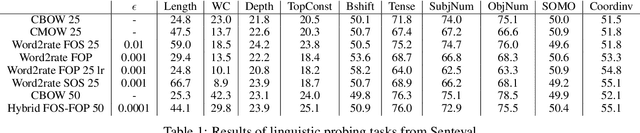
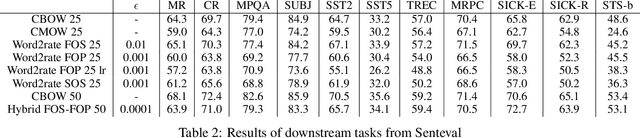
Using pretrained word embeddings has been shown to be a very effective way in improving the performance of natural language processing tasks. In fact almost any natural language tasks that can be thought of has been improved by these pretrained embeddings. These tasks range from sentiment analysis, translation, sequence prediction amongst many others. One of the most successful word embeddings is the Word2vec CBOW model proposed by Mikolov trained by the negative sampling technique. Mai et al. modifies this objective to train CMOW embeddings that are sensitive to word order. We used a modified version of the negative sampling objective for our context words, modelling the context embeddings as a Taylor series of rate matrices. We show that different modes of the Taylor series produce different types of embeddings. We compare these embeddings to their similar counterparts like CBOW and CMOW and show that they achieve comparable performance. We also introduce a novel left-right context split objective that improves performance for tasks sensitive to word order. Our Word2rate model is grounded in a statistical foundation using rate matrices while being competitive in variety of language tasks.
Dependently Typed Knowledge Graphs
Mar 08, 2020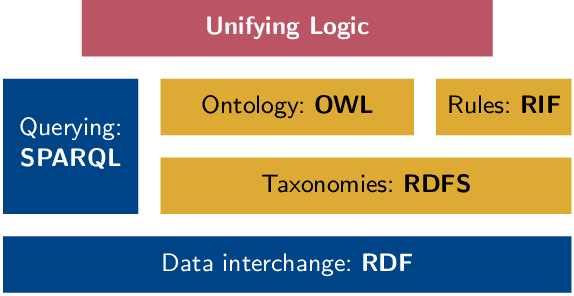
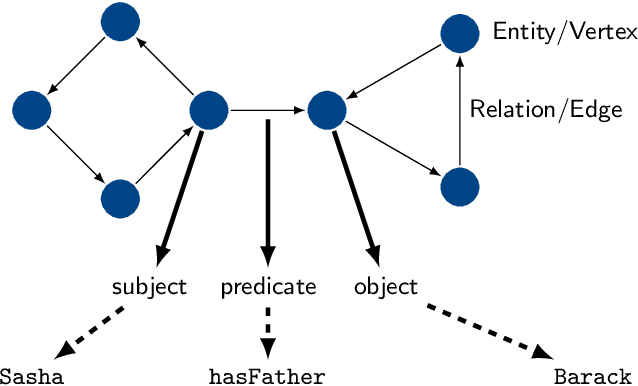
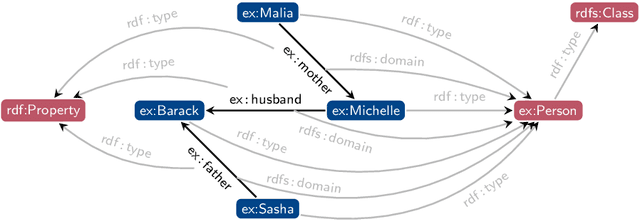

Reasoning over knowledge graphs is traditionally built upon a hierarchy of languages in the Semantic Web Stack. Starting from the Resource Description Framework (RDF) for knowledge graphs, more advanced constructs have been introduced through various syntax extensions to add reasoning capabilities to knowledge graphs. In this paper, we show how standardized semantic web technologies (RDF and its query language SPARQL) can be reproduced in a unified manner with dependent type theory. In addition to providing the basic functionalities of knowledge graphs, dependent types add expressiveness in encoding both entities and queries, explainability in answers to queries through witnesses, and compositionality and automation in the construction of witnesses. Using the Coq proof assistant, we demonstrate how to build and query dependently typed knowledge graphs as a proof of concept for future works in this direction.
