 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding of Frequency Dependence on Sound Event Detection
Feb 11, 2025In this work, various analysis methods are conducted on frequency-dependent methods on SED to further delve into their detailed characteristics and behaviors on SED. While SED has been rapidly advancing through the adoption of various deep learning techniques from other pattern recognition fields, these techniques are often not suitable for SED. To address this issue, two frequency-dependent SED methods were previously proposed: FilterAugment, a data augmentation randomly weighting frequency bands, and frequency dynamic convolution (FDY Conv), an architecture applying frequency adaptive convolution kernels. These methods have demonstrated superior performance in SED, and we aim to further analyze their detailed effectiveness and characteristics in SED. We compare class-wise performance to find out specific pros and cons of FilterAugment and FDY Conv. We apply Gradient-weighted Class Activation Mapping (Grad-CAM), which highlights time-frequency region that is more inferred by the model, on SED models with and without frequency masking and two types of FilterAugment to observe their detailed characteristics. We propose simpler frequency dependent convolution methods and compare them with FDY Conv to further understand which components of FDY Conv affects SED performance. Lastly, we apply PCA to show how FDY Conv adapts dynamic kernel across frequency dimensions on different sound event classes. The results and discussions demonstrate that frequency dependency plays a significant role in sound event detection and further confirms the effectiveness of frequency dependent methods on SED.
Diversifying and Expanding Frequency-Adaptive Convolution Kernels for Sound Event Detection
Jun 08, 2024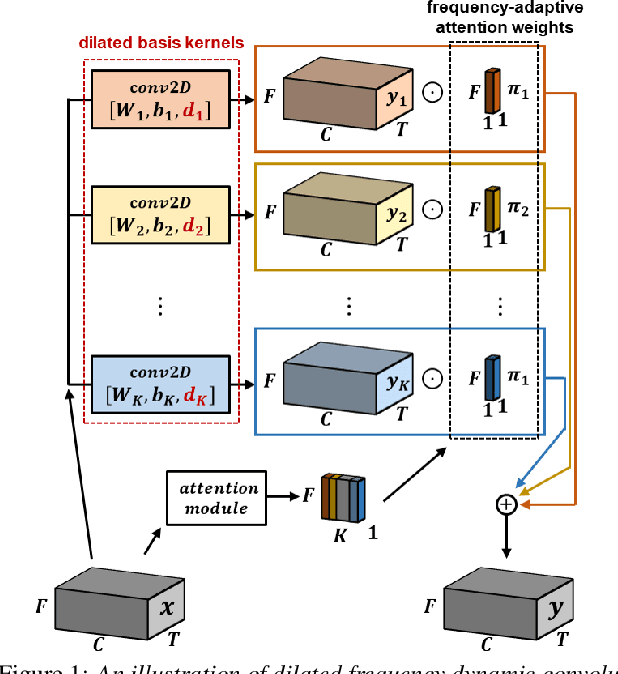
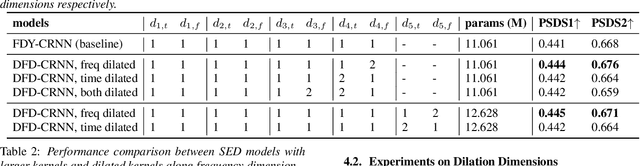


Frequency dynamic convolution (FDY conv) has shown the state-of-the-art performance in sound event detection (SED) using frequency-adaptive kernels obtained by frequency-varying combination of basis kernels. However, FDY conv lacks an explicit mean to diversify frequency-adaptive kernels, potentially limiting the performance. In addition, size of basis kernels is limited while time-frequency patterns span larger spectro-temporal range. Therefore, we propose dilated frequency dynamic convolution (DFD conv) which diversifies and expands frequency-adaptive kernels by introducing different dilation sizes to basis kernels. Experiments showed advantages of varying dilation sizes along frequency dimension, and analysis on attention weight variance proved dilated basis kernels are effectively diversified. By adapting class-wise median filter with intersection-based F1 score, proposed DFD-CRNN outperforms FDY-CRNN by 3.12% in terms of polyphonic sound detection score (PSDS).
