 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditory Intelligence: Understanding the World Through Sound
Aug 11, 2025Recent progress in auditory intelligence has yielded high-performing systems for sound event detection (SED), acoustic scene classification (ASC), automated audio captioning (AAC), and audio question answering (AQA). Yet these tasks remain largely constrained to surface-level recognition-capturing what happened but not why, what it implies, or how it unfolds in context. I propose a conceptual reframing of auditory intelligence as a layered, situated process that encompasses perception, reasoning, and interaction. To instantiate this view, I introduce four cognitively inspired task paradigms-ASPIRE, SODA, AUX, and AUGMENT-those structure auditory understanding across time-frequency pattern captioning, hierarchical event/scene description, causal explanation, and goal-driven interpretation, respectively. Together, these paradigms provide a roadmap toward more generalizable, explainable, and human-aligned auditory intelligence, and are intended to catalyze a broader discussion of what it means for machines to understand sound.
Binaural Sound Event Localization and Detection based on HRTF Cues for Humanoid Robots
Jul 28, 2025This paper introduces Binaural Sound Event Localization and Detection (BiSELD), a task that aims to jointly detect and localize multiple sound events using binaural audio, inspired by the spatial hearing mechanism of humans. To support this task, we present a synthetic benchmark dataset, called the Binaural Set, which simulates realistic auditory scenes using measured head-related transfer functions (HRTFs) and diverse sound events. To effectively address the BiSELD task, we propose a new input feature representation called the Binaural Time-Frequency Feature (BTFF), which encodes interaural time difference (ITD), interaural level difference (ILD), and high-frequency spectral cues (SC) from binaural signals. BTFF is composed of eight channels, including left and right mel-spectrograms, velocity-maps, SC-maps, and ITD-/ILD-maps, designed to cover different spatial cues across frequency bands and spatial axes. A CRNN-based model, BiSELDnet, is then developed to learn both spectro-temporal patterns and HRTF-based localization cues from BTFF. Experiments on the Binaural Set show that each BTFF sub-feature enhances task performance: V-map improves detection, ITD-/ILD-maps enable accurate horizontal localization, and SC-map captures vertical spatial cues. The final system achieves a SELD error of 0.110 with 87.1% F-score and 4.4{\deg} localization error, demonstrating the effectiveness of the proposed framework in mimicking human-like auditory perception.
Frequency Dynamic Convolutions for Sound Event Detection
Jun 15, 2025Recent research in deep learning-based Sound Event Detection (SED) has primarily focused on Convolutional Recurrent Neural Networks (CRNNs) and Transformer models. However, conventional 2D convolution-based models assume shift invariance along both the temporal and frequency axes, leadin to inconsistencies when dealing with frequency-dependent characteristics of acoustic signals. To address this issue, this study proposes Frequency Dynamic Convolution (FDY conv), which dynamically adjusts convolutional kernels based on the frequency composition of the input signal to enhance SED performance. FDY conv constructs an optimal frequency response by adaptively weighting multiple basis kernels based on frequency-specific attention weights. Experimental results show that applying FDY conv to CRNNs improves performance on the DESED dataset by 7.56% compared to the baseline CRNN. However, FDY conv has limitations in that it combines basis kernels of the same shape across all frequencies, restricting its ability to capture diverse frequency-specific characteristics. Additionally, the $3\times3$ basis kernel size is insufficient to capture a broader frequency range. To overcome these limitations, this study introduces an extended family of FDY conv models. Dilated FDY conv (DFD conv) applies convolutional kernels with various dilation rates to expand the receptive field along the frequency axis and enhance frequency-specific feature representation. Experimental results show that DFD conv improves performance by 9.27% over the baseline. Partial FDY conv (PFD conv) addresses the high computational cost of FDY conv, which results from performing all convolution operations with dynamic kernels. Since FDY conv may introduce unnecessary adaptivity for quasi-stationary sound events, PFD conv integrates standard 2D convolutions with frequency-adaptive kernels to reduce computational complexity while maintaining performance. Experimental results demonstrate that PFD conv improves performance by 7.80% over the baseline while reducing the number of parameters by 54.4% compared to FDY conv. Multi-Dilated FDY conv (MDFD conv) extends DFD conv by addressing its structural limitation of applying the same dilation across all frequencies. By utilizing multiple convolutional kernels with different dilation rates, MDFD conv effectively captures diverse frequency-dependent patterns. Experimental results indicate that MDFD conv