Biologically Plausible Sequence Learning with Spiking Neural Networks
Nov 25, 2019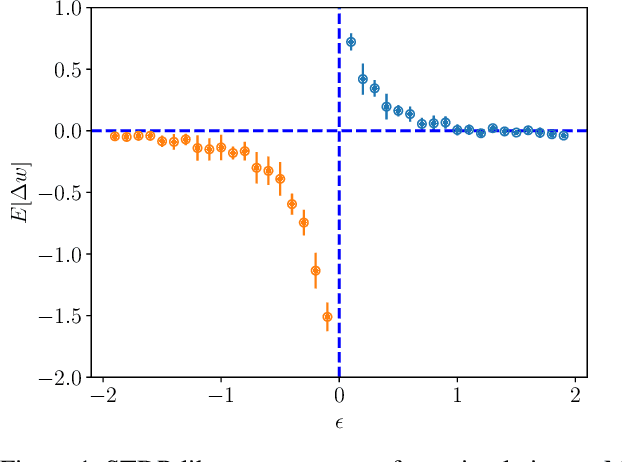
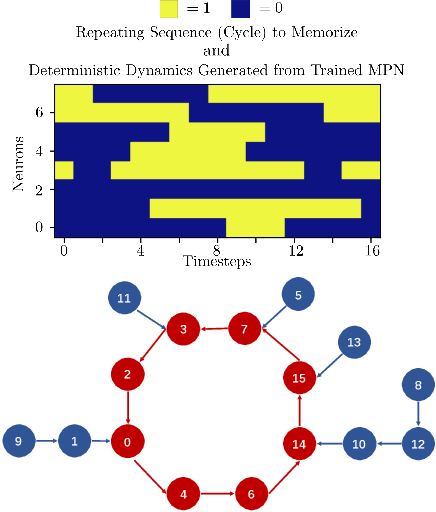


Motivated by the celebrated discrete-time model of nervous activity outlined by McCulloch and Pitts in 1943, we propose a novel continuous-time model, the McCulloch-Pitts network (MPN), for sequence learning in spiking neural networks. Our model has a local learning rule, such that the synaptic weight updates depend only on the information directly accessible by the synapse. By exploiting asymmetry in the connections between binary neurons, we show that MPN can be trained to robustly memorize multiple spatiotemporal patterns of binary vectors, generalizing the ability of the symmetric Hopfield network to memorize static spatial patterns. In addition, we demonstrate that the model can efficiently learn sequences of binary pictures as well as generative models for experimental neural spike-train data. Our learning rule is consistent with spike-timing-dependent plasticity (STDP), thus providing a theoretical ground for the systematic design of biologically inspired networks with large and robust long-range sequence storage capacity.
Variational Probability Flow for Biologically Plausible Training of Deep Neural Networks
Nov 21, 2017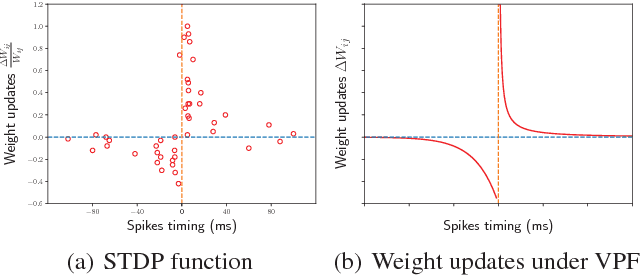
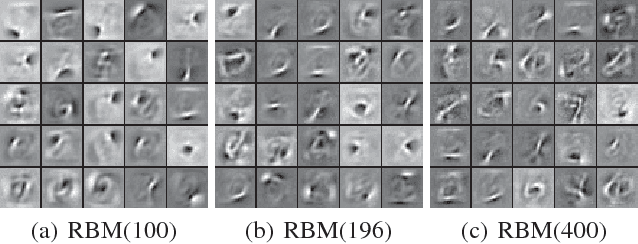
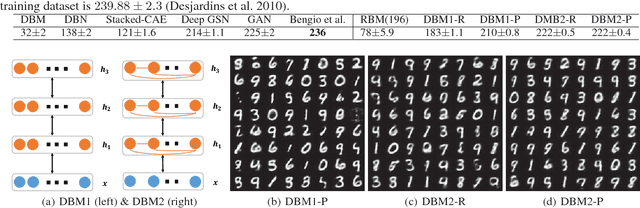
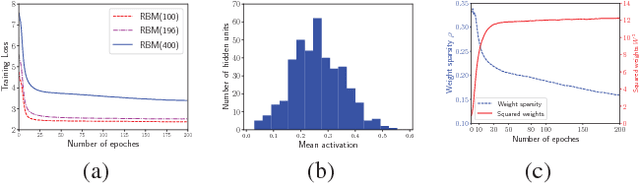
The quest for biologically plausible deep learning is driven, not just by the desire to explain experimentally-observed properties of biological neural networks, but also by the hope of discovering more efficient methods for training artificial networks. In this paper, we propose a new algorithm named Variational Probably Flow (VPF), an extension of minimum probability flow for training binary Deep Boltzmann Machines (DBMs). We show that weight updates in VPF are local, depending only on the states and firing rates of the adjacent neurons. Unlike contrastive divergence, there is no need for Gibbs confabulations; and unlike backpropagation, alternating feedforward and feedback phases are not required. Moreover, the learning algorithm is effective for training DBMs with intra-layer connections between the hidden nodes. Experiments with MNIST and Fashion MNIST demonstrate that VPF learns reasonable features quickly, reconstructs corrupted images more accurately, and generates samples with a high estimated log-likelihood. Lastly, we note that, interestingly, if an asymmetric version of VPF exists, the weight updates directly explain experimental results in Spike-Timing-Dependent Plasticity (STDP).
