 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNN based HRIRs Identification with a Continuously Rotating Speaker Array
Apr 21, 2025Conventional static measurement of head-related impulse responses (HRIRs) is time-consuming due to the need for repositioning a speaker array for each azimuth angle. Dynamic approaches using analytical models with a continuously rotating speaker array have been proposed, but their accuracy is significantly reduced at high rotational speeds. To address this limitation, we propose a DNN-based HRIRs identification using sequence-to-sequence learning. The proposed DNN model incorporates fully connected (FC) networks to effectively capture HRIR transitions and includes reset and update gates to identify HRIRs over a whole sequence. The model updates the HRIRs vector coefficients based on the gradient of the instantaneous square error (ISE). Additionally, we introduce a learnable normalization process based on the speaker excitation signals to stabilize the gradient scale of ISE across time. A training scheme, referred to as whole-sequence updating and optimization scheme, is also introduced to prevent overfitting. We evaluated the proposed method through simulations and experiments. Simulation results using the FABIAN database show that the proposed method outperforms previous analytic models, achieving over 7 dB improvement in normalized misalignment (NM) and maintaining log spectral distortion (LSD) below 2 dB at a rotational speed of 45{\deg}/s. Experimental results with a custom-built speaker array confirm that the proposed method successfully preserved accurate sound localization cues, consistent with those from static measurement. Source code is available at https://github.com/byko0810/DNN-based-HRIRs-identification
Towards Understanding of Frequency Dependence on Sound Event Detection
Feb 11, 2025In this work, various analysis methods are conducted on frequency-dependent methods on SED to further delve into their detailed characteristics and behaviors on SED. While SED has been rapidly advancing through the adoption of various deep learning techniques from other pattern recognition fields, these techniques are often not suitable for SED. To address this issue, two frequency-dependent SED methods were previously proposed: FilterAugment, a data augmentation randomly weighting frequency bands, and frequency dynamic convolution (FDY Conv), an architecture applying frequency adaptive convolution kernels. These methods have demonstrated superior performance in SED, and we aim to further analyze their detailed effectiveness and characteristics in SED. We compare class-wise performance to find out specific pros and cons of FilterAugment and FDY Conv. We apply Gradient-weighted Class Activation Mapping (Grad-CAM), which highlights time-frequency region that is more inferred by the model, on SED models with and without frequency masking and two types of FilterAugment to observe their detailed characteristics. We propose simpler frequency dependent convolution methods and compare them with FDY Conv to further understand which components of FDY Conv affects SED performance. Lastly, we apply PCA to show how FDY Conv adapts dynamic kernel across frequency dimensions on different sound event classes. The results and discussions demonstrate that frequency dependency plays a significant role in sound event detection and further confirms the effectiveness of frequency dependent methods on SED.
Self Training and Ensembling Frequency Dependent Networks with Coarse Prediction Pooling and Sound Event Bounding Boxes
Jun 22, 2024To tackle sound event detection (SED) task, we propose frequency dependent networks (FreDNets), which heavily leverage frequency-dependent methods. We apply frequency warping and FilterAugment, which are frequency-dependent data augmentation methods. The model architecture consists of 3 branches: audio teacher-student transformer (ATST) branch, BEATs branch and CNN branch including either partial dilated frequency dynamic convolution (PDFD) or squeeze-and-Excitation (SE) with time-frame frequency-wise SE (tfwSE). To train MAESTRO labels with coarse temporal resolution, we apply max pooling on prediction for the MAESTRO dataset. Using best ensemble model, we apply self training to obtain pseudo label from DESED weak set, DESED unlabeled set and AudioSet. AudioSet labels are filtered to focus on high-confidence pseudo labels and AudioSet pseudo labels are used to train on DESED labels only. We used change-detection-based sound event bounding boxes (cSEBBs) as post processing for ensemble models on self training and submission models.