Frequency & Channel Attention for computationally efficient sound event detection
Jun 20, 2023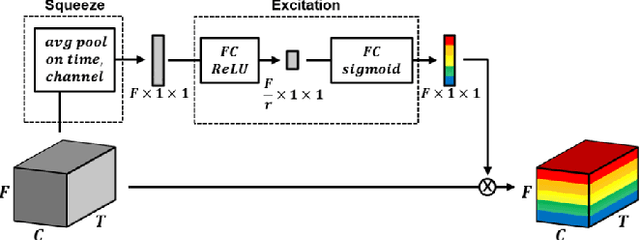



We explore on various attention methods on frequency and channel dimensions for sound event detection (SED) in order to enhance performance with minimal increase in computational cost while leveraging domain knowledge to address the frequency dimension of audio data. We have introduced frequency dynamic convolution in a previous work to release the translational equivariance issue associated with 2D convolution on the frequency dimension of 2D audio data. Although this approach demonstrated state-of-the-art SED performance, it resulted in 2.5 times heavier model in terms of the number of parameters. To achieve comparable SED performance with computationally efficient methods to enhance practicality, we explore on lighter alternative attention methods. In addition, we focus of attention methods on frequency and channel dimensions as those are shown to be critical in SED. Joint application of SE modules on both frequency and channel dimension shows comparable performance to frequency dynamic convolution with only 2.7% increase in the model size compared to the baseline model. In addition, we performed class-wise comparison of various attention methods to further discuss their characteristics.
Data Augmentation and Squeeze-and-Excitation Network on Multiple Dimension for Sound Event Localization and Detection in Real Scenes
Jun 24, 2022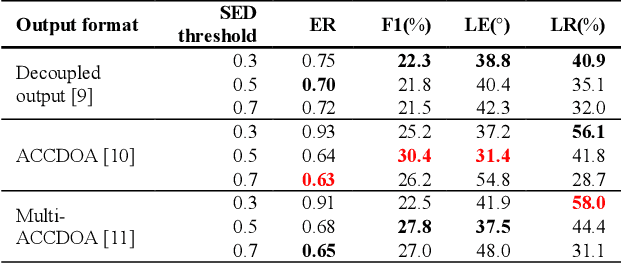
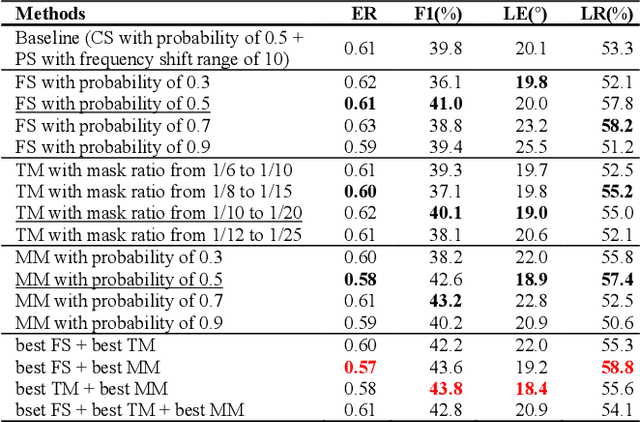
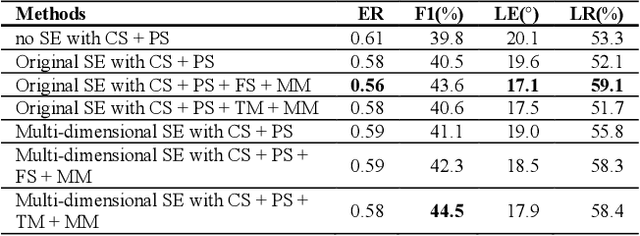
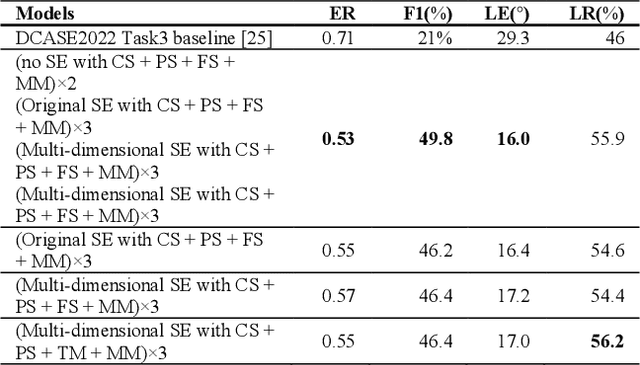