Deep Activity Recognition Models with Triaxial Accelerometers
Oct 25, 2016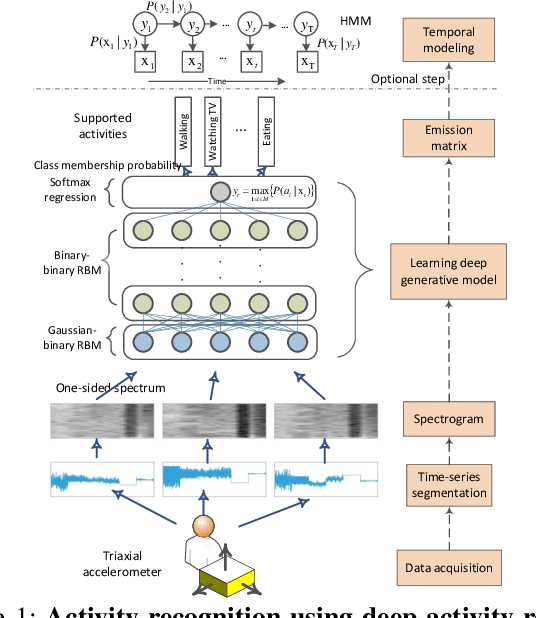
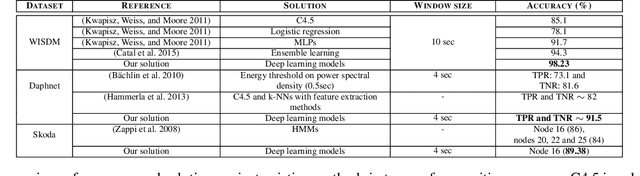
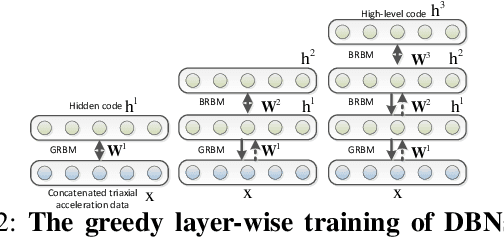
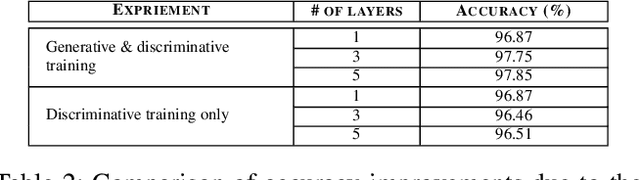
Despite the widespread installation of accelerometers in almost all mobile phones and wearable devices, activity recognition using accelerometers is still immature due to the poor recognition accuracy of existing recognition methods and the scarcity of labeled training data. We consider the problem of human activity recognition using triaxial accelerometers and deep learning paradigms. This paper shows that deep activity recognition models (a) provide better recognition accuracy of human activities, (b) avoid the expensive design of handcrafted features in existing systems, and (c) utilize the massive unlabeled acceleration samples for unsupervised feature extraction. Moreover, a hybrid approach of deep learning and hidden Markov models (DL-HMM) is presented for sequential activity recognition. This hybrid approach integrates the hierarchical representations of deep activity recognition models with the stochastic modeling of temporal sequences in the hidden Markov models. We show substantial recognition improvement on real world datasets over state-of-the-art methods of human activity recognition using triaxial accelerometers.