Diversifying and Expanding Frequency-Adaptive Convolution Kernels for Sound Event Detection
Jun 08, 2024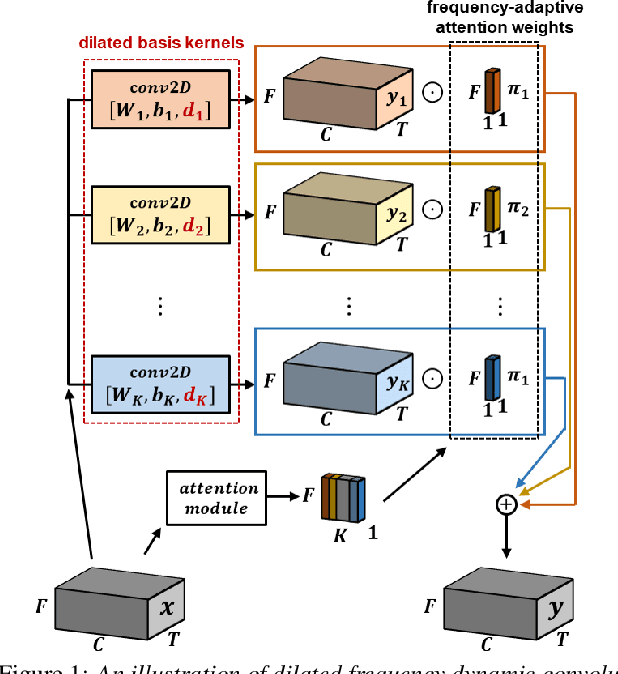
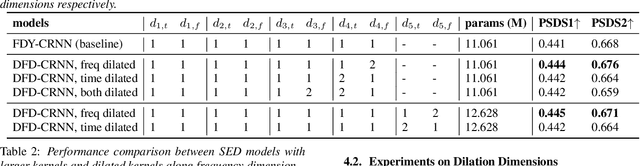


Frequency dynamic convolution (FDY conv) has shown the state-of-the-art performance in sound event detection (SED) using frequency-adaptive kernels obtained by frequency-varying combination of basis kernels. However, FDY conv lacks an explicit mean to diversify frequency-adaptive kernels, potentially limiting the performance. In addition, size of basis kernels is limited while time-frequency patterns span larger spectro-temporal range. Therefore, we propose dilated frequency dynamic convolution (DFD conv) which diversifies and expands frequency-adaptive kernels by introducing different dilation sizes to basis kernels. Experiments showed advantages of varying dilation sizes along frequency dimension, and analysis on attention weight variance proved dilated basis kernels are effectively diversified. By adapting class-wise median filter with intersection-based F1 score, proposed DFD-CRNN outperforms FDY-CRNN by 3.12% in terms of polyphonic sound detection score (PSDS).
Auditory Neural Response Inspired Sound Event Detection Based on Spectro-temporal Receptive Field
Jun 20, 2023Sound event detection (SED) is one of tasks to automate function by human auditory system which listens and understands auditory scenes. Therefore, we were inspired to make SED recognize sound events in the way human auditory system does. Spectro-temporal receptive field (STRF), an approach to describe the relationship between perceived sound at ear and transformed neural response in the auditory cortex, is closely related to recognition of sound. In this work, we utilized STRF as a kernel of the first convolutional layer in SED model to extract neural response from input sound to make SED model similar to human auditory system. In addition, we constructed two-branched SED model named as Two Branch STRFNet (TB-STRFNet) composed of STRF branch and baseline branch. While STRF branch extracts sound event information from auditory neural response, baseline branch extracts sound event information directly from the mel spectrogram just as conventional SED models do. TB-STRFNet outperformed the DCASE baseline by 4.3% in terms of threshold-independent macro F1 score, achieving 4th rank in DCASE Challenge 2023 Task 4b. We further improved TB-STRFNet by applying frequency dynamic convolution (FDYConv) which also leveraged domain knowledge on acoustics. As a result, two branch model applied with FDYConv on both branches outperformed the DCASE baseline by 6.2% in terms of the same metric.
Frequency & Channel Attention for computationally efficient sound event detection
Jun 20, 2023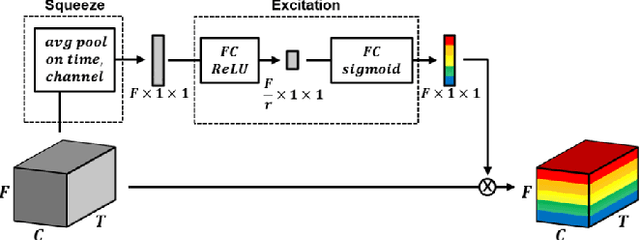



We explore on various attention methods on frequency and channel dimensions for sound event detection (SED) in order to enhance performance with minimal increase in computational cost while leveraging domain knowledge to address the frequency dimension of audio data. We have introduced frequency dynamic convolution in a previous work to release the translational equivariance issue associated with 2D convolution on the frequency dimension of 2D audio data. Although this approach demonstrated state-of-the-art SED performance, it resulted in 2.5 times heavier model in terms of the number of parameters. To achieve comparable SED performance with computationally efficient methods to enhance practicality, we explore on lighter alternative attention methods. In addition, we focus of attention methods on frequency and channel dimensions as those are shown to be critical in SED. Joint application of SE modules on both frequency and channel dimension shows comparable performance to frequency dynamic convolution with only 2.7% increase in the model size compared to the baseline model. In addition, we performed class-wise comparison of various attention methods to further discuss their characteristics.
