 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA strong baseline for image and video quality assessment
Nov 13, 2021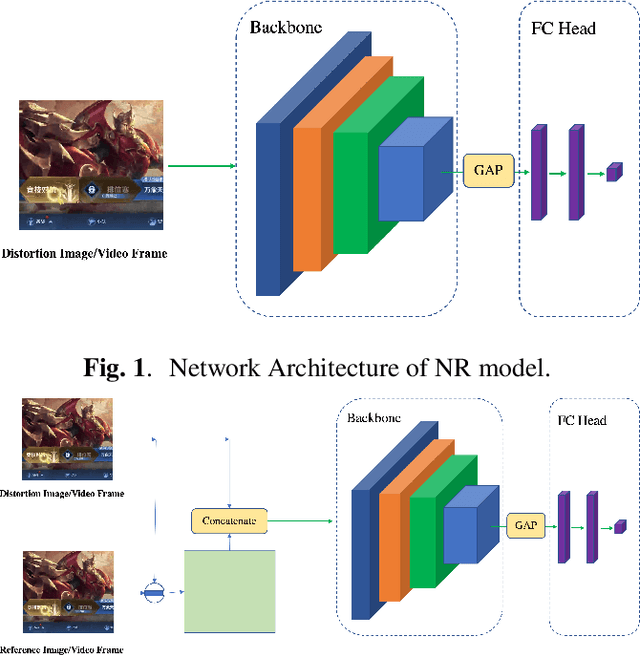


In this work, we present a simple yet effective unified model for perceptual quality assessment of image and video. In contrast to existing models which usually consist of complex network architecture, or rely on the concatenation of multiple branches of features, our model achieves a comparable performance by applying only one global feature derived from a backbone network (i.e. resnet18 in the presented work). Combined with some training tricks, the proposed model surpasses the current baselines of SOTA models on public and private datasets. Based on the architecture proposed, we release the models well trained for three common real-world scenarios: UGC videos in the wild, PGC videos with compression, Game videos with compression. These three pre-trained models can be directly applied for quality assessment, or be further fine-tuned for more customized usages. All the code, SDK, and the pre-trained weights of the proposed models are publicly available at https://github.com/Tencent/CenseoQoE.
Semi-supervised Active Learning for Instance Segmentation via Scoring Predictions
Dec 09, 2020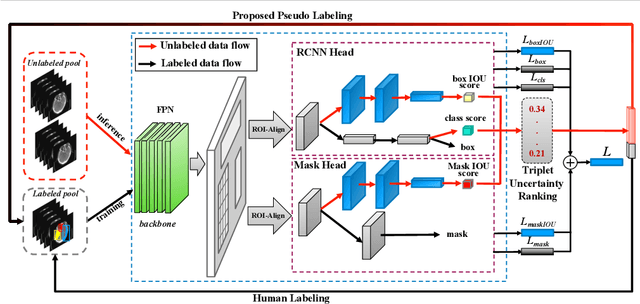
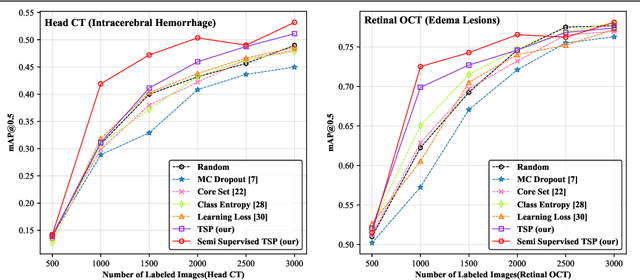
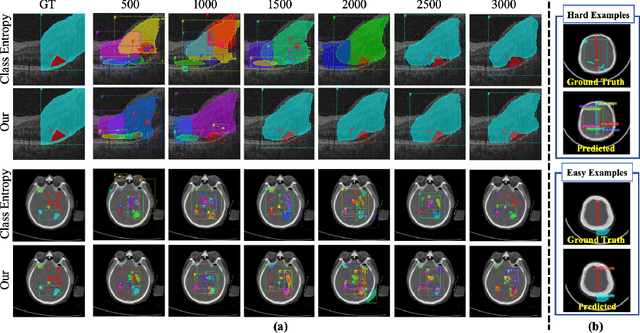
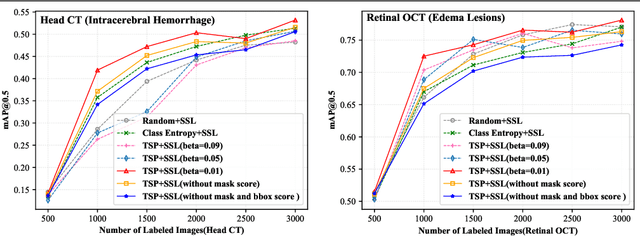
Active learning generally involves querying the most representative samples for human labeling, which has been widely studied in many fields such as image classification and object detection. However, its potential has not been explored in the more complex instance segmentation task that usually has relatively higher annotation cost. In this paper, we propose a novel and principled semi-supervised active learning framework for instance segmentation. Specifically, we present an uncertainty sampling strategy named Triplet Scoring Predictions (TSP) to explicitly incorporate samples ranking clues from classes, bounding boxes and masks. Moreover, we devise a progressive pseudo labeling regime using the above TSP in semi-supervised manner, it can leverage both the labeled and unlabeled data to minimize labeling effort while maximize performance of instance segmentation. Results on medical images datasets demonstrate that the proposed method results in the embodiment of knowledge from available data in a meaningful way. The extensive quantitatively and qualitatively experiments show that, our method can yield the best-performing model with notable less annotation costs, compared with state-of-the-arts.