Mobile Big Data Analytics Using Deep Learning and Apache Spark
Feb 23, 2016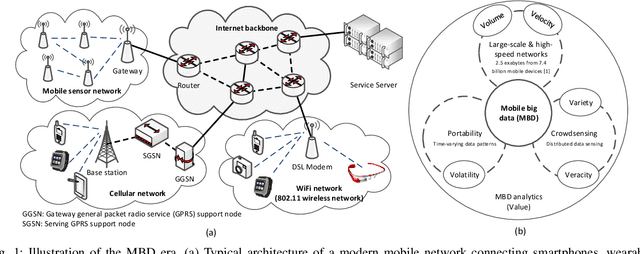
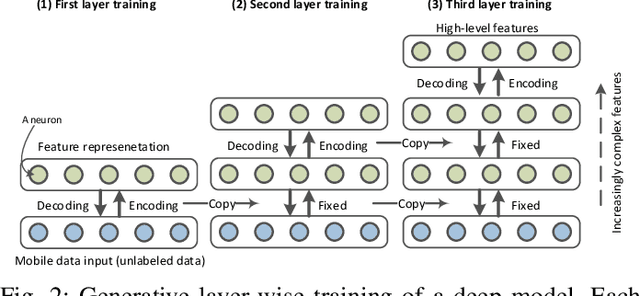
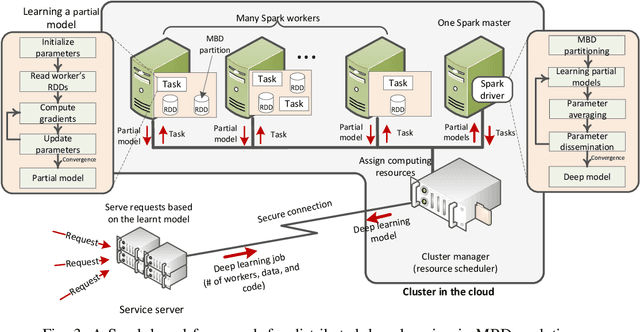
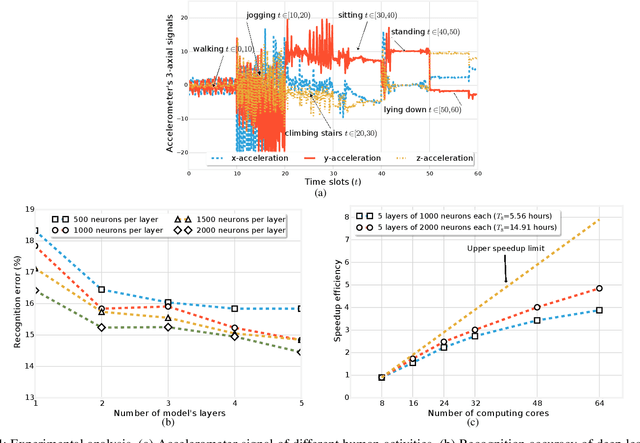
The proliferation of mobile devices, such as smartphones and Internet of Things (IoT) gadgets, results in the recent mobile big data (MBD) era. Collecting MBD is unprofitable unless suitable analytics and learning methods are utilized for extracting meaningful information and hidden patterns from data. This article presents an overview and brief tutorial of deep learning in MBD analytics and discusses a scalable learning framework over Apache Spark. Specifically, a distributed deep learning is executed as an iterative MapReduce computing on many Spark workers. Each Spark worker learns a partial deep model on a partition of the overall MBD, and a master deep model is then built by averaging the parameters of all partial models. This Spark-based framework speeds up the learning of deep models consisting of many hidden layers and millions of parameters. We use a context-aware activity recognition application with a real-world dataset containing millions of samples to validate our framework and assess its speedup effectiveness.