achieves the highest performance, improving the baseline CRNN performance by 10.98%. Furthermore, standard FDY conv employs Temporal Average Pooling, which assigns equal weight to all frames along the time axis, limiting its ability to effectively capture transient events. To overcome this, this study proposes TAP-FDY conv (TFD conv), which integrates Temporal Attention Pooling (TA) that focuses on salient features, Velocity Attention Pooling (VA) that emphasizes transient characteristics, and Average Pooling (AP) that captures stationary properties. TAP-FDY conv achieves the same performance as MDFD conv but reduces the number of parameters by approximately 30.01% (12.703M vs. 18.157M), achieving equivalent accuracy with lower computational complexity. Class-wise performance analysis reveals that FDY conv improves detection of non-stationary events, DFD conv is particularly effective for events with broad spectral features, and PFD conv enhances the detection of quasi-stationary events. Additionally, TFD conv (TFD-CRNN) demonstrates strong performance in detecting transient events. In the case studies, PFD conv effectively captures stable signal patterns in tank powertrain fault recognition, DFD conv recognizes wide harmonic spectral patterns on speed-varying motor fault recognition, while TFD conv outperforms other models in detecting transient signals in offshore arc detection. These results suggest that frequency-adaptive convolutions and their extended variants provide a robust alternative to conventional 2D convolutions in deep learning-based audio processing.
DNN based HRIRs Identification with a Continuously Rotating Speaker Array
Apr 21, 2025Conventional static measurement of head-related impulse responses (HRIRs) is time-consuming due to the need for repositioning a speaker array for each azimuth angle. Dynamic approaches using analytical models with a continuously rotating speaker array have been proposed, but their accuracy is significantly reduced at high rotational speeds. To address this limitation, we propose a DNN-based HRIRs identification using sequence-to-sequence learning. The proposed DNN model incorporates fully connected (FC) networks to effectively capture HRIR transitions and includes reset and update gates to identify HRIRs over a whole sequence. The model updates the HRIRs vector coefficients based on the gradient of the instantaneous square error (ISE). Additionally, we introduce a learnable normalization process based on the speaker excitation signals to stabilize the gradient scale of ISE across time. A training scheme, referred to as whole-sequence updating and optimization scheme, is also introduced to prevent overfitting. We evaluated the proposed method through simulations and experiments. Simulation results using the FABIAN database show that the proposed method outperforms previous analytic models, achieving over 7 dB improvement in normalized misalignment (NM) and maintaining log spectral distortion (LSD) below 2 dB at a rotational speed of 45{\deg}/s. Experimental results with a custom-built speaker array confirm that the proposed method successfully preserved accurate sound localization cues, consistent with those from static measurement. Source code is available at https://github.com/byko0810/DNN-based-HRIRs-identification
Temporal Attention Pooling for Frequency Dynamic Convolution in Sound Event Detection
Apr 17, 2025Recent advances in deep learning, particularly frequency dynamic convolution (FDY conv), have significantly improved sound event detection (SED) by enabling frequency-adaptive feature extraction. However, FDY conv relies on temporal average pooling, which treats all temporal frames equally, limiting its ability to capture transient sound events such as alarm bells, door knocks, and speech plosives. To address this limitation, we propose temporal attention pooling frequency dynamic convolution (TFD conv) to replace temporal average pooling with temporal attention pooling (TAP). TAP adaptively weights temporal features through three complementary mechanisms: time attention pooling (TA) for emphasizing salient features, velocity attention pooling (VA) for capturing transient changes, and conventional average pooling for robustness to stationary signals. Ablation studies show that TFD conv improves average PSDS1 by 3.02% over FDY conv with only a 14.8% increase in parameter count. Classwise ANOVA and Tukey HSD analysis further demonstrate that TFD conv significantly enhances detection performance for transient-heavy events, outperforming existing FDY conv models. Notably, TFD conv achieves a maximum PSDS1 score of 0.456, surpassing previous state-of-the-art SED systems. We also explore the compatibility of TAP with other FDY conv variants, including dilated FDY conv (DFD conv), partial FDY conv (PFD conv), and multi-dilated FDY conv (MDFD conv). Among these, the integration of TAP with MDFD conv achieves the best result with a PSDS1 score of 0.459, validating the complementary strengths of temporal attention and multi-scale frequency adaptation. These findings establish TFD conv as a powerful and generalizable framework for enhancing both transient sensitivity and overall feature robustness in SED.