Performance of sound event localization and detection (SELD) in real scenes is limited by small size of SELD dataset, due to difficulty in obtaining sufficient amount of realistic multi-channel audio data recordings with accurate label. We used two main strategies to solve problems arising from the small real SELD dataset. First, we applied various data augmentation methods on all data dimensions: channel, frequency and time. We also propose original data augmentation method named Moderate Mixup in order to simulate situations where noise floor or interfering events exist. Second, we applied Squeeze-and-Excitation block on channel and frequency dimensions to efficiently extract feature characteristics. Result of our trained models on the STARSS22 test dataset achieved the best ER, F1, LE, and LR of 0.53, 49.8%, 16.0deg., and 56.2% respectively.
Frequency Dependent Sound Event Detection for DCASE 2022 Challenge Task 4
Jun 23, 2022
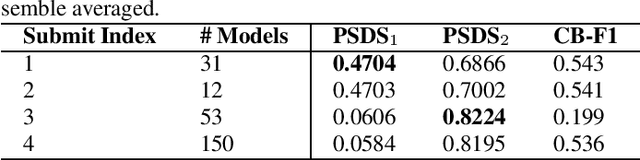
While many deep learning methods on other domains have been applied to sound event detection (SED), differences between original domains of the methods and SED have not been appropriately considered so far. As SED uses audio data with two dimensions (time and frequency) for input, thorough comprehension on these two dimensions is essential for application of methods from other domains on SED. Previous works proved that methods those address on frequency dimension are especially powerful in SED. By applying FilterAugment and frequency dynamic convolution those are frequency dependent methods proposed to enhance SED performance, our submitted models achieved best PSDS1 of 0.4704 and best PSDS2 of 0.8224.
Frequency Dynamic Convolution: Frequency-Adaptive Pattern Recognition for Sound Event Detection
Mar 29, 2022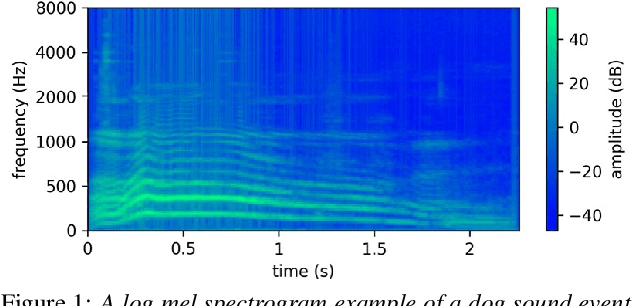
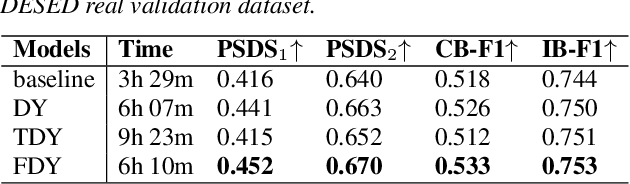
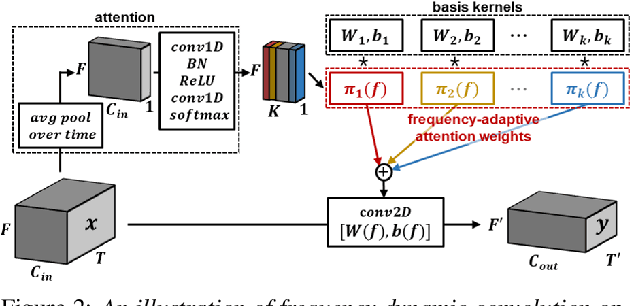
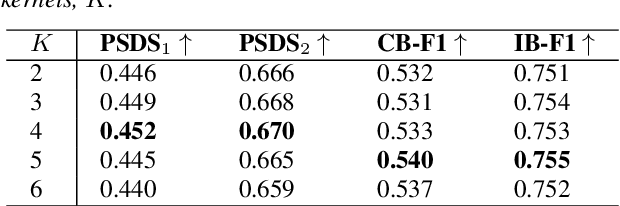