Marginal likelihood and model selection for Gaussian latent tree and forest models
Dec 23, 2015
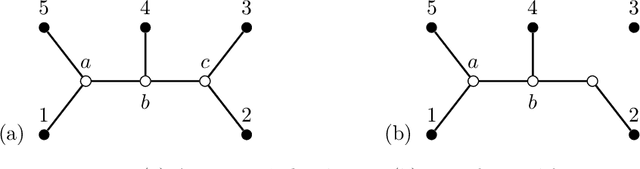
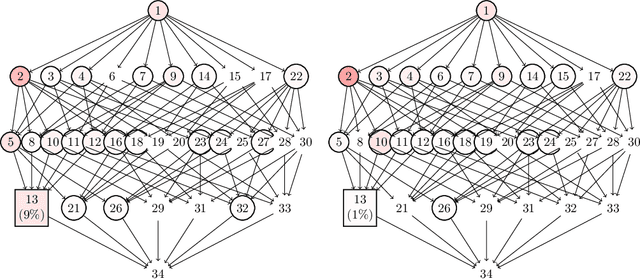

Gaussian latent tree models, or more generally, Gaussian latent forest models have Fisher-information matrices that become singular along interesting submodels, namely, models that correspond to subforests. For these singularities, we compute the real log-canonical thresholds (also known as stochastic complexities or learning coefficients) that quantify the large-sample behavior of the marginal likelihood in Bayesian inference. This provides the information needed for a recently introduced generalization of the Bayesian information criterion. Our mathematical developments treat the general setting of Laplace integrals whose phase functions are sums of squared differences between monomials and constants. We clarify how in this case real log-canonical thresholds can be computed using polyhedral geometry, and we show how to apply the general theory to the Laplace integrals associated with Gaussian latent tree and forest models. In simulations and a data example, we demonstrate how the mathematical knowledge can be applied in model selection.
Toward a Robust Sparse Data Representation for Wireless Sensor Networks
Aug 02, 2015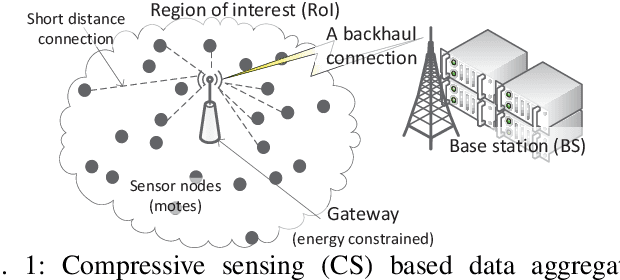
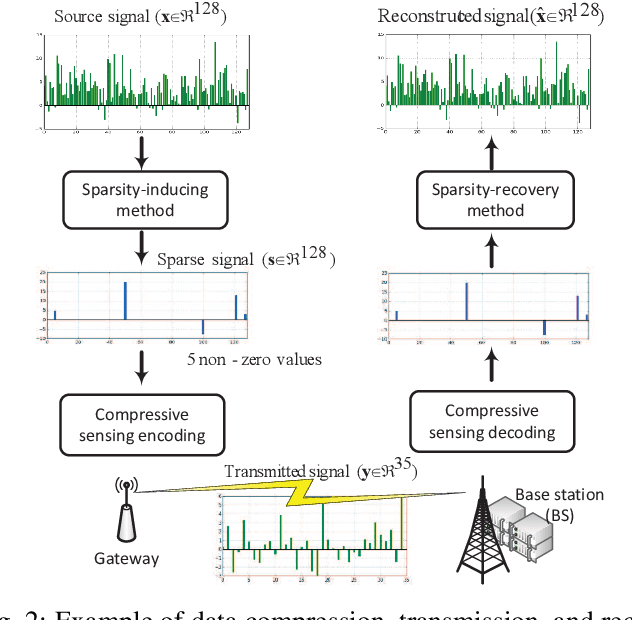
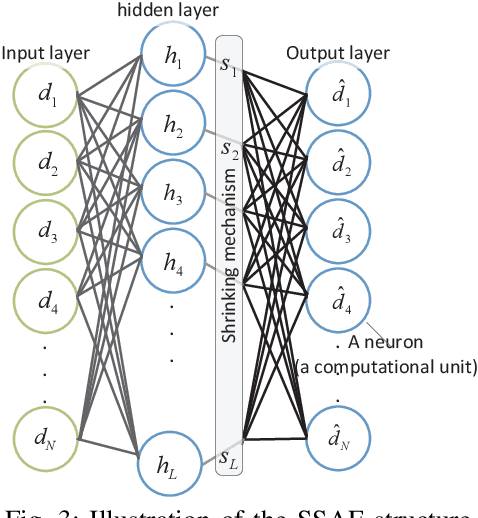

Compressive sensing has been successfully used for optimized operations in wireless sensor networks. However, raw data collected by sensors may be neither originally sparse nor easily transformed into a sparse data representation. This paper addresses the problem of transforming source data collected by sensor nodes into a sparse representation with a few nonzero elements. Our contributions that address three major issues include: 1) an effective method that extracts population sparsity of the data, 2) a sparsity ratio guarantee scheme, and 3) a customized learning algorithm of the sparsifying dictionary. We introduce an unsupervised neural network to extract an intrinsic sparse coding of the data. The sparse codes are generated at the activation of the hidden layer using a sparsity nomination constraint and a shrinking mechanism. Our analysis using real data samples shows that the proposed method outperforms conventional sparsity-inducing methods.