Data Augmentation and Squeeze-and-Excitation Network on Multiple Dimension for Sound Event Localization and Detection in Real Scenes
Jun 24, 2022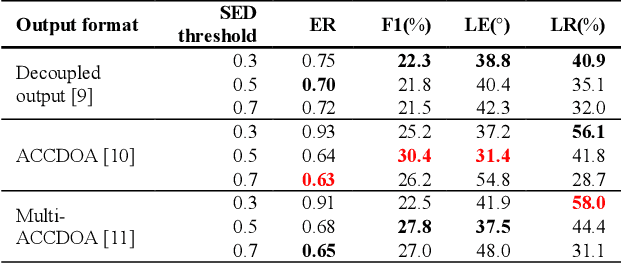
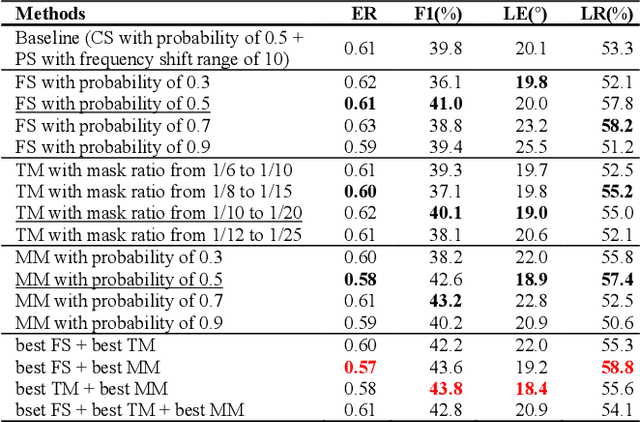
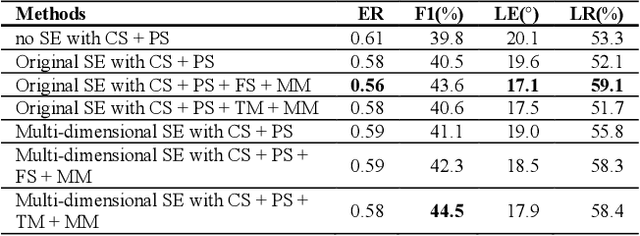
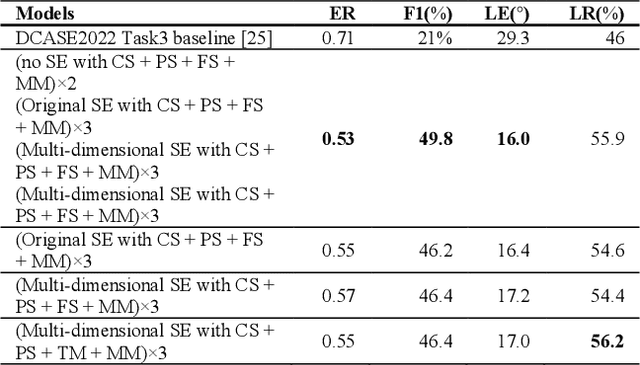
Performance of sound event localization and detection (SELD) in real scenes is limited by small size of SELD dataset, due to difficulty in obtaining sufficient amount of realistic multi-channel audio data recordings with accurate label. We used two main strategies to solve problems arising from the small real SELD dataset. First, we applied various data augmentation methods on all data dimensions: channel, frequency and time. We also propose original data augmentation method named Moderate Mixup in order to simulate situations where noise floor or interfering events exist. Second, we applied Squeeze-and-Excitation block on channel and frequency dimensions to efficiently extract feature characteristics. Result of our trained models on the STARSS22 test dataset achieved the best ER, F1, LE, and LR of 0.53, 49.8%, 16.0deg., and 56.2% respectively.
Frequency Dependent Sound Event Detection for DCASE 2022 Challenge Task 4
Jun 23, 2022
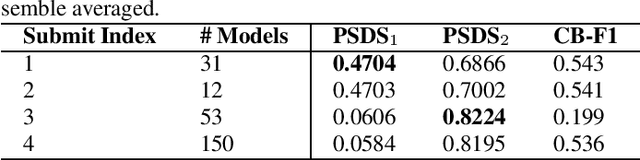
While many deep learning methods on other domains have been applied to sound event detection (SED), differences between original domains of the methods and SED have not been appropriately considered so far. As SED uses audio data with two dimensions (time and frequency) for input, thorough comprehension on these two dimensions is essential for application of methods from other domains on SED. Previous works proved that methods those address on frequency dimension are especially powerful in SED. By applying FilterAugment and frequency dynamic convolution those are frequency dependent methods proposed to enhance SED performance, our submitted models achieved best PSDS1 of 0.4704 and best PSDS2 of 0.8224.