2D convolution is widely used in sound event detection (SED) to recognize 2D patterns of sound events in time-frequency domain. However, 2D convolution enforces translation-invariance on sound events along both time and frequency axis while sound events exhibit frequency-dependent patterns. In order to improve physical inconsistency in 2D convolution on SED, we propose frequency dynamic convolution which applies kernel that adapts to frequency components of input. Frequency dynamic convolution outperforms the baseline model by 6.3% in DESED dataset in terms of polyphonic sound detection score (PSDS). It also significantly outperforms dynamic convolution and temporal dynamic convolution on SED. In addition, by comparing class-wise F1 scores of baseline model and frequency dynamic convolution, we showed that frequency dynamic convolution is especially more effective for detection of non-stationary sound events. From this result, we verified that frequency dynamic convolution is superior in recognizing frequency-dependent patterns as non-stationary sound events show more intricate time-frequency patterns.
Decomposed Temporal Dynamic CNN: Efficient Time-Adaptive Network for Text-Independent Speaker Verification Explained with Speaker Activation Map
Mar 29, 2022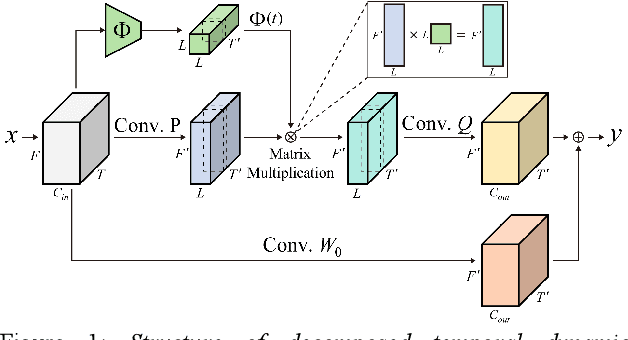

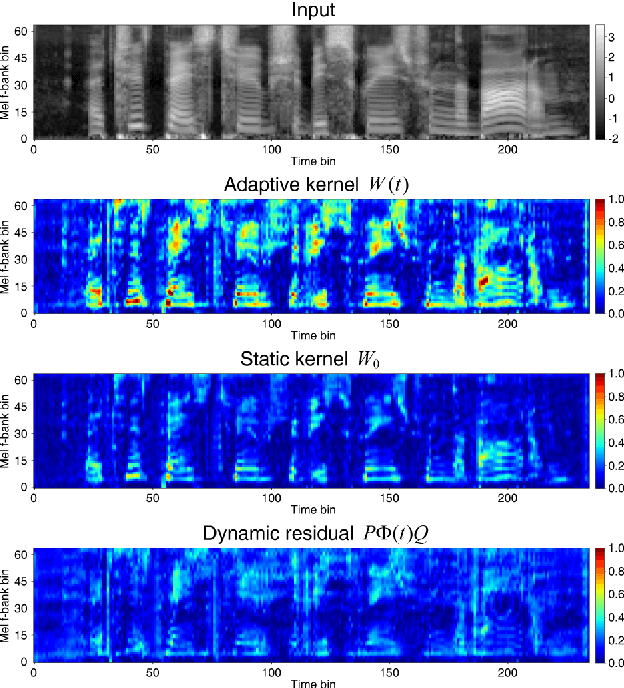
Temporal dynamic models for text-independent speaker verification extract consistent speaker information regardless of phonemes by using temporal dynamic CNN (TDY-CNN) in which kernels adapt to each time bin. However, TDY-CNN shows limitations that the model is too large and does not guarantee the diversity of adaptive kernels. To address these limitations, we propose decomposed temporal dynamic CNN (DTDY-CNN) that makes adaptive kernel by combining static kernel and dynamic residual based on matrix decomposition. The baseline model using DTDY-CNN maintained speaker verification performance while reducing the number of model parameters by 35% compared to the model using TDY-CNN. In addition, detailed behaviors of temporal dynamic models on extraction of speaker information was explained using