* 8 pages
Machine Learning in Wireless Sensor Networks: Algorithms, Strategies, and Applications
Mar 19, 2015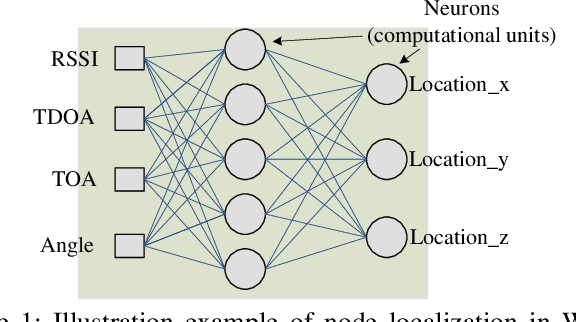
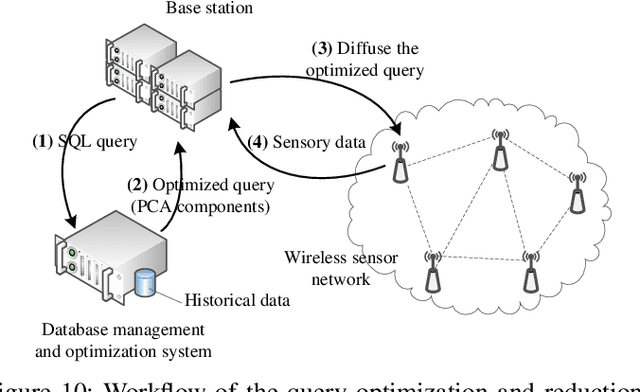
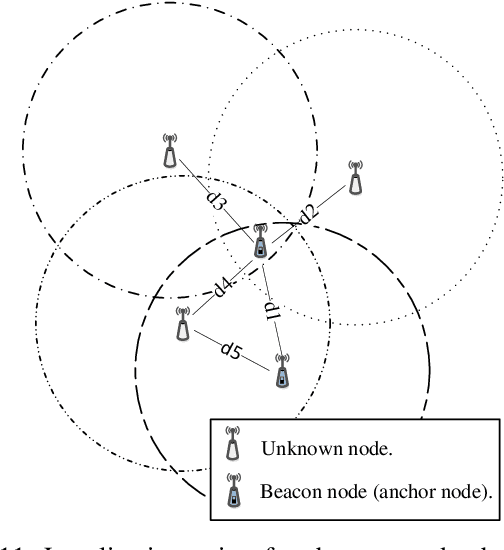
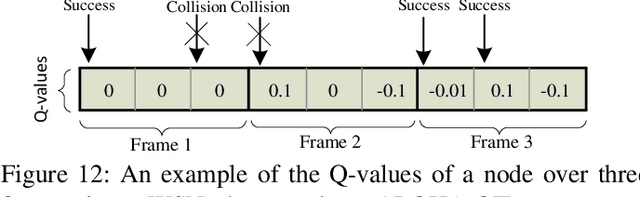
Wireless sensor networks monitor dynamic environments that change rapidly over time. This dynamic behavior is either caused by external factors or initiated by the system designers themselves. To adapt to such conditions, sensor networks often adopt machine learning techniques to eliminate the need for unnecessary redesign. Machine learning also inspires many practical solutions that maximize resource utilization and prolong the lifespan of the network. In this paper, we present an extensive literature review over the period 2002-2013 of machine learning methods that were used to address common issues in wireless sensor networks (WSNs). The advantages and disadvantages of each proposed algorithm are evaluated against the corresponding problem. We also provide a comparative guide to aid WSN designers in developing suitable machine learning solutions for their specific application challenges.
* Accepted for publication in IEEE Communications Surveys and Tutorials