 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency & Channel Attention for computationally efficient sound event detection
Paper and Code
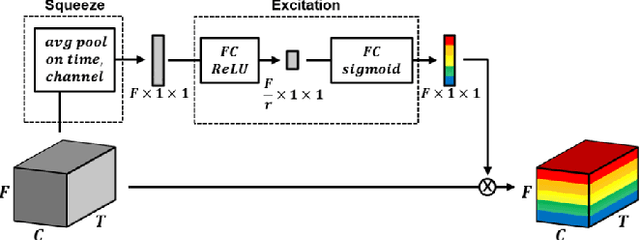



We explore on various attention methods on frequency and channel dimensions for sound event detection (SED) in order to enhance performance with minimal increase in computational cost while leveraging domain knowledge to address the frequency dimension of audio data. We have introduced frequency dynamic convolution in a previous work to release the translational equivariance issue associated with 2D convolution on the frequency dimension of 2D audio data. Although this approach demonstrated state-of-the-art SED performance, it resulted in 2.5 times heavier model in terms of the number of parameters. To achieve comparable SED performance with computationally efficient methods to enhance practicality, we explore on lighter alternative attention methods. In addition, we focus of attention methods on frequency and channel dimensions as those are shown to be critical in SED. Joint application of SE modules on both frequency and channel dimension shows comparable performance to frequency dynamic convolution with only 2.7% increase in the model size compared to the baseline model. In addition, we performed class-wise comparison of various attention methods to further discuss their characteristics.