speaker activation maps (SAM) modified from gradient-weighted class activation mapping (Grad-CAM). In DTDY-CNN, the static kernel activates voiced features of utterances, and the dynamic residual activates unvoiced high-frequency features of phonemes. DTDY-CNN effectively extracts speaker information from not only formant frequencies and harmonics but also detailed unvoiced phonemes' information, thus explaining its outstanding performance on text-independent speaker verification.
FilterAugment: An Acoustic Environmental Data Augmentation Method
Oct 11, 2021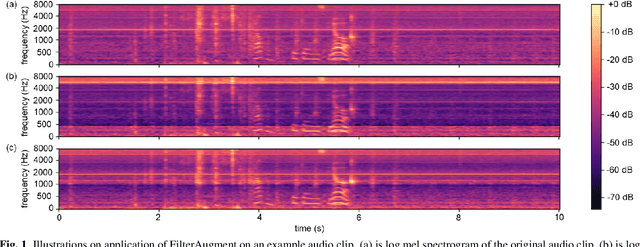
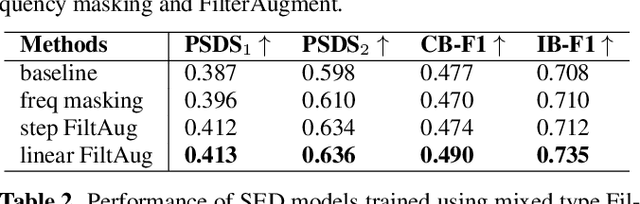
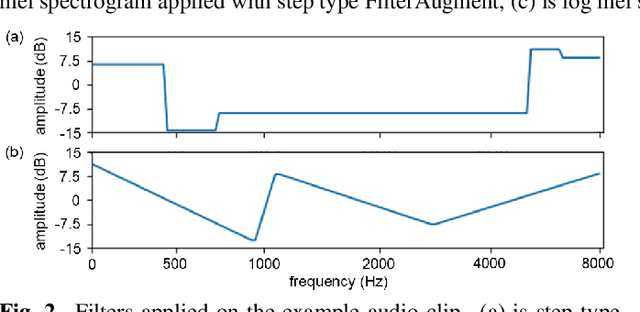
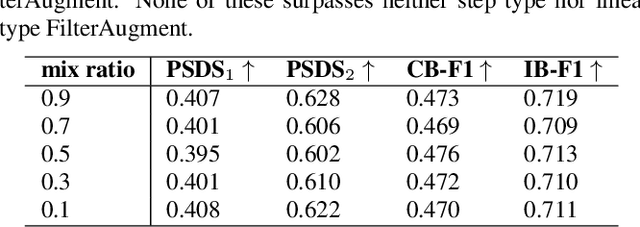
Acoustic environments affect acoustic characteristics of sound to be recognized under physically interaction with sound wave propagation. Thus, training acoustic models for audio and speech tasks requires regularization on various acoustic environments in order to achieve robust performance in real life applications. We propose FilterAugment, a data augmentation method for regularization of acoustic models on various acoustic environments. FilterAugment mimics acoustic filters by applying different weights on frequency bands, therefore enables model to extract relevant information from wider frequency region. It is an improved version of frequency masking which masks information on random frequency bands. FilterAugment improved sound event detection (SED) model performance by 6.50% while frequency masking only improved 2.13% in terms of polyphonic sound detection score (PSDS). It achieved equal error rate (EER) of 1.22% when applied to a text-independent speaker verification model, outperforming model used frequency masking with EER of 1.26%. Prototype of FilterAugment was applied in our participation in DCASE 2021 challenge task 4, and played a major role in achieving the 3rd rank.