JiTTER: Jigsaw Temporal Transformer for Event Reconstruction for Self-Supervised Sound Event Detection
Feb 28, 2025Sound event detection (SED) has significantly benefited from self-supervised learning (SSL) approaches, particularly masked audio transformer for SED (MAT-SED), which leverages masked block prediction to reconstruct missing audio segments. However, while effective in capturing global dependencies, masked block prediction disrupts transient sound events and lacks explicit enforcement of temporal order, making it less suitable for fine-grained event boundary detection. To address these limitations, we propose JiTTER (Jigsaw Temporal Transformer for Event Reconstruction), an SSL framework designed to enhance temporal modeling in transformer-based SED. JiTTER introduces a hierarchical temporal shuffle reconstruction strategy, where audio sequences are randomly shuffled at both the block-level and frame-level, forcing the model to reconstruct the correct temporal order. This pretraining objective encourages the model to learn both global event structures and fine-grained transient details, improving its ability to detect events with sharp onset-offset characteristics. Additionally, we incorporate noise injection during block shuffle, providing a subtle perturbation mechanism that further regularizes feature learning and enhances model robustness. Experimental results on the DESED dataset demonstrate that JiTTER outperforms MAT-SED, achieving a 5.89% improvement in PSDS, highlighting the effectiveness of explicit temporal reasoning in SSL-based SED. Our findings suggest that structured temporal reconstruction tasks, rather than simple masked prediction, offer a more effective pretraining paradigm for sound event representation learning.
Towards Understanding of Frequency Dependence on Sound Event Detection
Feb 11, 2025In this work, various analysis methods are conducted on frequency-dependent methods on SED to further delve into their detailed characteristics and behaviors on SED. While SED has been rapidly advancing through the adoption of various deep learning techniques from other pattern recognition fields, these techniques are often not suitable for SED. To address this issue, two frequency-dependent SED methods were previously proposed: FilterAugment, a data augmentation randomly weighting frequency bands, and frequency dynamic convolution (FDY Conv), an architecture applying frequency adaptive convolution kernels. These methods have demonstrated superior performance in SED, and we aim to further analyze their detailed effectiveness and characteristics in SED. We compare class-wise performance to find out specific pros and cons of FilterAugment and FDY Conv. We apply Gradient-weighted Class Activation Mapping (Grad-CAM), which highlights time-frequency region that is more inferred by the model, on SED models with and without frequency masking and two types of FilterAugment to observe their detailed characteristics. We propose simpler frequency dependent convolution methods and compare them with FDY Conv to further understand which components of FDY Conv affects SED performance. Lastly, we apply PCA to show how FDY Conv adapts dynamic kernel across frequency dimensions on different sound event classes. The results and discussions demonstrate that frequency dependency plays a significant role in sound event detection and further confirms the effectiveness of frequency dependent methods on SED.
Self Training and Ensembling Frequency Dependent Networks with Coarse Prediction Pooling and Sound Event Bounding Boxes
Jun 22, 2024To tackle sound event detection (SED) task, we propose frequency dependent networks (FreDNets), which heavily leverage frequency-dependent methods. We apply frequency warping and FilterAugment, which are frequency-dependent data augmentation methods. The model architecture consists of 3 branches: audio teacher-student transformer (ATST) branch, BEATs branch and CNN branch including either partial dilated frequency dynamic convolution (PDFD) or squeeze-and-Excitation (SE) with time-frame frequency-wise SE (tfwSE). To train MAESTRO labels with coarse temporal resolution, we apply max pooling on prediction for the MAESTRO dataset. Using best ensemble model, we apply self training to obtain pseudo label from DESED weak set, DESED unlabeled set and AudioSet. AudioSet labels are filtered to focus on high-confidence pseudo labels and AudioSet pseudo labels are used to train on DESED labels only. We used change-detection-based sound event bounding boxes (cSEBBs) as post processing for ensemble models on self training and submission models.
