 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation and Squeeze-and-Excitation Network on Multiple Dimension for Sound Event Localization and Detection in Real Scenes
Paper and Code
Jun 24, 2022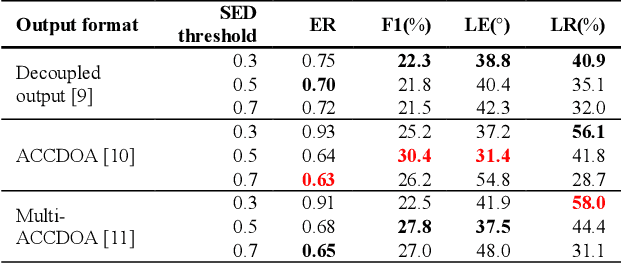
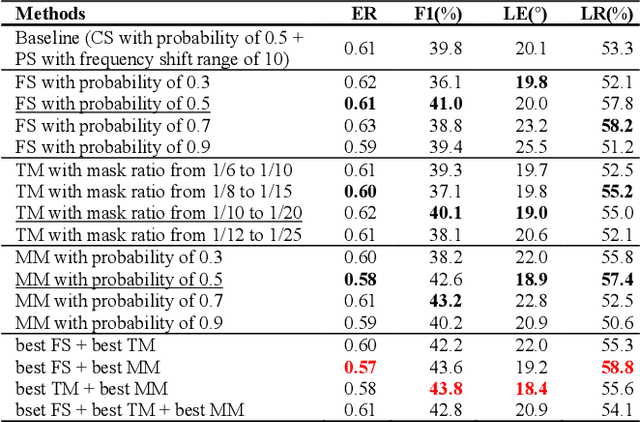
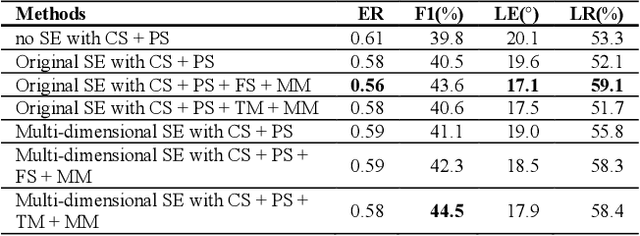
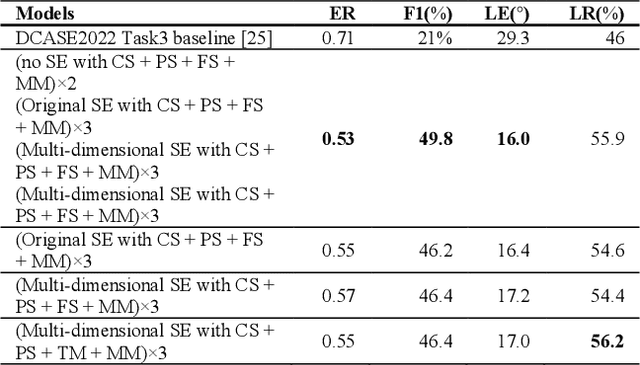
Performance of sound event localization and detection (SELD) in real scenes is limited by small size of SELD dataset, due to difficulty in obtaining sufficient amount of realistic multi-channel audio data recordings with accurate label. We used two main strategies to solve problems arising from the small real SELD dataset. First, we applied various data augmentation methods on all data dimensions: channel, frequency and time. We also propose original data augmentation method named Moderate Mixup in order to simulate situations where noise floor or interfering events exist. Second, we applied Squeeze-and-Excitation block on channel and frequency dimensions to efficiently extract feature characteristics. Result of our trained models on the STARSS22 test dataset achieved the best ER, F1, LE, and LR of 0.53, 49.8%, 16.0deg., and 56.2% respectively.