Temporal Dynamic Convolutional Neural Network for Text-Independent Speaker Verification and Phonemetic Analysis
Oct 07, 2021
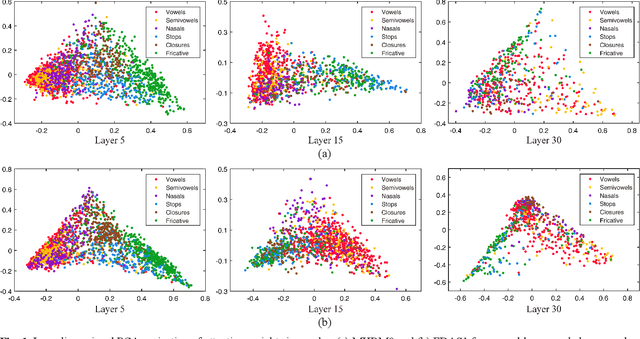


In the field of text-independent speaker recognition, dynamic models that change along the time axis have been proposed to consider the phoneme-varying characteristics of speech. However, detailed analysis on how dynamic models work depending on phonemes is insufficient. In this paper, we propose temporal dynamic CNN (TDY-CNN) that considers temporal variation of phonemes by applying kernels optimally adapt to each time bin. These kernels adapt to time bins by applying weighted sum of trained basis kernels. Then, an analysis on how adaptive kernels work on different phonemes in various layers is carried out. TDY-ResNet-38(x0.5) using six basis kernels shows better speaker verification performance than baseline model ResNet-38(x0.5) does, with an equal error rate (EER) of 1.48%. In addition, we showed that adaptive kernels depend on phoneme groups and more phoneme-specific at early layer. Temporal dynamic model adapts itself to phonemes without explicitly given phoneme information during training, and the results show that the necessity to consider phoneme variation within utterances for more accurate and robust text-independent speaker verification.
Deep learning based cough detection camera using enhanced features
Jul 28, 2021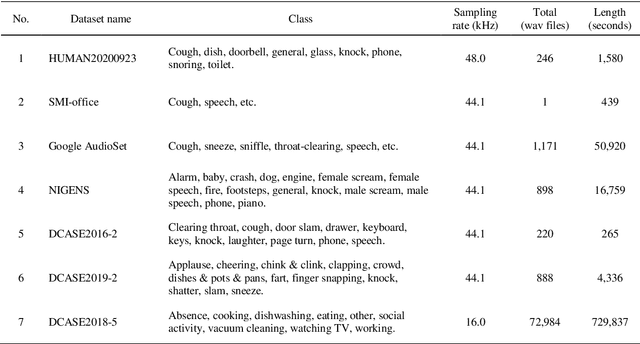
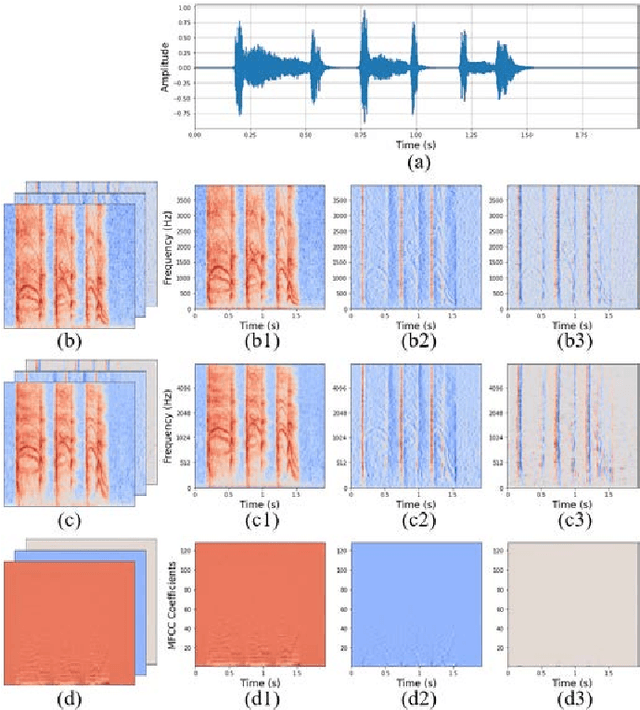

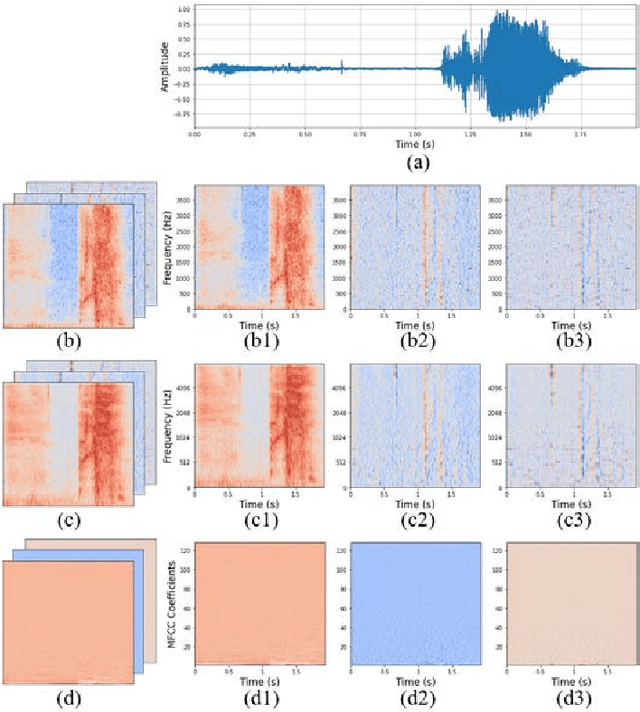