Pushing the Limit of Sound Event Detection with Multi-Dilated Frequency Dynamic Convolution
Jun 19, 2024Frequency dynamic convolution (FDY conv) has been a milestone in the sound event detection (SED) field, but it involves a substantial increase in model size due to multiple basis kernels. In this work, we propose partial frequency dynamic convolution (PFD conv), which concatenates static conventional 2D convolution branch output and dynamic FDY conv branch output in order to minimize model size increase while maintaining the performance. Additionally, we propose multi-dilated frequency dynamic convolution (MDFD conv), which integrates multiple dilated frequency dynamic convolution (DFD conv) branches with different dilation size sets and a static branch within a single convolution module, achieving a 3.2% improvement in polyphonic sound detection score (PSDS) over FDY conv. Proposed methods with extensive ablation studies further enhance understanding and usability of FDY conv variants.
Diversifying and Expanding Frequency-Adaptive Convolution Kernels for Sound Event Detection
Jun 08, 2024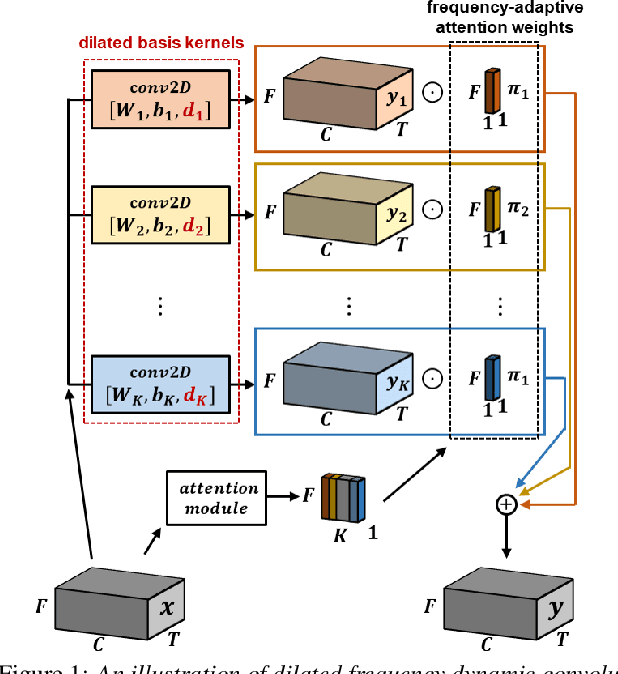
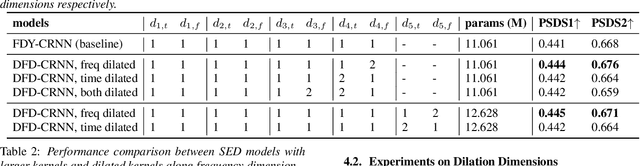


Frequency dynamic convolution (FDY conv) has shown the state-of-the-art performance in sound event detection (SED) using frequency-adaptive kernels obtained by frequency-varying combination of basis kernels. However, FDY conv lacks an explicit mean to diversify frequency-adaptive kernels, potentially limiting the performance. In addition, size of basis kernels is limited while time-frequency patterns span larger spectro-temporal range. Therefore, we propose dilated frequency dynamic convolution (DFD conv) which diversifies and expands frequency-adaptive kernels by introducing different dilation sizes to basis kernels. Experiments showed advantages of varying dilation sizes along frequency dimension, and analysis on attention weight variance proved dilated basis kernels are effectively diversified. By adapting class-wise median filter with intersection-based F1 score, proposed DFD-CRNN outperforms FDY-CRNN by 3.12% in terms of polyphonic sound detection score (PSDS).