Weakly Supervised Attention Pyramid Convolutional Neural Network for Fine-Grained Visual Classification
Feb 09, 2020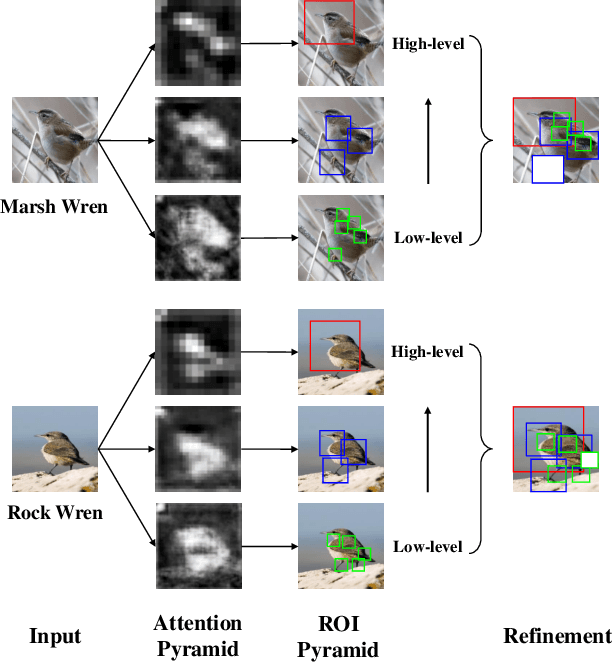
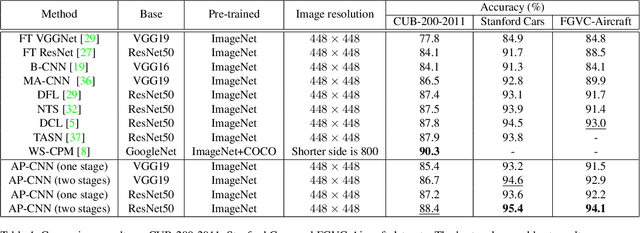
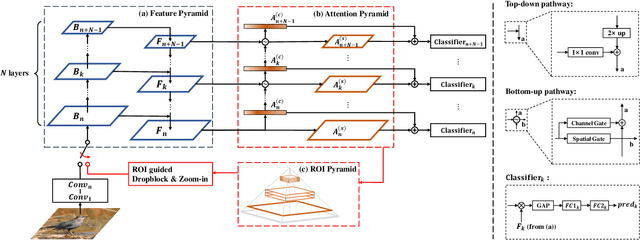

Classifying the sub-categories of an object from the same super-category (e.g. bird species, car and aircraft models) in fine-grained visual classification (FGVC) highly relies on discriminative feature representation and accurate region localization. Existing approaches mainly focus on distilling information from high-level features. In this paper, however, we show that by integrating low-level information (e.g. color, edge junctions, texture patterns), performance can be improved with enhanced feature representation and accurately located discriminative regions. Our solution, named Attention Pyramid Convolutional Neural Network (AP-CNN), consists of a) a pyramidal hierarchy structure with a top-down feature pathway and a bottom-up attention pathway, and hence learns both high-level semantic and low-level detailed feature representation, and b) an ROI guided refinement strategy with ROI guided dropblock and ROI guided zoom-in, which refines features with discriminative local regions enhanced and background noises eliminated. The proposed AP-CNN can be trained end-to-end, without the need of additional bounding box/part annotations. Extensive experiments on three commonly used FGVC datasets (CUB-200-2011, Stanford Cars, and FGVC-Aircraft) demonstrate that our approach can achieve state-of-the-art performance. Code available at \url{http://dwz1.cc/ci8so8a}