Coughing is a typical symptom of COVID-19. To detect and localize coughing sounds remotely, a convolutional neural network (CNN) based deep learning model was developed in this work and integrated with a sound camera for the visualization of the cough sounds. The cough detection model is a binary classifier of which the input is a two second acoustic feature and the output is one of two inferences (Cough or Others). Data augmentation was performed on the collected audio files to alleviate class imbalance and reflect various background noises in practical environments. For effective featuring of the cough sound, conventional features such as spectrograms, mel-scaled spectrograms, and mel-frequency cepstral coefficients (MFCC) were reinforced by utilizing their velocity (V) and acceleration (A) maps in this work. VGGNet, GoogLeNet, and ResNet were simplified to binary classifiers, and were named V-net, G-net, and R-net, respectively. To find the best combination of features and networks, training was performed for a total of 39 cases and the performance was confirmed using the test F1 score. Finally, a test F1 score of 91.9% (test accuracy of 97.2%) was achieved from G-net with the MFCC-V-A feature (named Spectroflow), an acoustic feature effective for use in cough detection. The trained cough detection model was integrated with a sound camera (i.e., one that visualizes sound sources using a beamforming microphone array). In a pilot test, the cough detection camera detected coughing sounds with an F1 score of 90.0% (accuracy of 96.0%), and the cough location in the camera image was tracked in real time.