 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile Big Data Analytics Using Deep Learning and Apache Spark
Paper and Code
Feb 23, 2016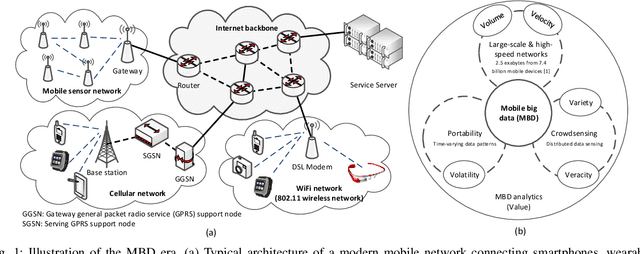
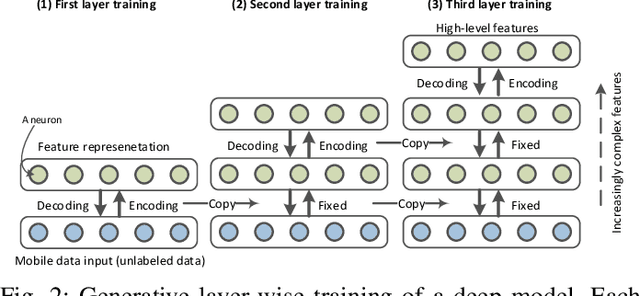
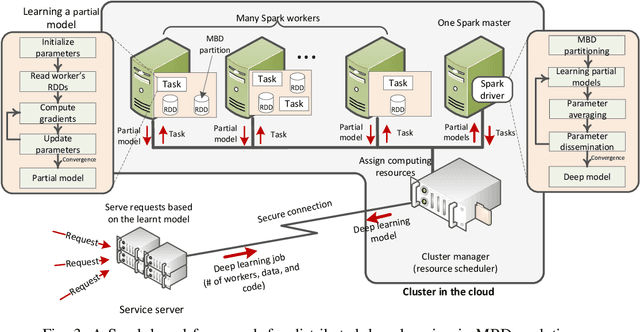
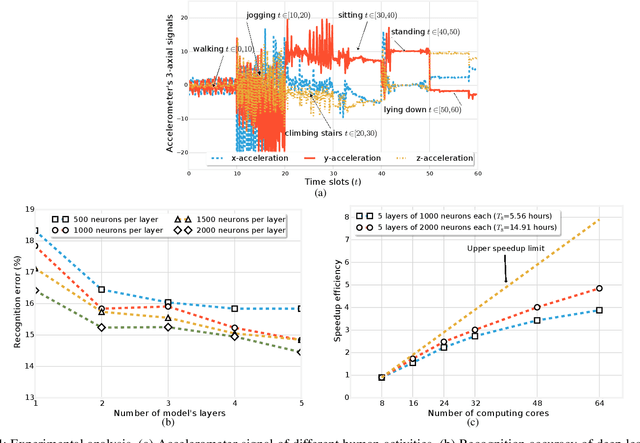
The proliferation of mobile devices, such as smartphones and Internet of Things (IoT) gadgets, results in the recent mobile big data (MBD) era. Collecting MBD is unprofitable unless suitable analytics and learning methods are utilized for extracting meaningful information and hidden patterns from data. This article presents an overview and brief tutorial of deep learning in MBD analytics and discusses a scalable learning framework over Apache Spark. Specifically, a distributed deep learning is executed as an iterative MapReduce computing on many Spark workers. Each Spark worker learns a partial deep model on a partition of the overall MBD, and a master deep model is then built by averaging the parameters of all partial models. This Spark-based framework speeds up the learning of deep models consisting of many hidden layers and millions of parameters. We use a context-aware activity recognition application with a real-world dataset containing millions of samples to validate our framework and assess its speedup effectiveness.